题目地址
翻了翻提交记录又回忆起了这道题。
一开始20分的原因:
只有当前这条边的最短路能更新(dis)数组的时候,计数器(疲劳值)才能更新。
改掉这个傻逼错误之后,就有80分了。
80分的原因((hack)数据):
来看一组样例:
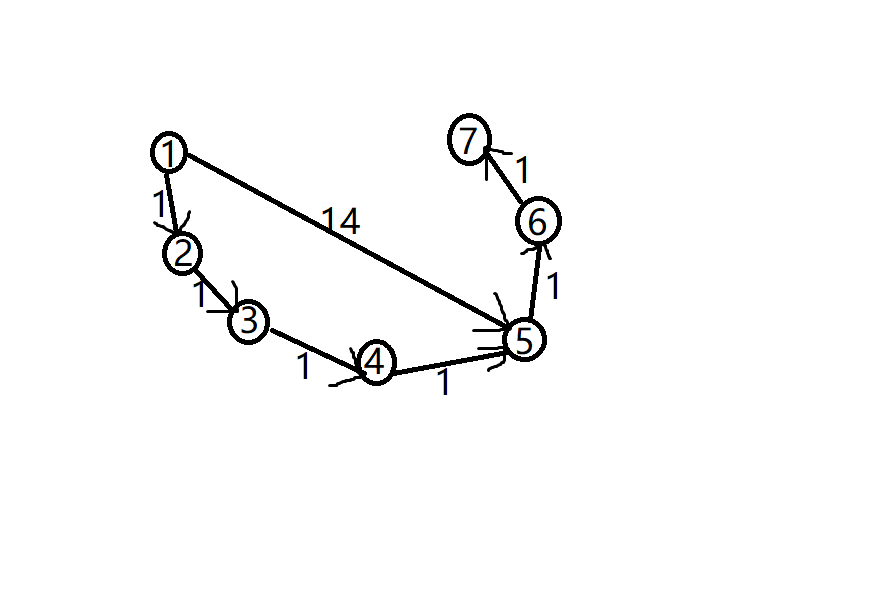
正确答案是19,走14那条边。
事实上输出的最短路长度也是19,只是输出的路径不对。
为什么呢?
最开始肯定是结点1先进队,然后会扩展出2号和5号结点,这时5号节点的(pre)记录了1。然后2号节点一直往后扩展,再次扩展到了5号节点(在这个过程中6,7号节点会被5号节点扩展出来,所以求出了正确的最短路径长度)。如果只看从1到5的路径的话,走2号节点那条路是比较优的。所以此时5号节点的(pre)会被修改成4。但是之后6,7号的最短路不会再被5号节点更新了。
错误原因分析完毕。
然后来看(AC)避免这个问题的原因:
(当然是抄题解的啦)
正解记录的东西比较多,(last[i])记录的是(i)这个点的被更新成最短路时在队列中的位置(只用到了(n)的)。结构体的数组分别记录了节点的编号,目前到这个点的最短路、时间戳、前驱,之后可能还会进队,还会被更新。
就像样例中,虽然现在能被更新,但继续往下走不一定更优。(AC)代码中之前暂时不优的数据没有被覆盖掉,而80分的代码中这个数据就被覆盖掉了。
关于(Hawking)_(llfz) 92分的代码:
他的做法是先用一个数组暂存当前的前驱,当更新到(n)结点时,将暂存前驱的数组转移到最终要输出的数组中。这样做上面的那个样例是正确的。但是讨论版里第一个数据是过不了的。两个样例的区别在于当(n)结点的正确答案被更新到时,错误答案还没有更新到像上边样例的5号节点那里。这样的话最终要输出的数组会存好正确的答案,而以后不会再被更新了。
但是当错误答案还没有更新到像上边样例的5号节点那里,但(n)结点的正确答案还没被更新到时,就又会出错了。
80分代码:
#include<cstdio>
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
struct edge{
int node,next,data;
}e[200005];
queue<int> q;
int n,m,tot;
int pre[10005],num[10005],dis[10005],head[10005];
bool b[10005];
void add(int x,int y,int z)
{
e[++tot].node=y;e[tot].next=head[x];
e[tot].data=z; head[x]=tot;
}
void print(int u)
{
if(pre[u]==u)
{
printf("%d ",u);
return ;
}
print(pre[u]);
printf("%d ",u);
}
void spfa(int s)
{
q.push(s); dis[s]=0;
b[s]=1; num[s]=0;
for(int i=1;i<=n;i++)
pre[i]=i;
while(!q.empty())
{
int u=q.front();
q.pop(); b[u]=0;
for(int i=head[u];i;i=e[i].next )
{
int v=e[i].node ;
if(dis[v]>dis[u]+e[i].data +num[u])
{
dis[v]=dis[u]+e[i].data +num[u];
pre[v]=u;
num[v]=num[u]+1;
if(!b[v]){ q.push(v); b[v]=1;}
}
}
}
}
int main()
{
memset(dis,0x7f,sizeof(dis));
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
add(x,y,z);
}
spfa(1);
printf("%d
",dis[n]);
print(n);
printf("
");
return 0;
}
100分代码:
