导入数据
train_content = pd.read_csv("./house_prices/data/train.csv")
test_content = pd.read_csv("./house_prices/data/test.csv")
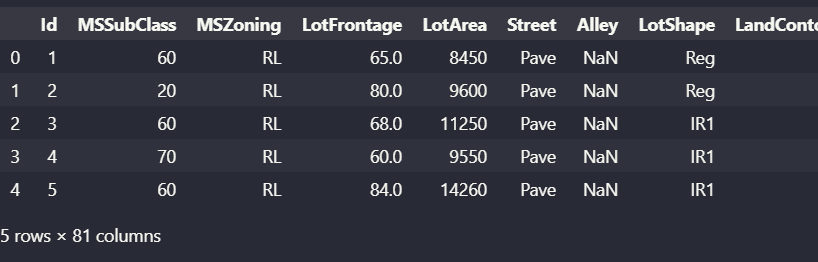
train_content.head()
特征工程
将train 数据和 test 数据合并,一块处理特征
all_features = pd.concat((train_content.iloc[:, 1:-1], test_content.iloc[:, 1:]))
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # 得到非object的索引列
all_features[numeric_features] = all_features[numeric_features].apply(lambda x:(x- x.mean())/(x.std())) # 标准化
all_features[numeric_features] = all_features[numeric_features].fillna(0) # nan元素填充为0
现在来考虑非数字的那些列,这里用one_hot 的方法来处理
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
接着得到train_features 和 labels
n_train = train_content.shape[0]
train_features = torch.tensor(all_features.iloc[0:n_train,:].values, dtype=d2l.float32)
train_labels = torch.tensor(train_content.iloc[:, -1].values.reshape(-1, 1), dtype=d2l.float32)
test_features = torch.tensor(all_features.iloc[n_train:, :].values, dtype=d2l.float32)
train_labels
在这里我犯了一个严重的错误,直接导致我后续训练误差一直减不下的。正常的训练误差是0.15, 而我的训练误差为0.4,我排查了很久,最终发现,问题出在了train_label 上。
刚开始获得labels 的代码。
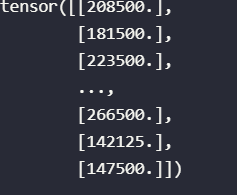
train_labels = torch.tensor(train_content.iloc[:, -1].values, dtype = d2l.float32)
train_labels
tensor([208500., 181500., 223500., ..., 266500., 142125., 147500.])
reshape 的代码
train_labels = torch.tensor(train_content.iloc[:, -1].values.reshape(-1, 1), dtype=d2l.float32)
train_labels
无论是第一种方式获得的labels 还是 第二种方式获得的 labels ,均可以用torch进行计算, 而且不会有报错……这是一个非常蛋疼的点
搭建模型
我刚开始准备搭建一个三层的MLP,但是它的性能还没有一层全连接网络好,无语,这还深度学习楞……
class LinearLay(nn.Module):
def __init__(self, indim, outdim):
super(LinearLay, self).__init__()
self.weight = nn.Parameter(torch.FloatTensor(indim, outdim))
self.bias = nn.Parameter(torch.FloatTensor(outdim))
nn.init.xavier_uniform_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
return torch.matmul(x, self.weight) + self.bias
class Linear(nn.Module):
def __init__(self, indim, hiddim, outdim, dropout):
super(Linear, self).__init__()
self.Lay1 = LinearLay(indim, 128)
self.Lay2 = LinearLay(128, 16)
self.Lay3 = LinearLay(16, outdim)
self.dropout = dropout
def forward(self, x):
x = F.tanh(self.Lay1(x))
x = F.dropout(x, self.dropout, training=self.training)
x = F.tanh(self.Lay2(x))
x = F.dropout(x, self.dropout, training=self.training)
out = self.Lay3(x)
return out
直接一层全连接层
net = nn.Linear(train_features.shape[1], 1)
定义log rmse, 这个评价指标有点像accuracy,它和训练的那个MSEloss功能不一样的。
def log_rmse(net, loss, features, labels):
clipped_preds = torch.clamp(net(features), 1, float('inf')) #把小于1的数值全部定义为1,这个函数好用
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
训练函数
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, lr, wd, batch_size, cuda=True):
