Ⅰ.hadoop 安装配置
1)目录位置: /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk # The jsvc implementation to use. Jsvc is required to run secure datanodes # that bind to privileged ports to provide authentication of data transfer # protocol. Jsvc is not required if SASL is configured for authentication of # data transfer protocol using non-privileged ports. #export JSVC_HOME=${JSVC_HOME} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler. for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do if [ "$HADOOP_CLASSPATH" ]; then export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f else export HADOOP_CLASSPATH=$f fi done # The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE="" # Extra Java runtime options. Empty by default. export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS" #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS" # On secure datanodes, user to run the datanode as after dropping privileges. # This **MUST** be uncommented to enable secure HDFS if using privileged ports # to provide authentication of data transfer protocol. This **MUST NOT** be # defined if SASL is configured for authentication of data transfer protocol # using non-privileged ports. export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} # Where log files are stored. $HADOOP_HOME/logs by default. #export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER # Where log files are stored in the secure data environment. export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER} ### # HDFS Mover specific parameters ### # Specify the JVM options to be used when starting the HDFS Mover. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HADOOP_MOVER_OPTS="" ### # Advanced Users Only! ### # The directory where pid files are stored. /tmp by default. # NOTE: this should be set to a directory that can only be written to by # the user that will run the hadoop daemons. Otherwise there is the # potential for a symlink attack. export HADOOP_PID_DIR=${HADOOP_PID_DIR} export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER
core-site.xml
[root@hadoop-2 hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/mnt1/tmp,/mnt2/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>hadoop-3:2181,hadoop-2:2181,hadoop-5:2181</value> </property> <property> <name>fs.checkpoint.period</name> <value>3600</value> </property> </configuration>
3)hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop-1:9000</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop-1:50070</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop-4:9000</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop-4:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop-5:8485;hadoop-3:8485;hadoop-2:8485/ns1</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/mnt1/journaldata</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/mnt1/tmp/dfs/name,file:/mnt2/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/mnt1/tmp/dfs/data,file:/mnt2/tmp/dfs/data</value> </property> </configuration>
4)cat mapred-site.xml ( mv mapred-site.xml.template mapred-site.xml)
[root@hadoop-2 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5)yarn-site.xml
