之前在seq2seq算法上浪费了太多时间了。。。搞得本来早就应该进行Attention被拖到现在,真实无语了,被自己的愚蠢给吓到了。
What is Attention
我个人的理解是Attention是一种重要度区分机制。
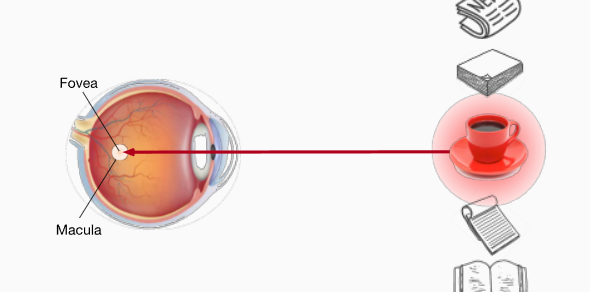
注意力使得我们关注的东西具有了区分度,也就是说,原本没有差异的一组事物,被Attention划分出了重要度。
so,放在RNN里怎么理解呢?
之前的 seq2seq 我们将 encoder 得到的最后一个时间步的那个输出和 decoder 的所有的 embedding 进行了拼接。但是我们并没有用到 encoder 隐藏层的所有时间步的输出。
比如 encoder 编码 hello world !,隐藏层会有三个时间步的输出,分别对应了hello 、world 以及!,那我们decoder在训练的时候,比如翻译为法语Salut tout le monde !。那么salut可能更关注于hello,而monde可能关注与world。于是我们进行向量拼接的时候能否就说使用特定时间步的隐藏层输出呢?这或许是Attention所要想解决的问题。
Q, K, V
Q, K, V就是查询、键和值。
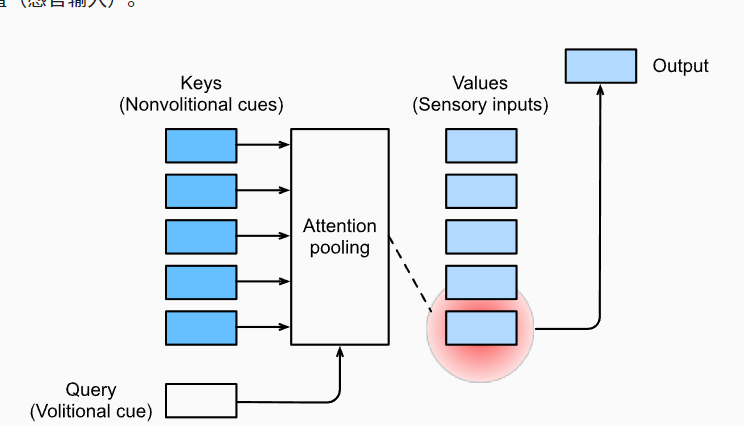
查询我觉得可以理解为就是一种Attention,通过以一种attention方式查询key我们确定了我们应该以何种方式选取value。
注意力机制拟合函数
import numpy as np
import matplotlib.pyplot as plt
import torch
X, _ = torch.sort(torch.rand(100)* 5)
def f(x):
return 2 * torch.sin(x) + x ** 0.8
T = f(X)
Y = f(X) + torch.normal(0.0, 0.5, (100,))
Z = X.reshape(-1, 1).repeat(1, 100)
t = -(Z - X)**2 /2
attention_weights = torch.softmax(t, dim=-1) # 在这里每一次查询用的还是自身的key
y_hat = attention_weights @ Y
plt.plot(X, y_hat)
plt.plot(X, Y)
plt.plot(X, T)
plt.show()
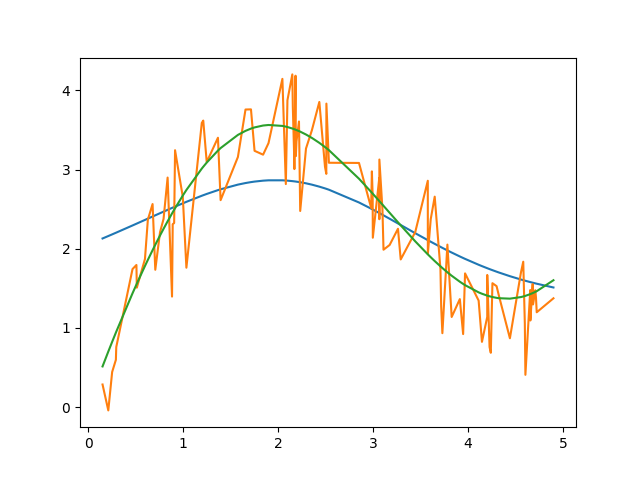
拟合的不算很好,但是也还过得去不是吗?
