终于来到transformer了,之前的几个东西都搞的差不多了,剩下的就是搭积木搭模型了。首先来看一下transformer模型,OK好像就是那一套东西。
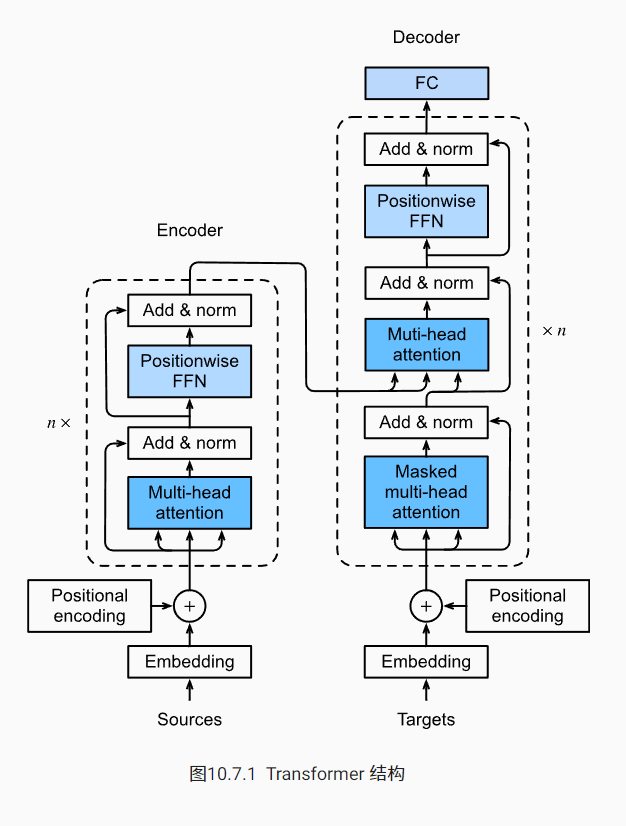
transformer是纯基于注意力机制的架构,但是也是之前的encoder-decoder架构。
层归一化
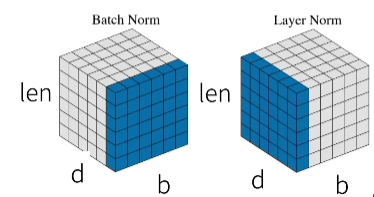
这里用到了层归一化,和之前的批量归一化有区别。
这里参考了torch文档:

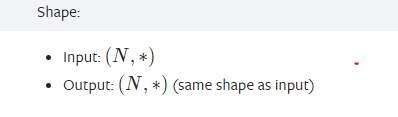
N就是batchsize维,layernorm就是对一个batch里序列里的向量做归一化。
Encoder
import torch
import torch.nn as nn
import torch.nn.functional as F
from d2l import torch as d2l
class add_norm(nn.Module):
def __init__(self, norm_shape, dropout=0):
super(add_norm, self).__init__()
self.norm = nn.LayerNorm(norm_shape)
self.dropout = nn.Dropout(dropout)
def forward(self, X, Y):
return self.norm(X + self.dropout(Y)) #这里默认X, Y的shape一样
class EncoderBlock(nn.Module):
def __init__(self, embed_dim, norm_shape):
super(EncoderBlock, self).__init__()
self.add_norm1 = add_norm(norm_shape=norm_shape)
self.attention = nn.MultiheadAttention(embed_dim, 8, batch_first=True) # 这里将batch_first 设置为了True。
self.ffn = nn.Sequential(nn.Linear(embed_dim, embed_dim), nn.ReLU(), nn.Linear(embed_dim, embed_dim))
self.add_norm2 = add_norm(norm_shape=norm_shape)
def forward(self, X):
Y,_ = self.attention(X, X, X)
X = self.add_norm1(X, Y)
Y = self.ffn(X)
X = self.add_norm2(X, Y)
return X
class Encoder(nn.Module):
def __init__(self, embed_dim, norm_shape, num_block) -> None:
super(Encoder, self).__init__()
self.pos_encoding = d2l.PositionalEncoding(embed_dim, dropout=0)
self.EncoderBlocks = [EncoderBlock(embed_dim, norm_shape) for _ in range(num_block)]
def forward(self, X):
X = self.pos_encoding(X)
for i in range(len(self.EncoderBlocks)):
X = self.EncoderBlocks[i](X)
return X
model = Encoder(128, [35, 128], 2)
s = torch.zeros((64, 35, 128))
s = model(s)
用torch实现了一个encoder, decoder不想写,摆烂了,就这样,爱咋滴咋滴,以后就调用框架了。

直接用框架实现了,爱咋滴咋滴吧。