页
从磁盘读取或者写入数据时,我们通常会指定一个缓冲区大小,达到缓冲区域大小才会写入一次数据,较少IO操作次数。同样的从磁盘读取数据时候,就操作系统而言,读取一条较小的数据时,并不是只会返回我们需要的数据,而是会将这个数据前后的部分数据一并读取到内存中,以备之后使用。这个从磁盘读取的最小量的数据被称为页,操作系统一页的大小是4K,而MySQL一页的大小为16k。每一次读取至少都是一页大小的数据。
数据储存
MySQL是一个行数据库,以一张表为例,当我定义好字段信息后,只需要按照字段约束一行行添加数据即可,每一条数据就是一行。为了方便查询,每一行数据都有一个唯一主键标识(自定义或者使用默认的row_id),并按照数据主键进行排序。排序的好处就是能够方便的快速查询,例如使用二分的手段,大大减少查询次数。而MySQL使用的手段的B+树索引,顾名思义,索引就是一个目录的存在。
数据是一页一页的被查询,而一页大小为16k,一行行记录在一个页中的管理大致如下:
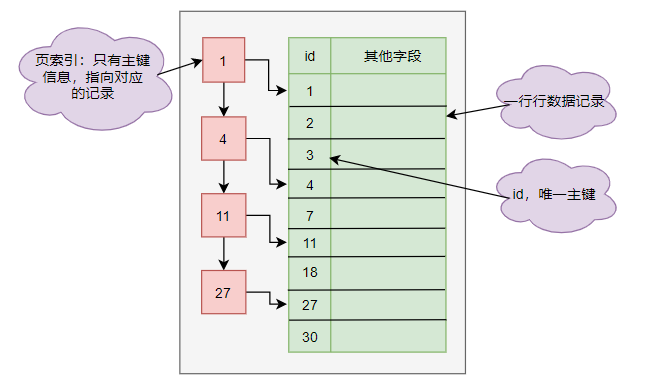
在这样一页中保存了10行数据(主要根据一行数据的大小而定),并建立一个页索引方便查询,查询时会先从页索查找,而不用直接遍历一个个页,减少查询次数。从上面的方式可以从页中查询数据,但是在大量的数据中如何定位一条数据的所在的页呢,这就需要使用B+树索引
B+树索引
主键索引
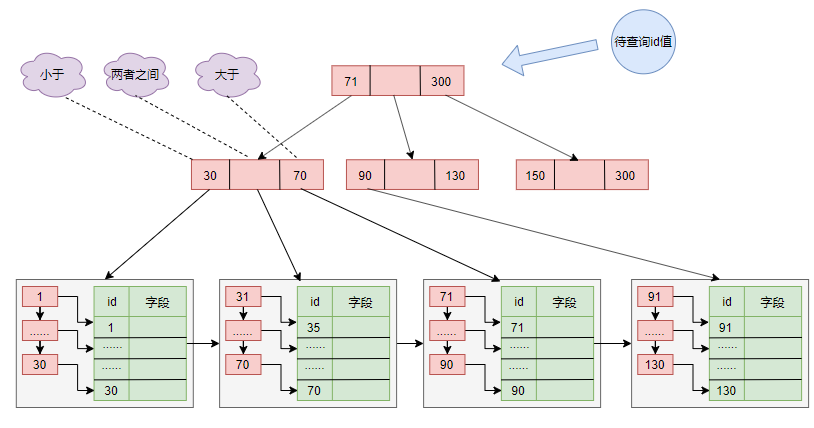
在索引的各个节点中,只会保存主键的id值,这通常是一个非常小的数字,所以一个16K的页通常就能保存这个二叉树的数据,这样就构成了一个索引页(目录页),这个索引页通常可以直接缓存在内存中的,当我们查询一个条数据时候,根据id值的与二叉树各个节点进行比较,只需要通过几次查询能找出数据所在的页位置,读取即可。
普通索引
除了主键索引的其他索引我们都将其看作普通索引,普通索引会将该索引列的值进行排序,在建立一个B+索引树,和主键的B+树不同的是,主键索引的叶子节点上的主键值直接关联行数据,而普通索引叶子节点关联的数据是主键的值,还需要再次通过主键进行查询。
通过主键直接可以找到这个主键关联的数据,而使用普通的索引,首先会找到目标数据的主键,在通过主键索引获取,需要进行一个回表的操作。当然,如果想要查询的数据在可以在这个普通索引的叶子节点中就包含,则不需要回表,而是直接索引覆盖。
例如有5个字段,a,b,c,d,e,a为主键,b为普通索引。如果使用select a,b,c from table where b=1,首先会使用b字段的索引找到对应数据的主键,在通过主键查询到数据中的a,b,c字段各自的值。这就需要一个个回表操作。而使用select a,b from table where b=1 查询时,我们只需要a,b两个字段的数据,首先依然通过字段b的索引查找主键,找到后,由于b字段和主键值已经得到,将不会再根据主键去找到全部数据,从而避免了回表操作,加快了查询速度。
唯一索引
唯一索引在普通索引的基础上对索引增加了唯一值约束,要求索引列的值必须唯一。在插入数据时候,会查询通过比较保证该值是唯一的,由于比较的操作,每次插入或者更新数据就必须读取磁盘中的数据进行比较,然后将数据进行写入。而普通索引在插入数据时,并不会直接插入数据,而是先将本次插入写入内存中的change buffer,等待写入的数据足够多时候,才会正真到磁盘中写入数据。这样在大量的写操作时,比唯一索引更加有效率。而每次读取数据时候,读取的数据需要同change buffer中的内容进行一次merge操作,所以在大量读取的情况下,反而增加change bufffer的维护成本。
联合索引
联合索引是指使用多个字段联合建立索引,例如有5个字段,a,b,c,d,e,使用cde字段联合建立一个索引。同样的,将三个字段的值合并到一起进行排序,然后建立索引B+树,叶子节点关联主键值。联合索引建立和多个字段的指定顺序有关,当使用这个联合索引查询时,需要优先使用第一个字段进行匹配,如果第一个字段不存在,查询过程中无法通过二叉树的比较快速定位数据,只能通过全表扫描的方式。使用普通索引时候,如果不是唯一索引,那么可能再b+树的节点中会出现重复的值,为了区分,重复的值会带上主键值以示区分。保证数据按照规则排序。