加性Attention机制
如果键K和查询Q的长度不一样当下,那么就需要用到加性注意力机制来作为评分函数。
对于$ q \in R^q \quad k \in R^k$ 那么我们实际上需要做一个加性评分函数的。
其中\(\mathbf{W}_{q} \in \mathbb{R}^{h \times q} 、 \mathbf{W}_{k} \in \mathbb{R}^{h \times k}\) 和 \(\mathbf{w}_{v} \in \mathbb{R}^{h}\)
那么有一个新的问题,我想得到的不是仅仅是一个标量啊,我想要的是整个softmax向量。OK,解决这个问题之前先要解决mask_softmax 问题。
mask_softmax
mask_sequence:
def mask_sequence(X, valid_len,value=-1e6):
max_len = X.shape[1] # 因为valid_len 进行mask是从外往里面看,所以要看到第二维
mask = torch.arange((max_len), dtype=torch.float32, device=X.device)\
[None, :] < valid_len[:, None]
X[~mask] = value
return X
理解mask_sequence 的精髓就在于理解从外向里 看。valid_len是作用在最外面那个维度的。
mask_softmax
def mask_softmax(X, valid_len=None, value=0):
'''
X shape (batch_size, query, k-vn]
对于这种 3D 的,要进行mask,很显然需要再往张量里面看一个维度
'''
if valid_len is None:
return F.softmax(X, dim=-1)
shape = X.shape
valid_len = valid_len.repeat_interleave(shape[1])
X = mask_sequence(X.reshape(-1, shape[-1]), valid_len, value)
return F.softmax(X.reshape(shape), dim=-1)
AdditiveAttention
因为是升维、降维搞得我尽力憔悴的。。。
但还好最后是理解了怎么回事。。。直接看代码:
class AdditiveAttention(nn.Module):
def __init__(self,qdim, kdim, hdim,dropout=0): # 查询的维度qdim, key的维度kdim, 隐藏层维度 hdim
super(AdditiveAttention, self).__init__()
self.W_q = nn.Linear(qdim, hdim)
self.W_k = nn.Linear(kdim, hdim)
self.W_h = nn.Linear(hdim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, Q, K, V, valid_lens =None):
'''
Q : query shape (batch_size, query_num, qdim)
这里的query_num 在seq2seq 里应该为1, 因为decoder阶段我们每一步查一次
K : key shape (batch_size, key_num, kdim)
这里的key_num 在seq2seq 里实际上就是encoder时间步,因为我们每一步产生了一个key
V : 这里的V实际上和K是一个东西。
valid_len: shape (batch_size) 对应的每个batch,因为我们在encoder阶段用了填充,也是有些key-value其实是没有用的。
'''
qh = self.W_q(Q)
kh = self.W_k(K)
'''问题又来了
qh shape (batch_size, query_num, hdim)
kh shape (batch_size, key_num, hdim)
我们没有办法直接相加,这时候需要做一个boardcast。
'''
features = F.tanh(qh.unsqueeze(2) + kh.unsqueeze(1))
'''
为什么我们要这样升维度呢?
因为我们想让query 的最后一维向量(, hidm)与 (key_num, hidm) 相加
于是我们选择了这样的广播方式,features shape (batchsize, query_num, key_num, hidm)
'''
features = self.W_h(features)
'''现在features shape (batchsize, query_num, key_num, 1)'''
features = features.squeeze(-1)
'''于是我们拿掉了最后一个维度,这并不会影响什么,现在features的shape就是
(batch_size, query_num , key_num)。
OK,在seq2seq 里这是什么呢?
features shape (batch_size, 1, encoder_num_steps) 因为我们用的是encoder阶段产生的隐藏层输出作为key-value pair
'''
self.attention_weight = mask_softmax(features, valid_lens)
return torch.bmm(self.dropout(self.attention_weight), V)
它的forward函数真的难写,我基本上上写一句就要写一大段注释,不然根本记不住,可以料想到我很快也会完了的,所以现在注释写明白些以后忘了在回看就行了。
缩放点积注意力
刚刚看了一下torch的attention实现方式,发现它是用的一个缩放点积注意力函数。
缩放点积的运算速度的确比加性要好。
def _scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r"""
Computes scaled dot product attention on query, key and value tensors, using
an optional attention mask if passed, and applying dropout if a probability
greater than 0.0 is specified.
Returns a tensor pair containing attended values and attention weights.
Args:
q, k, v: query, key and value tensors. See Shape section for shape details.
attn_mask: optional tensor containing mask values to be added to calculated
attention. May be 2D or 3D; see Shape section for details.
dropout_p: dropout probability. If greater than 0.0, dropout is applied.
Shape:
- q: :math:`(B, Nt, E)` where B is batch size, Nt is the target sequence length,
and E is embedding dimension.
- key: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
and E is embedding dimension.
- value: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
and E is embedding dimension.
- attn_mask: either a 3D tensor of shape :math:`(B, Nt, Ns)` or a 2D tensor of
shape :math:`(Nt, Ns)`.
- Output: attention values have shape :math:`(B, Nt, E)`; attention weights
have shape :math:`(B, Nt, Ns)`
"""
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2, -1))
if attn_mask is not None:
attn += attn_mask
attn = softmax(attn, dim=-1)
if dropout_p > 0.0:
attn = dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
就是一个简单的点积。