首先插入排序:(本文定义有序从小到大)
1)直接插入排序:
例如: 如果数组大小为1,该数组必然有序,现在插入一个数据
如果数组大小为1,该数组必然有序,现在插入一个数据
可以看到此时此时该数组已经无序,将74记录下来,现在开始遍历之前有序的数组,83比74大,用84覆盖74,有序序列遍历完毕,把74放在原来84的位置,得到有序序列
现在看数组下一个元素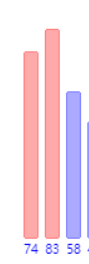 ,同意处理先记录下来58,再看有序序列,83大于58,于是把58覆盖,74大于58,于是覆盖了83,有序序列遍历完毕,再把58放在原来74的位置。得到
,同意处理先记录下来58,再看有序序列,83大于58,于是把58覆盖,74大于58,于是覆盖了83,有序序列遍历完毕,再把58放在原来74的位置。得到
新的有序序列 ,至此我们得到了简单插入排序的规则,每次对一次已经有序的数组和一个未在该数组内的数字进行处理。第一步先记录好该未在有序数组内的数字,第二步进行遍历,如果
,至此我们得到了简单插入排序的规则,每次对一次已经有序的数组和一个未在该数组内的数字进行处理。第一步先记录好该未在有序数组内的数字,第二步进行遍历,如果
数字小于数组内数字就往后移,直到遇到第一个不大于该数字的关键字,那么就把刚才记录下来的数字放在他的前面。
实现代码:
void InsertSort(int A[], int n) //A表示该数组,n表示数组长度 { //定义数组元素从1开始 for (int i = 2; i < n; i++) { A[0] = A[i]; //用i做哨兵 int j = i - 1; while(A[j]>A[0]){//表示处于无序状态,注意这里不能用等号,等号就会改变排序的稳定性 A[j + 1] = A[j]; j--; } A[j + 1] = A[0]; } }
复杂度:最好情况下,该数组有序,只需要遍历即可,复杂度为O(n),最坏情况为完全逆序,复杂度O(n2)。平均复杂度为O(n2);具有稳定性。
直接插入虽然简单,复杂度高,但处理链表排序时很有用。
对无序链表进行排序:
typedef struct Node{ int data; Node*next=NULL; }*pnode; void ListSort(pnode L){//对具有头结点的链表排序 pnode p=L->next->next; pnode head=L; head->next->next=NULL;//将链表分开,有序表只含有一个元素 while(p){ pnode r=p->next; pnode q=head; while(q->next!=NULL&&q->next->data<p->data)q=q->next; p->next=q->next; q->next=p; p=r;//继续往下走 } }
2)折半插入排序
在插入排序中为了找到数字应该待的位置,采用从头遍历的方式。而现在通过改进使用折半查找,找到数字该插入的位置,再进行插入,需要注意的是,插入的时间复杂度没有改变,决定时间复杂度的是外循环和内循环插入,时间复杂度还是O(n2)。
代码实现:
void HalfInsertSort(int A[],int n){ for(int i=2;i<n;i++){ int high=i-1,low=1,mid,j=i-1; A[0]=A[i]; while(high<=low){ mid=(high+low)/2; if(A[mid]>A[0]){ high=mid-1; }else{ low=mid+1; } } for(;j>=high+1;j++){ A[j+1]=A[j]; } A[high+1]=A[0]; } }
通过查找找到有序序列中最后一个等于当前未排序数字的编号high,而插入要插入到它的前面,所以遍历到high+1;
3)希尔排序
希尔排序是直接插入排序的变形,关键重点在于理解步长。在希尔排序里引入了步长的概念,根据步长将数组划分了多个,假如步长为s,那么1,2,3……n的数组就划分为了1,1+s,1+2s……;2,2+s,2+2s……;3,3+s,3+2s……。如果步长s为1那么这一群数组就退化为1个数组1,2,3……n。分别对由相同步长划分出的不同数组进行插入排序,不断缩短步长直到最后步长为1,退化为对整个数组进行排序。
第一个步长划分
起始的步长定义为数组长度的二分之一,所以第一个步长划分的数组大小全部为2。可以看到初始步长划分的第一数组为无序,用插入法进行排序。
再对初始步长划分的第二个数组进行排序,一样使用插入排序。
缩短步长,一般取上一个步长的二分之一,那么这个步长划分数组就为:
用插入排序,对每个数组进行排序。
直到退化为原有数组,再对整个数组使用插入排序。
代码实现:
void ShellSort(int A[],int n){ for(int dk=n/2;dk>=1;dk++){//dk为步长 //以下部分为插入排序,A[0]作为暂存单元非哨兵 for(int i=dk+1;i<n;i++){ A[0]=A[i]; int j=i-dk;//数组按步长划分 while(A[0]<A[j]&&j>0){ A[j+dk]=A[j]; j-=dk; } A[j+dk]=A[0]; } } }
希尔排序的最坏复杂度为O(n2),但一般它的效率远高于直接插入排序。
交换排序:
1)冒泡排序。
冒泡排序是我第一个接触的排序,那时我连一门语言也不会,但当时我还是能够
void BubbleSort(int A[],int n){ for(int i=0;i<n;i++){ for(int j=1;j<n-i;j++){ if(A[j]<A[j-1]){ swap(A[j],A[j-1]); } } } }
领会到了这个算法的实现思想,并为之击节。
冒泡排序是一种稳定的算法,且其最坏时间复杂度和最好时间复杂度均为O(n2)。
2)快排
可以说,理解了递归就理解了快速排序。每次在数组中范围内任意选择一个数,一般选最右边的数,也可以选中间的数,只要选择一个数作为基数就行了,基数的选择越随机越好,每一次递归要实现左边的数一定要小于基数,右边的数要大于基数。接下来循环操作:设置两个指针i、j。工作指针i从数组最右端向左遍历,遇到大于基数的数就停下来,因为我们要满足基数右边的数一定要小于基数;指针j从数组最左端向右遍历,遇到小于基数的数就停下来,因为基数左边的数要大于基数。于是我们现在得到了两个位置,刚好可以进行交换使其满足要求。直到两个指针遇到一块了,把基数放在这个位置,就实现了左边的数要小于基数,右边的数要大于基数。
由于基数的左边还没有处理好,于是递归处理基数的左半部分,再递归处理基数的右边部分。
如图:指针i,j正在工作,i定在了37处,因为37比2大。指针j继续工作,因为4要比2大,所以符合要求继续遍历。
指针都停住了,于是交换两组数据
这样直至一组数据处理完毕,进入递归
算法的平均空间复杂度为O(n*log(2)n),平均时间复杂度也为O(n*log(2)n),快排不是稳定的排序算法。
void QuickSort(int *a,int low,int high){ if(low>=high)return; int i=low,j=high; int base=a[(low+high)/2]; while(i<j){ while(i<j&&a[j]>=base)j--;//遇到不满足要求就停下来 while(i<j&&a[i]<=base)i++; if(i<j)swap(a[i],a[j]); } a[(low+high)/2]=a[i]; a[i]=base; QuickSort(a,low,i-1); QuickSort(a,i+1,high); }
选择排序:
1)选择排序
就是遍历,找到最小的元素放在最前面。
void SelectSort(int*a,int n){ for(int i=0;i<n;i++){ int min=i; for(int j=i;j<n;j++) if(a[j]<a[min])min=j; if(i!=min)swap(a[min],a[i]); } }
2)堆排序
int heap[100]; //原始的序列 void down_adjust(int heap[], int i, int all) { //调整函数 int j = i * 2; while (j <= all) //有孩子结点 { if (j + 1 <= all && heap[j + 1] > heap[j])//有右孩子,且右孩子比左孩子大,用右孩子 j++; if (heap[i] < heap[j]) { swap(heap[i], heap[j]); i = j; j = i * 2; } else { break;//如果这个根节点满足堆的定义就停止往下 } } } void creat_heap(int heap[],int all){ for(int i=all/2;i>=1;i--){ down_adjust(heap,i,all); } } void heap_sort(int heap[],int all){ creat_heap(heap,all); for(int i=all;i>1;i--){ swap(heap[1],heap[i]); down_adjust(heap,1,i-1);//调整顶推 } }