## 前期准备
1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java
2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上
3.解压jdk 命令:tar -zxvf jdk-xxxx-xxx.tar.gz -C 目标文件目录中
4.使用root 用户 或者使用 sudo 编辑修改 vi /etc/profile
5.在文件的最后面添加上
export JAVA_HOME=xxxxxx[解压的目录]
export PATH=$PATH:$JAVA_HOME/bin
6.使用命令 : source /etc/profile 生效 ,检验是否安装成功命令 : java -version
## 开始搭建
1.首先解压Hadoop 2.5 到指定目录下,修改 /hadoop-2.5.0/etc/hadoop中的hadoop-env.sh中的JAVA_HOME
将export JAVA_HOME=${JAVA_HOME}
修改成 export JAVA_HOME=/xxxx/yyy/jdk1.7.0 (后面这个文件目录,可以使用 echo $JAVA_HOME来查看出 )
2.Hadoop 的测试开发环境有3种
1.Standalone Operation (标准版,单机启动)
2.Psedo-Distributed Operation (伪分布式启动)
3.Fully-Distributed Opeartion (完全分布式启动)
1).首先是Standalone Operation 测试
此时目录在hadoop2.5的解压目录中
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output 'dfs[a-z.]+' $ cat output/*
2)Pseudo-Distributed Opeartion (需要进行配置文件)
2.1)首先配置 :(hadoop解压目录下的)/etc/hadoop/core-site.xml中的配置文件
这个是配置NameNode所在的机器,在value中,以前通常是9000,但是在Hadoop 2.0以后通常配置的 端口是 8020 而localhost也被换成主机名(查看主机名命令:hostname)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior.zuoyan.com:8020</value>
</property>
</configuration>
在这个文件中还需要覆盖一下默认的配置,然临时文件存放到我么指定的目录
在hadoop的解压目录下,创建mkdir data ===>cd data ===>mkdir tmp
<!--configurate Temporary date storage location-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
这个文件配置完毕,下面配置 hdfs-site.xml
这是配置文件的备份数量,因为是伪分布式,所以备份数量为1就可以
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注:NameNode 存放的是元数据
第一次 对HDFS进行格式化 在hadoop的主目录中
bin/hdfs namenode -format
然后启动namenode :sbin/hadoop-daemon.sh start namenode
接着启动datanode :sbin/hadoop-daemon.sh start datanode
查看一下进程 : jps

