缘起
看到这样的数据:Marek Čech、Beniardá怎样变成相对应的ascii码呢
解决
import unicodedata s = u"Marek Čech" #(u表示是unicode而非 ascii码,不加报错!) line = unicodedata.normalize('NFKD',s).encode('ascii','ignore') print line
结果
Marek Cech
python 2.* 中文编码问题
问题要从文字的编码讲起。原本的英文编码只有0~255(28),刚好是8位1个字节。为了使计算机表示各种不同的语言,1个字节是大大不够的,自然要进行扩充。中文的话有GB系列、UTF-8,那么,它们之间是什么关系呢?
Unicode是一种编码方案,又称万国码,可见其包含之广。但是具体存储到计算机上,并不用这种编码,而是用自身默认的编码方式,utf-8是互联网上使用的最广的一种Unicode的实现方式。UTF-8或者gbk也可以进行解码(decode)还原为Unicode。
在python中Unicode是一类对象,表现为以u打头的,比如u'中文',而string又是一类对象,是在具体编码方式下的实际存在计算机上的字符串。比如utf-8编码下的'中文'和gbk编码下的汉字“中华”,并不相同。例如

设计python的几个函数
encode():编码
decode():解码
repr():返回一个可以用来表示对象的可打印的字串
默认编码问题
#coding: gbk str1 = '汗' print repr(str1) str2 = u'汗' print repr(str2) str3 = str2.encode('utf-8') str4 = str2.encode('gbk') print repr(str3) print repr(str4) str5 = str3.decode('utf-8') print repr(str5)
执行程序出现问题:

说gbk编码器不能解码。原因是何?看看自己的linux配置,用命令“locale”
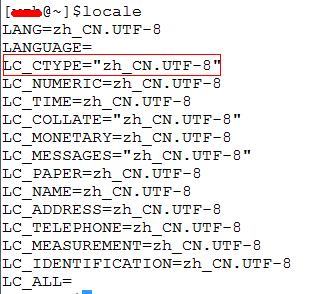
其中,与中文输入关系最密切的就是 LC_CTYPE, LC_CTYPE 规定了系统内有效的字符以及这些字符的分类,诸如什么是大写字母,小写字母,大小写转换,标点符号、可打印字符和其他的字符属性等方面。而locale定义zh_CN中最最重要的一项就是定义了汉字(Class “hanzi”)这一个大类,当然也是用Unicode描述的,这就让中文字符在Linux系统中成为合法的有效字符,而且不论它们是用什么字符集编码的。
简单说:程序中写了个str1 = '汗',默认编码是utf-8,当赋予变量str1的时候,因为此时设定的编码为gbk,驴唇不对马嘴,编码与解码不一致,导致解码错误。
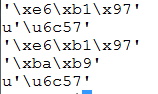
修改如下(左),结果(右)

延伸阅读:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html