这个想法其实由来已久,一直是想对github里机器人账号和正常User账号进行二分类。刚好最近做了一个actor中间表,发现github里会提供User的type,这个type里有User也有Bot。于是我就想简单用一下这些账号的用户名做一个二分类训练。
导入需要的包
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from torch.nn.modules.sparse import Embedding
import torchtext as tt
import torch
import torch.nn as nn
import random
import torch.utils.data as Data
from d2l import torch as d2l
from collections import Counter, OrderedDict
数据处理和分析
names = []
labels = np.array([])
bot_tokens = []
user_tokens = []
tokens = []
with open('./Bot/Bot.csv', 'r') as f:
lines = f.readlines()
for line in lines:
if line is not None:
names.append([s for s in line.replace("\n", "")])
labels = np.append(labels, 1)
bot_tokens += [s for s in line.replace("\n", "")]
tokens += [s for s in line.replace("\n", "")]
with open('./Bot/User.csv', 'r') as f:
lines = f.readlines()
for line in lines:
if line is not None:
names.append([s for s in line.replace("\n", "")])
labels = np.append(labels, 0)
user_tokens += [s for s in line.replace("\n", "")]
tokens += [s for s in line.replace("\n", "")]
这里我拿到了所有token组成的tokens,因为是用用户名做二分类,所以我对词源就是用户名。
s = open('num.text', 'w+')
def get_bar(tokens, file_name):
counter = Counter(tokens)
df = pd.DataFrame()
df['char'] = counter.keys()
df['num'] = counter.values()
df.set_index(['char'], inplace=True)
df.sort_values(ascending=False, by='num', inplace=True)
plt.bar(df.index, df['num'])
plt.savefig("{}.png".format(file_name))
plt.clf()
s.write("{}: {}\n".format(file_name, df.size))
get_bar(bot_tokens, 'bot_count')
get_bar(user_tokens, 'user_count')
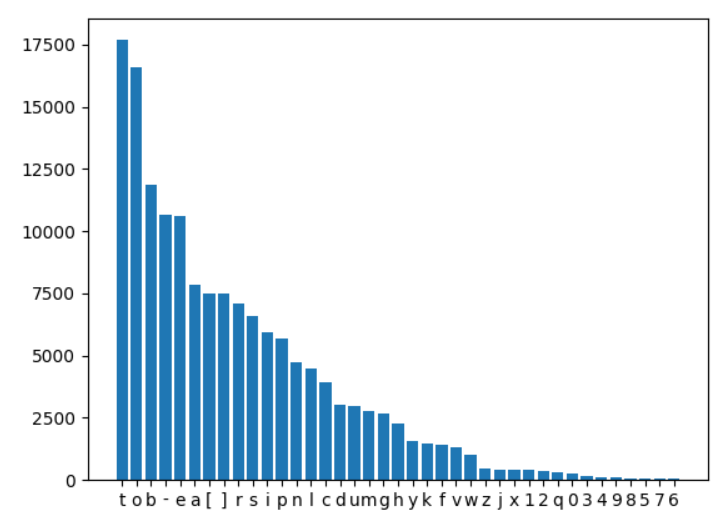
其中bot账号名称中有39个不同的字符。
user账号中有63个不同的字符。
bot账号,字符统计:
user账号,字符统计:
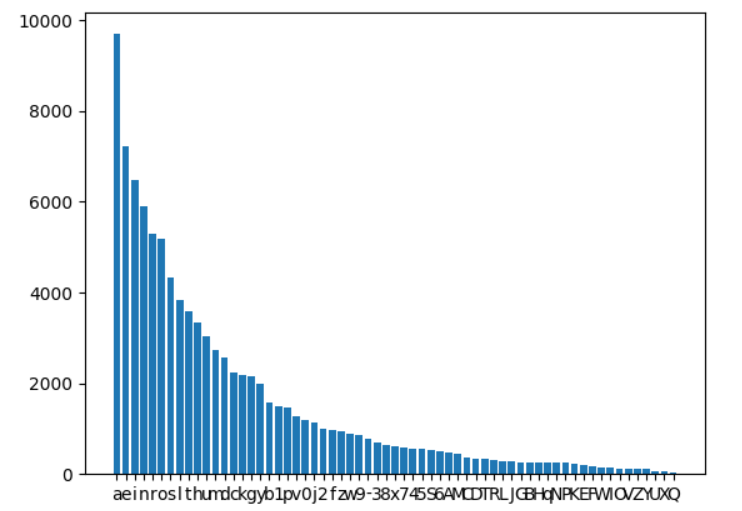
可以看到这两两种账号的字符频率差异还是很大的。
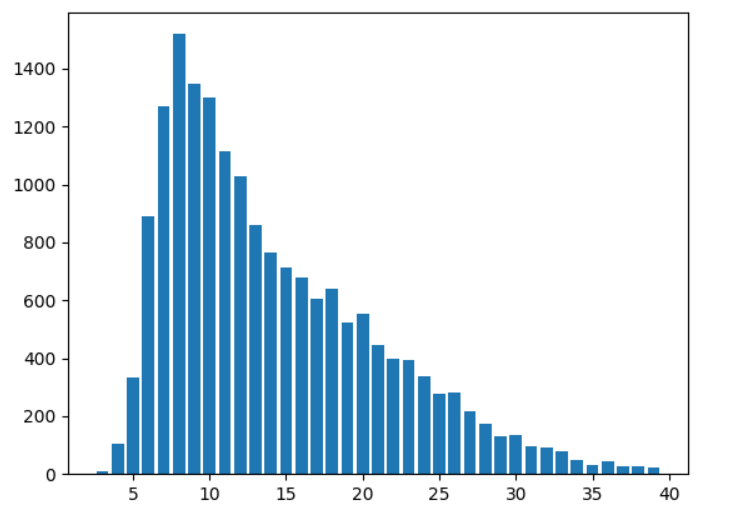
账户名长度分布:
Pading
counter = Counter(tokens)
sorted_by_freq_tuples = sorted(counter.items(), key=lambda x: x[1], reverse=True)
ordered_dict = OrderedDict(sorted_by_freq_tuples)
vb = tt.vocab.vocab(ordered_dict)
vb.insert_token('<pad>', 0)
data = []
valid_len = []
for name in names:
if len(name) > 40:
data.append(vb.forward(name[:40]))
valid_len.append(40)
else:
t = [s for s in name]
t += ['<pad>' for _ in range(40-len(name))]
data.append(vb.forward(t))
valid_len.append(len(name))
做成data_iter
data = np.asarray(data)
valid_len = np.asarray(valid_len)
labels = labels.astype(np.int64)
random_indices = list(range(len(data)))
random.shuffle(random_indices) # 随机索引