*(有的人可能启动失败,可以去安装的主目录看一下日志:log)
http://hadoop-senior.zuoyan.com:50070 (hdfs 的web界面---Ip+50070(默认端口))
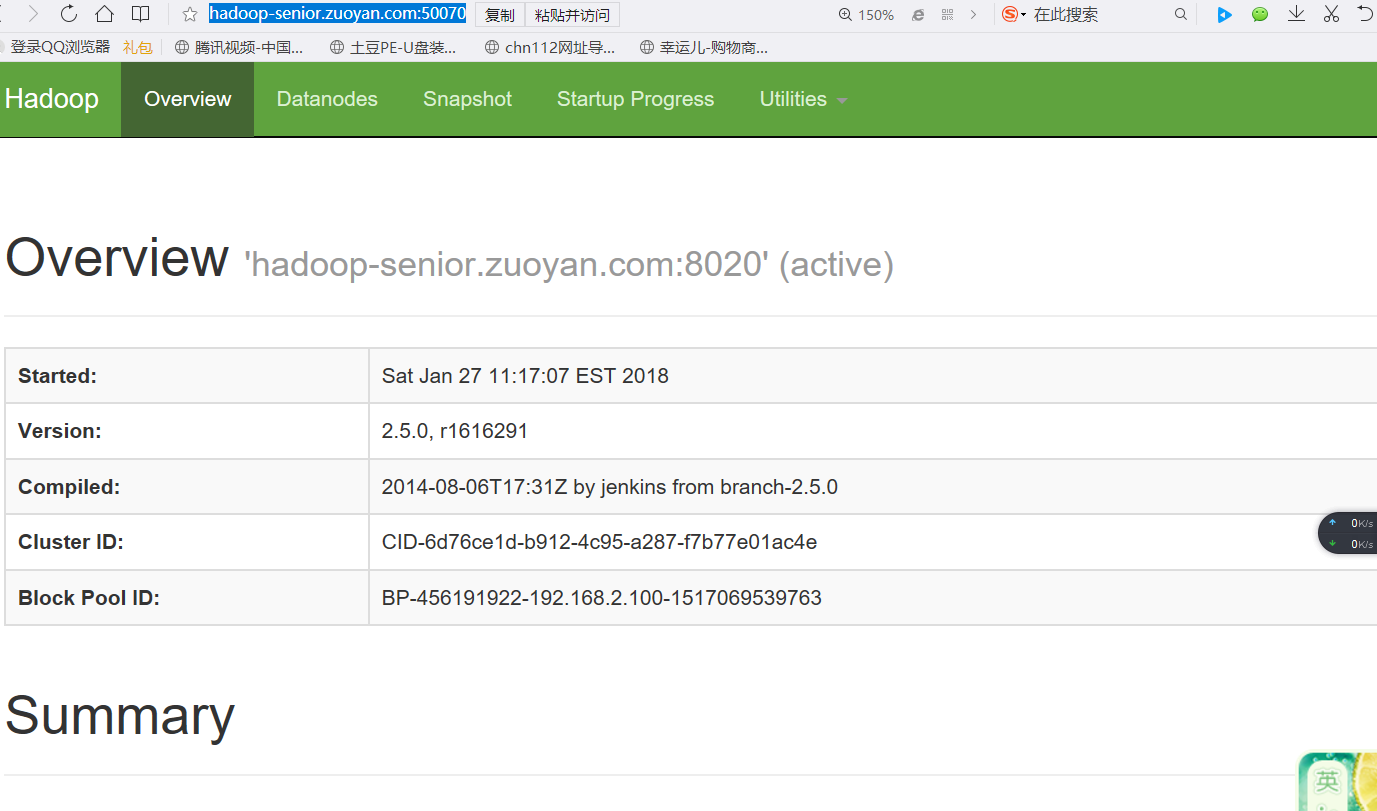
创建文件目录: bin/hdfs dfs -mkdir -p /usr/zuoyan
查看文件目录列表 : bin/hdfs dfs -ls / 或者循环查看问价目录列表 bin/hdfs dfs -ls -R /
删除文件目录 : bin/hdfs dfs -rm -r -f /xxx
上传文件: bin/hdfs dfs -put [本地文件目录] [HDFS上的文件目录]
例如:bin/hdfs dfs -put wcinput/wc.input /user/zuoyan/mapreduce/wordcount/input
效果:

使用命令查看文件列表效果:

使用命令查看文件内容 : bin/hdfs dfs -cat /XXXX/XXX
例:bin/hdfs dfs -cat /user/zuoyan/mapreduce/wordcount/input/wc.input
使用 mapreduce 统计单词出现的次数
命令: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output
使用后的效果:

上图就是输出的效果!

两种执行效果是一样的,不同的是一个是在本地上运行的,一个是在HDFS文件系统上运行的!
下面配置yarn-env.sh(所在的目录为:hadoop安装路径 /etc/hadoop)
配置JAVA_HOME (可以不进行配置,为了保险起见,可以配置上)
# some Java parameters
export JAVA_HOME=/home/zuoyan/Softwares/jdk1.7.0_79
然后配置 yarn-site.xml (所在文件目录为:hadoop安装路径 /etc/hadoop)
<configuration>
<!--config the resourcemanager locatin computer ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior.zuoyan.com</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
讲一个英语单词:slaves(奴隶,或者是从节点的意思)
在slaves 中配置一下IP地址 :hadoop-senior.zuoyan.com
下面就是yarn 初始化
1.启动resourcemanager sbin/yarn-daemon.sh start resourcemanager
2.启动 nodemanager sbin/yarn-daemon.sh start nodemanager
使用jps看一下系统进程
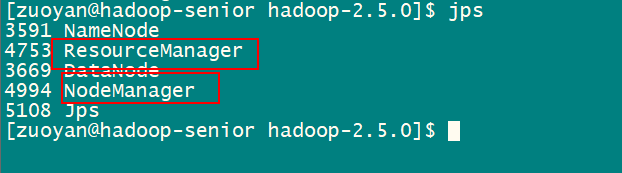
可以看到 resourceManger 和 NodeManager已经成功的启动起来了!
3.yarn也有一个自己默认的WEB页面 默认的端口号是8088
例如:http://hadoop-senior.zuoyan.com:8088 访问效果如下图

