又到了无聊的写博客的时间了,因为电脑在跑程序。眼下无事可做。我认为把昨天我看的一些论文方面的知识拿出来和大家分享一下。
美其名曰我是在研究”深度学习“。只是因为本人是穷屌丝一个,买不起GPU(当然明年我准备入手一块显卡来玩玩),因此这半年我找了个深度学习中的一个”廉价“的方向——PCANet。
首先给出PCANet的原始文献《PCANet:A Simple Deep Learning Baseline for Image Classification》。这时在稀疏表示大牛Ma Yi的主页上看到的,当时眼前一亮。认为这个确实不错。这个分享一些相关资源:
(1)原始文档以及源代码:PCANet的Homepage
(2)C++版PCANet源代码:C++版PCANet
(3)原始文档的中文翻译:PCANet中文版
稍后我会将源代码具体解释总结为博客与大家分享。
当然,在这篇文章中我并不打算在反复去解释PCANet相关的一些知识(网上已经有非常多类似的博客),写这篇博客的目的是由于昨天我看到了PCANet的前身:Deep PCA,相应文献的名称为:《Face Recognition Using Deep PCA》,这篇文章网上应该非常easy找到,当然也能够直接在以下留言或者发邮件,我看到之后会及时把论文发给大家。
没错,当我看到Deep PCA时。第一印象就是”这是PCANet的老爸“。接下来我们具体的对照分析一下这两个方法。
1、网络结构
Deep PCA结构例如以下:

PCANet结构例如以下:
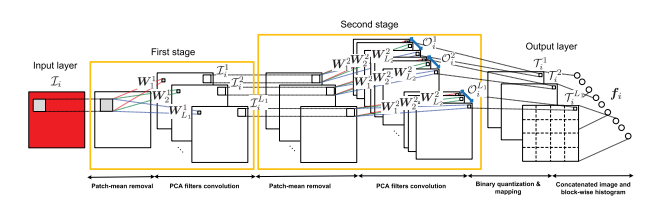
接下来简单分析一下两者的异同:
(1)两者网络冊数同样。都是一个双层网络
(2)所用分类器同样。两者在终于分类器的选择上都不约而同的选择了K近邻分类器(KNN),一个非常重要的原因是他们都通过单训练样本来进行的分类。
(3)每层的滤波器个数不同。Deep PCA每层都仅仅有一个滤波器,PCANet第一层有八个滤波器。第二层也是八个滤波器(也就是PCA映射核。原文献中有明白说明)。
(4)特征提取手段不同。Deep PCA将第一层和第二层的特征融合后作为提取到的特征。相当于进行了层间特征融合。而PCANet仅仅使用了第二层的输出特征作为提取到的深度特征。没有层间特征融合的思想。
2、算法流程
在算法设计方面Deep PCA要比PCANet简单很多,因此我们重点描写叙述PCANet的算法流程。然后在针对他们之间的差异进行讨论。PCANet的算法流程例如以下:

具体的算法描写叙述參见PCANet中文版。这里概括的描写叙述一下关键算法流程。首先是第一层的PCA映射分解:

然后是在第二层,以第一层的输出为输入,再次进行一次PCA映射分解:

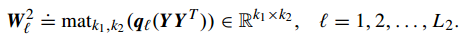
然后取第二层的映射输出,进行哈希编码:
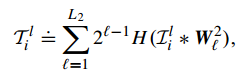
然后进行直方图编码。作为特征输出:

以上是PCANet的算法流程。接下来我们介绍Deep PCA的算法流程:
首先对训练样本进行ZCA白化:
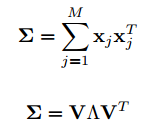


然后在第一层,进行一次PCA映射:
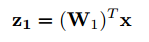
然后在第二层。以第一层的结果为输出。再次进行一次PCA映射:

然后将两次映射的结果融合成特征向量进行输出。特征提取完毕。
分析一下两者在算法层面上的异同点:
(1)预处理方面。Deep PCA首先对训练样本进行了ZCA白化。而PCANet则没有这一步处理过程。
(2)Deep PCA用的是传统的一维PCA。而PCANet则是使用了2DPCA(这点很重要)。
(3)Deep PCA直接将映射结果作为了特征。而PCANet则是将得到的特征先进行哈希编码,再直方图分块编码后,再进行的特征输出,这也造成了两者在输出特征的维数上产生了巨大差异,Deep PCA第一层和第二层分别为500维和150维,而PCANet的特征输出则高达几十万维。
以上就是Deep PCA和PCANet的一些异同点。之前在读论文时感觉这个有点价值,就顺手写了出来。并且在写这篇博客时我貌似有点发烧。并且还恰好被老师批评了一通。因此语言表达可能不到位,可能有几个错别字,大家见谅。