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
struct node{
int to,next,d;
}dis[200010];
struct code{
int u,d,dfn,pre;
}que[100000010];
int n,m,num,tail,hea;
int last[10010],head[10010],lu[10010];
inline void add(int u,int v,int d)
{
dis[++num].to=v; dis[num].d=d;
dis[num].next=head[u]; head[u]=num;
}
void cot(int x)
{
if(!x) return ;
cot(que[x].pre);
printf("%d ",que[x].u);
}
void bfs()
{
memset(lu,0x7f,sizeof(lu));
lu[1]=0;
que[++tail].u=1;
while(hea<=tail)
{
hea++;
int u=que[hea].u,dfn=que[hea].dfn,d=que[hea].d;
for(int i=head[u];i;i=dis[i].next)
{
int v=dis[i].to;
if(lu[v]>d+dfn+dis[i].d)
{
lu[v]=d+dfn+dis[i].d;
tail++;
que[tail]=(code){v,lu[v],dfn+1,hea};
last[v]=tail;
}
}
}
}
int main()
{
scanf("%d%d",&n,&m);
int u,v,d;
for(int i=1;i<=m;i++)
{
scanf("%d%d%d",&u,&v,&d);
add(u,v,d);
}
bfs();
printf("%d
",lu[n]);
cot(last[n]);
return 0;
}
100分代码(Hawking)_(llfz):
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int N=100005;
const int M=200005;
const int inf=0x7fffffff;
struct node
{
int to;
int mon;
int next;
}e[M];
int n,m,t,head[N],dis[N];
int cost[N],f[M],road[M];
bool book[N];
void add(int u,int v,int w)
{
t++;
e[t].to=v;
e[t].mon=w;
e[t].next=head[u];
head[u]=t;
}
void spfa()
{
queue<int> q;
q.push(1);
cost[1]=0;
while(!q.empty())
{
int u=q.front();
q.pop();
book[u]=0;
for(int k=head[u];k;k=e[k].next)
{
int v=e[k].to;
if(dis[v]>dis[u]+e[k].mon+cost[u])
{
dis[v]=dis[u]+e[k].mon+cost[u];
cost[v]=cost[u]+1;
f[v]=u;
if(v==n)
for(int i=1;i<=n;i++)
road[i]=f[i];
if(!book[v])
{
book[v]=1;
q.push(v);
}
}
}
}
}
void write(int s)
{
if(s==0) return;
write(road[s]);
printf("%d ",s);
return;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);
}
for(int i=1;i<=n;i++)
dis[i]=inf;
dis[1]=0;
spfa();
printf("%d
",dis[n]);
write(n);
printf("
");
return 0;
}