下面配置 mapreduce-site.xml 和mapreduce-env.sh
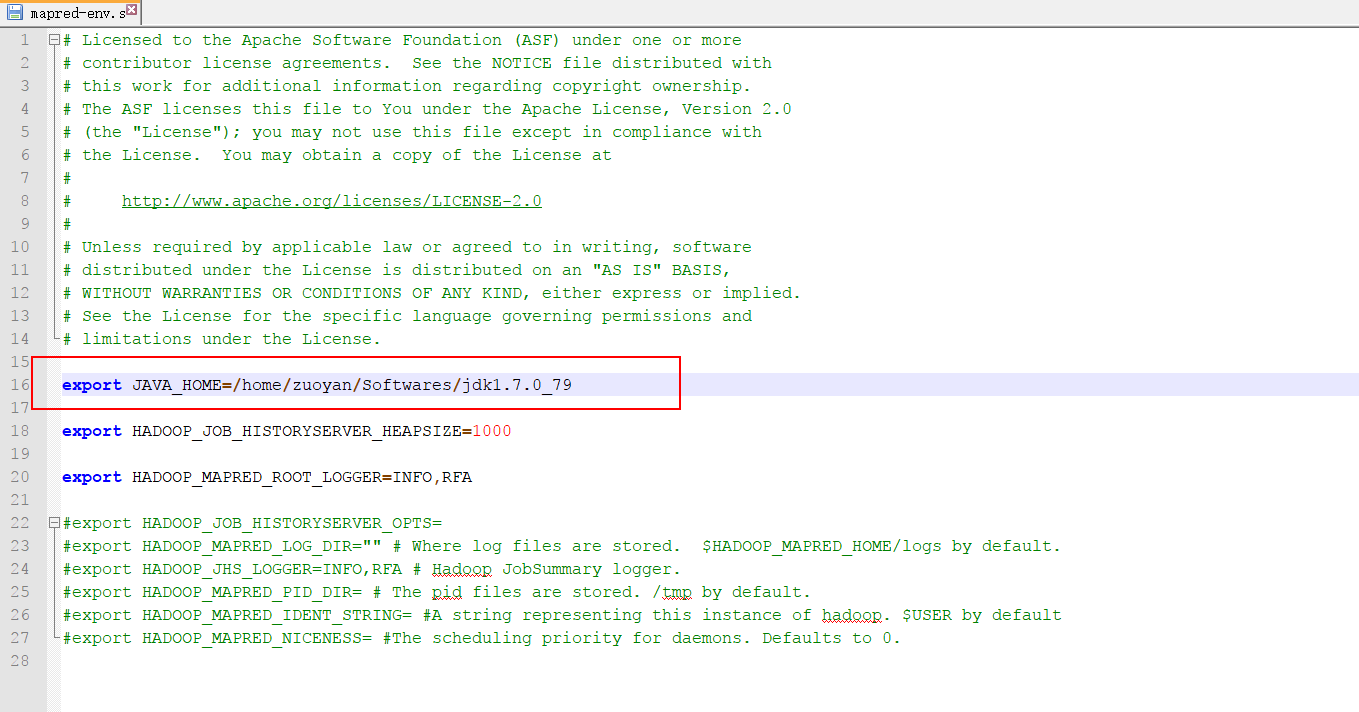
就是更改一下JAVA_HOME 的文件地址
首先找到 mapred-site.xml.template 更改文件名称 去掉后面的.template
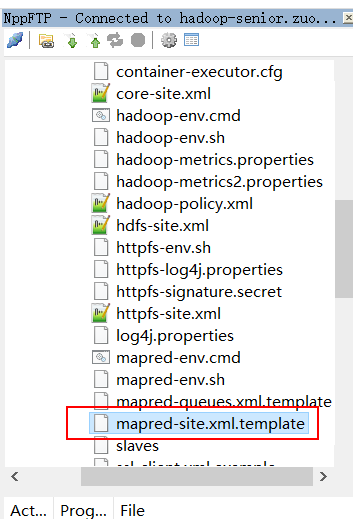
mapred-site.xml 然后配置这个里面的文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这次执行 使用yarn 不在使用本地 所以速度会慢一点
使用的命令 (使用之前要记得删除output 目录,不然会报错 )
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output
yarn执行时候的效果

上面统计单词出现个数的是
第一次演示的是 mapreduce 程序 运行在本机 (本地效果)
第二次演示的是mapreduce 程序 运行在yarn上的效果 (伪分布式效果)