信赖域策略优化(Trust Region Policy Optimization, TRPO)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
这篇博文是John S., Sergey L., Pieter A., Michael J., Philipp M., Trust Region Policy Optimization. Proceedings of the 32nd International Conference on Machine Learning, PMLR 37:1889-1897, 2015.的阅读笔记,用来介绍TRPO策略优化方法及其一些公式的推导。TRPO是一种基于策略梯度的强化学习方法,除了定理1没推导之外,其他公式的来龙去脉都进行了详细介绍,为后续进一步深入研究其他强化学习方法提供基础。更多强化学习内容,请看:随笔分类 - Reinforcement Learning。
1. 基础知识
KL散度 (Kullback–Leibler Divergence or Relative Entropy),总变差散度(Total Variation Divergence),以及KL散度与TV散度之间的关系(Pinsker’s inequality)

共轭梯度法(Conjugate Gradient Algorithm)

新旧策略期望折扣奖励差



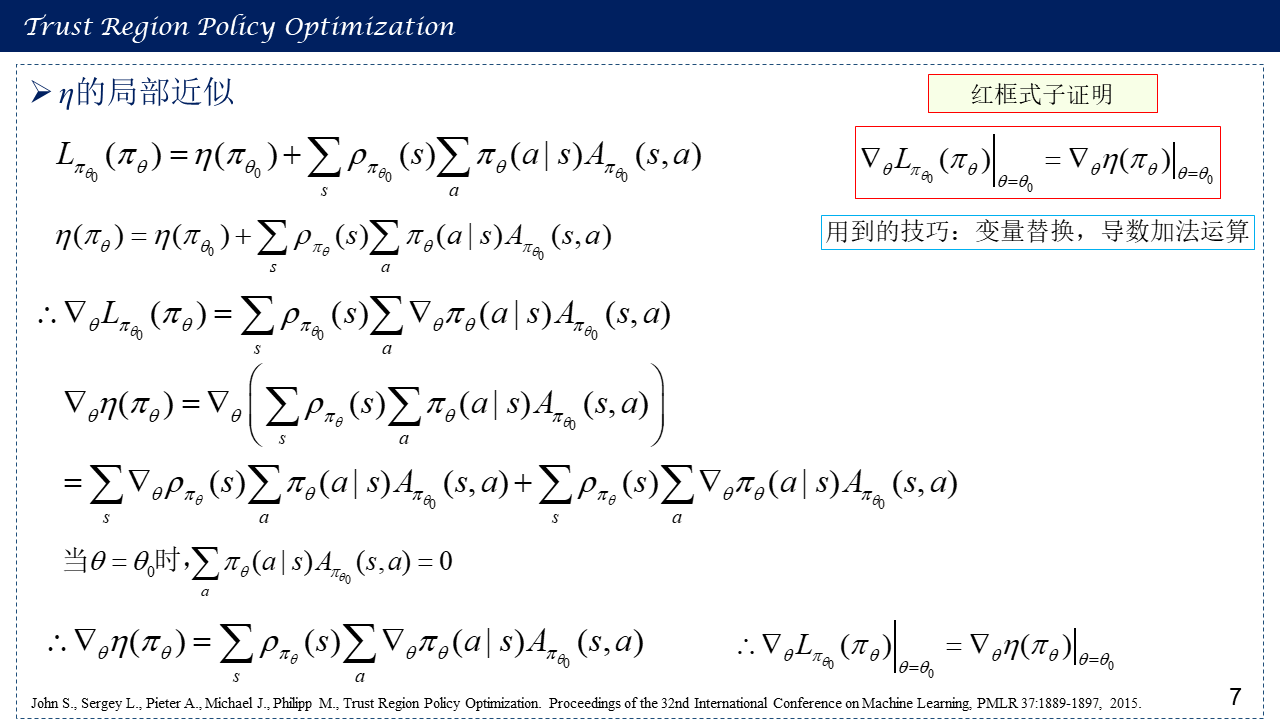
2. η的局部近似


3. 一般性随机策略的单调提升保证

4. 参数化策略的优化问题

5. Sample-Based Estimation of the Objective and Constraint

6. 约束优化问题的求解


7. 算法总体流程

8. 参考文献
[1] John S., Sergey L., Pieter A., Michael J., Philipp M., Trust Region Policy Optimization. Proceedings of the 32nd International Conference on Machine Learning, PMLR 37:1889-1897, 2015.
[2] Entropy and Information Theory, Robert M. Gray, http://www.cis.jhu.edu/~bruno/s06-466/GrayIT.pdf. Lemma 5.2.8 P88.
[3] Su G . On Choosing and Bounding Probability Metrics. International Statistical Review, 2002, 70(3). https://arxiv.org/pdf/math/0209021.pdf
[4] Concentration inequalities: A nonasymptotic theory of independence, http://home.ustc.edu.cn/~luke2001/pdf/concentration.pdf, Theorem 4.19, P103, Pinsker's inequality.
[5] J. Nocedal and S. J. Wright, Numerical optimization. New York, NY: Springer (2006; Zbl 1104.65059) http://www.apmath.spbu.ru/cnsa/pdf/monograf/Numerical_Optimization2006.pdf
[6] Kakade, Sham and Langford, John. Approximately optimal approximate reinforcement learning. In ICML, volume 2, pp. 267 274, 2002.
[7] Trust Region Policy Optimization https://spinningup.openai.com/en/latest/algorithms/trpo.html