if cuda: # 放在gpu上训练
net.cuda()
train_features = train_features.cuda()
train_labels = train_labels.cuda()
if test_features is not None:
test_features = test_features.cuda()
test_labels = test_labels.cuda()
net.train()
train_ls, test_ls = [], []
dataset = data.TensorDataset(train_features, train_labels)
data_iter = data.DataLoader(dataset, batch_size, shuffle=True)
# 用Adam优化器
optimizer = torch.optim.Adam(net.parameters(), lr= lr, weight_decay=wd)
loss = nn.MSELoss()
for epoch in range(num_epochs):
for x, y in data_iter:
optimizer.zero_grad()
loss_train = loss(net(x), y)
loss_train.backward()
optimizer.step()
train_ls.append(log_rmse(net, loss, train_features, train_labels))
if test_features is not None:
test_ls.append(log_rmse(net, loss, test_features, test_labels))
return train_ls, test_ls
这里有个主意的点, net 放到gpu是直接net.cuda(),tensor 放到gpu上要train_features = train_features.cuda()
K折交叉验证
def get_K_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j*fold_size, (j+1)*fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_val, y_val = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], dim=0)
y_train = torch.cat([y_train, y_part], dim=0)
return X_train, y_train, X_val, y_val
def K_flod(indim, k, features, labels, num_epochs, lr, wd, batch_size):
train_ls_sum, test_ls_sum = 0.0, 0.0
cuda = torch.cuda.is_available()
for i in range(k):
net = nn.Linear(indim, 1) # 每一次单独用一个net
data = get_K_fold_data(k, i, features, labels)
train_ls, test_ls = train(net, *data, num_epochs, lr, wd, batch_size, cuda)
train_ls_sum += train_ls[-1]
test_ls_sum += test_ls[-1]
if i==0:
d2l.plot(list(range(1, num_epochs+1)), [train_ls, test_ls], xlabel='epochs',
ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print('flod {}, train log rmse {} valid log rmse {}'.format(i+1, train_ls[-1], test_ls[-1]))
return train_ls_sum/k, test_ls_sum/k
训练
indim = train_features.shape[1]
lr = 10
batch_size = 64
wd = 5e-5
num_epochs = 200
t = time.time()
k = 5
train_ls, val_ls = K_flod(indim, k, train_features, train_labels, num_epochs, lr, wd, batch_size)
print('{}-折交叉验证,平均训练log rmse: {} 平均验证 log rmse:{}'.format(k, train_ls, val_ls))
print("耗时:{}s".format(time.time()-t))
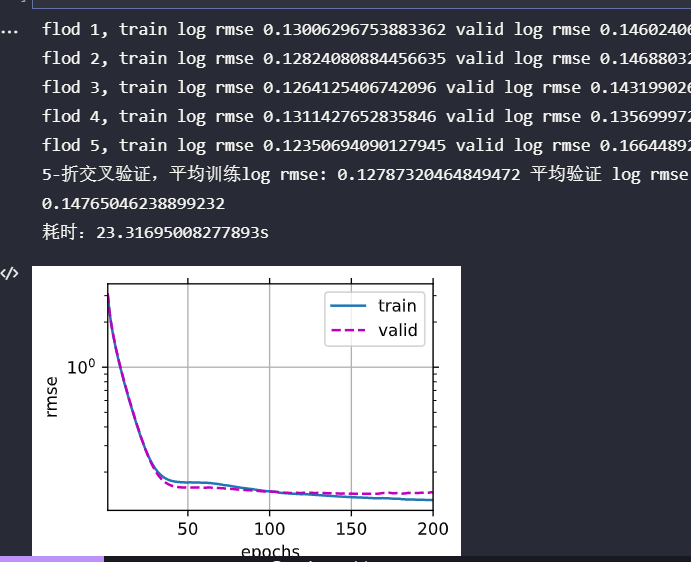
像那么一回事,不是吗?
训练并预测
net = nn.Linear(indim, 1)
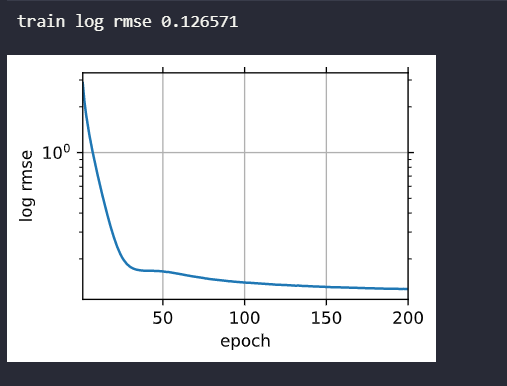
train_ls,_ = train(net, train_features, train_labels, None, None, 200, 10, 5e-5, 64) # 直接训练
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# 将网络应用于测试集。
test_features = test_features.cuda() # net在cuda上
net.eval()
preds = net(test_features).to('cpu').detach().numpy() # 要用detach,因为net(x)计算得到的Tensor是有梯度grad的,要想detach然后才能转为ndarray。
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)