eval_data = torch.tensor(data[random_indices[-500: ]])
eval_valid_len = torch.tensor(valid_len[random_indices[-500: ]])
eval_labels = torch.tensor(labels[random_indices[-500: ]])
train_data = torch.tensor(data[random_indices[:-500]])
train_valid_len = torch.tensor(valid_len[random_indices[:-500]])
train_labels = torch.tensor(labels[random_indices[:-500]])
train_data_set = Data.TensorDataset(train_data, train_valid_len, train_labels)
train_iter = Data.DataLoader(train_data_set, shuffle=True, batch_size=32)
test_data_set = Data.TensorDataset(eval_data, eval_valid_len, eval_labels)
test_iter = Data.DataLoader(test_data_set, shuffle=True, batch_size=32)
这里取batchsize为32
定义GRU模型
class GRU_based(nn.Module):
def __init__(self, vocab_size, embed_dim, hdim, classes=2, dropout=0):
super(GRU_based, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.GRU = nn.GRU(embed_dim, hdim, 2 , batch_first=True, dropout=dropout)
self.Linear = nn.Linear(hdim, classes)
def forward(self, X):
X = self.embedding(X)
_, h = self.GRU(X)
h = h[1]
h = self.Linear(h)
return h
这个模型还是很简单的,定义了两层的GRU,并且batch_size fist设置为了true,这样就不用再调换维度了。
训练
epochs = 5
embed_dim = 256
hdim = 256
classes = 2
dropout = 0.1
vocab_size = len(vb)
model = GRU_based(vocab_size, embed_dim, hdim, classes, dropout)
model.cuda()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(epochs):
metric = d2l.Accumulator(3)
for X, _, y in train_iter:
X = X.cuda()
y = y.cuda()
y_hat = model(X)
l = loss(y_hat, y) # y_hat shape (batch_size, 2)
optimizer.zero_grad()
l.backward()
optimizer.step()
acc_sum = (y_hat.argmax(dim=-1) == y).sum()
num = len(y)
lsum = l.item() * num
metric.add(num, lsum, acc_sum)
print("epoch: %d acc: %.3f, loss: %.3f"%(epoch, metric[2]/metric[0],metric[1]/metric[0]))
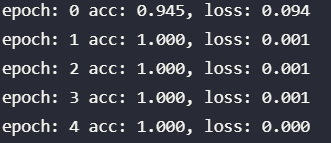
第二个epoch时候就train除了100准确度。。。
测试
def recall(y_hat, y):
y_bot = (y > 0).sum()
y_hat_true_bot = ((y_hat.argmax(dim=-1) == y) * ( y > 0)).sum()
return y_hat_true_bot, y_bot
model.eval()
metric = d2l.Accumulator(4) # acc recall
for X, _, y in test_iter:
X = X.cuda()
y = y.cuda()
y_hat = model(X)
acc_sum = (y_hat.argmax(dim= -1) == y).sum() # 正确检测数
num = len(y) # 样本数
pbn, bn = recall(y_hat, y)
metric.add(num, acc_sum, pbn, bn)
print("acc: %.3f recall: %.3f"%(acc_sum/num, pbn/bn))
结果:acc: 1.000 recall: 1.000
总结
这次训练其实挺失败的。。。因为数据源有点问题,我用的有标记的数据,bot账号它可能是有github官方创建的。

这些命名具有很强的规律性,每个账号名后面都会加一个[bot] ,所以模型可以很容易将它们进行分类。