[root@hadoop-2 hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop-3</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop-5</value> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop-3:8032</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop-5:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop-3:8030</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop-5:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop-3:8031</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop-5:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>hadoop-3:8033</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>hadoop-5:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop-3:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop-5:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop-3:2181,hadoop-2:2181,hadoop-5:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
/etc/profile
[root@hadoop-2 hadoop]# cat /etc/profile # /etc/profile # System wide environment and startup programs, for login setup # Functions and aliases go in /etc/bashrc # It's NOT a good idea to change this file unless you know what you # are doing. It's much better to create a custom.sh shell script in # /etc/profile.d/ to make custom changes to your environment, as this # will prevent the need for merging in future updates. pathmunge () { case ":${PATH}:" in *:"$1":*) ;; *) if [ "$2" = "after" ] ; then PATH=$PATH:$1 else PATH=$1:$PATH fi esac } if [ -x /usr/bin/id ]; then if [ -z "$EUID" ]; then # ksh workaround EUID=`id -u` UID=`id -ru` fi USER="`id -un`" LOGNAME=$USER MAIL="/var/spool/mail/$USER" fi # Path manipulation if [ "$EUID" = "0" ]; then pathmunge /usr/sbin pathmunge /usr/local/sbin else pathmunge /usr/local/sbin after pathmunge /usr/sbin after fi HOSTNAME=`/usr/bin/hostname 2>/dev/null` HISTSIZE=1000 if [ "$HISTCONTROL" = "ignorespace" ] ; then export HISTCONTROL=ignoreboth else export HISTCONTROL=ignoredups fi export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL # By default, we want umask to get set. This sets it for login shell # Current threshold for system reserved uid/gids is 200 # You could check uidgid reservation validity in # /usr/share/doc/setup-*/uidgid file if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then umask 002 else umask 022 fi for i in /etc/profile.d/*.sh ; do if [ -r "$i" ]; then if [ "${-#*i}" != "$-" ]; then . "$i" else . "$i" >/dev/null fi fi done unset i unset -f pathmunge JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk PATH=$JAVA_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME export PATH export CLASSPATH export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:$PATH export JRE_HOME=$JAVA_HOME/jre export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3 export SPARK_HOME=/usr/local/spark/spark-2.2.1-bin-hadoop2.7 export MAVEN_HOME=/usr/local/hadoop-maven-3.39/apache-maven-3.3.9 export HBASE_HOME=/usr/local/hbase-1.2.4 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/sbin
Ⅱ 设置时区同步
配置时钟同步(NTP) 所有节点
timedatectl set-timezone Asia/Shanghai yum install -y ntp
这里选择节点1作为时钟同步源 修改ntp.conf文件修改如下部分
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap server 202.120.2.101 iburst(只留这一个,其他注释掉)
其他节点 ntp.conf
server hadoop-1 iburst(只留这一个,其他注释掉)
启动ntp
service ntpd start
ntpq -p
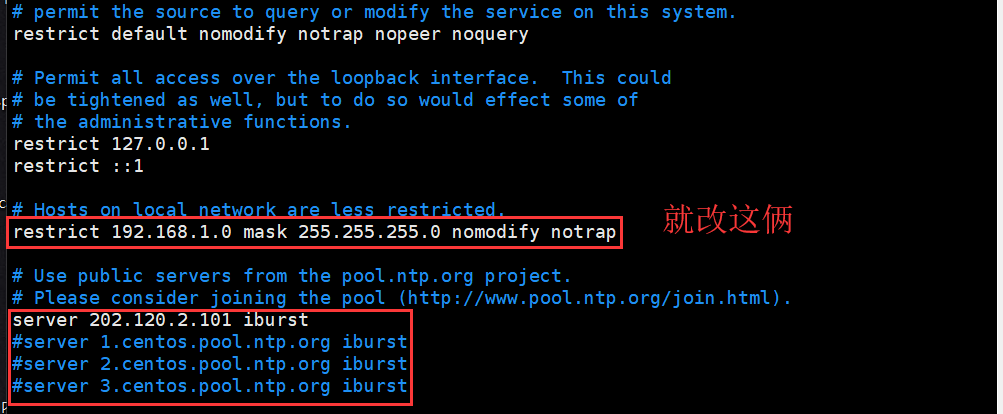
其余的节点改时图下

-----------------------------------------------------------------------------------------------------------------------
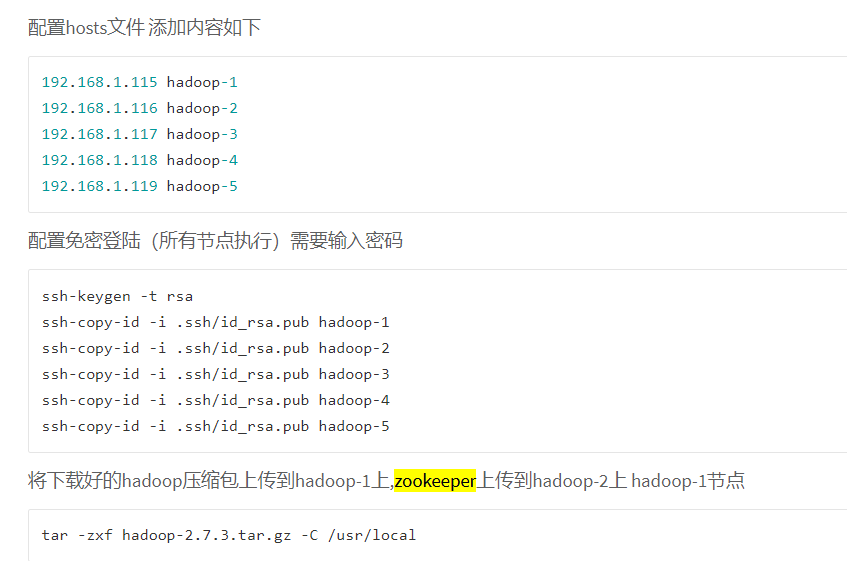
Ⅲ zookeeper配置 (复制一份 : cp zoo_sample.cfg zoo.cfg)。只装节点02,节点03,节点05.
修改zoo.cfg
加入以下部分
dataDir=/usr/local/zookeeper-3.4.8/data
dataLogDir=/usr/local/zookeeper-3.4.8/logs
server.1=weekend02:2888:3888
server.2=weekend03:2888:3888
server.3=weekend05:2888:3888