在爬取一个网站内容之前,我么最好一下准备,这样会让我们更好的去思考要采取如何的一种方式来对网站的内容进行爬取。
- 检查robots.txt
里面详细介绍该网站的哪些数据是可以爬取的,哪些是不可以爬取的。同时检查robots.txt可以最小化怕从被禁封的可能。关于robots.tx协议的更多信息可以参见
http://robotstxt.org
- 检查网站地图
网站提供的Sitemap文件可以帮助爬虫定位网站最新内容,而无需爬取每一个网页,Sitemap链接可以在robots.txt中找到。虽然男男女女sitemap文件提供了一种爬取网站的有效方式,但是经常存在缺失、过期或不完整的问题。想了解更多的信息可以访问以下链接
http://www.sitemaps.org/protcol.html
例如访问豆瓣的robots.txt
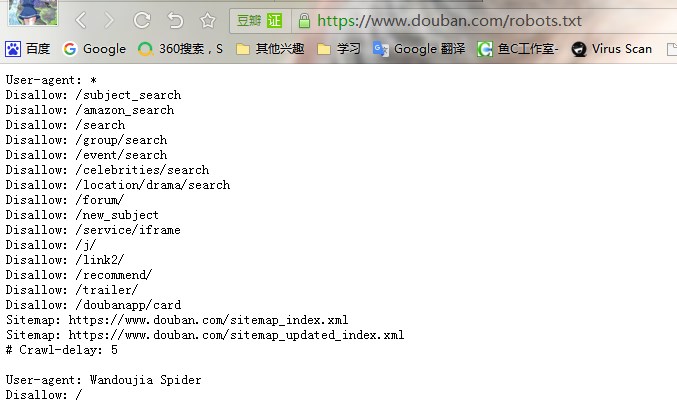
- 估算网站大小
估算网站大小的一个简便方法是检查Google爬虫的结果。听过访问一下玩个可以了解到该接口及其他高级搜索参数的用法
https://www.google.com/advanced_search
这里我们对网站进行搜索的话,直接搜
site:xxxx.xxx.xxx
- 识别网站所有技术
buildwith模块
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">builtwith.parse('example.webscraping.com')</span>然后会返回
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">{'web-servers': ['Nginx'], 'web-frameworks': ['Web2py', 'Twitter Bootstrap'], 'programming-languages': ['Python'], 'javascript-frameworks': ['jQuery', 'Modernizr', 'jQuery UI']}</span>这里值得一说的是,builtwith模块是不支持python2.0以上的版本,但是这并不是一个问题,跟着它报错的地方来进行修改后,builwith模块就可以使用了。下面提出要修改的地方
- except Expection,e错误
将代码
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">except Expection , e:</span>修改为
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">except Expection as e:</span>- print 错误
给每个输出的内容,都添加上括号
- TypeError
在代码
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">if html is None:
html = response.read()</span>后面添加下面一句
<span data-wiz-span="data-wiz-span" style="font-size: 0.667rem;">html = html.decode('gbk') #或者 html = html.decde('utf-8')</span>- 寻找网站所有者
在我们知道已知网站的所有者会禁封网络爬虫,那么我们最好将下载速度控制的更加保守一些。可以通过一下代码来获取网站的所有者
import whois
print (whois.whois('appspot.com'))<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">