文本操作大杀器,开发必备
一、grep
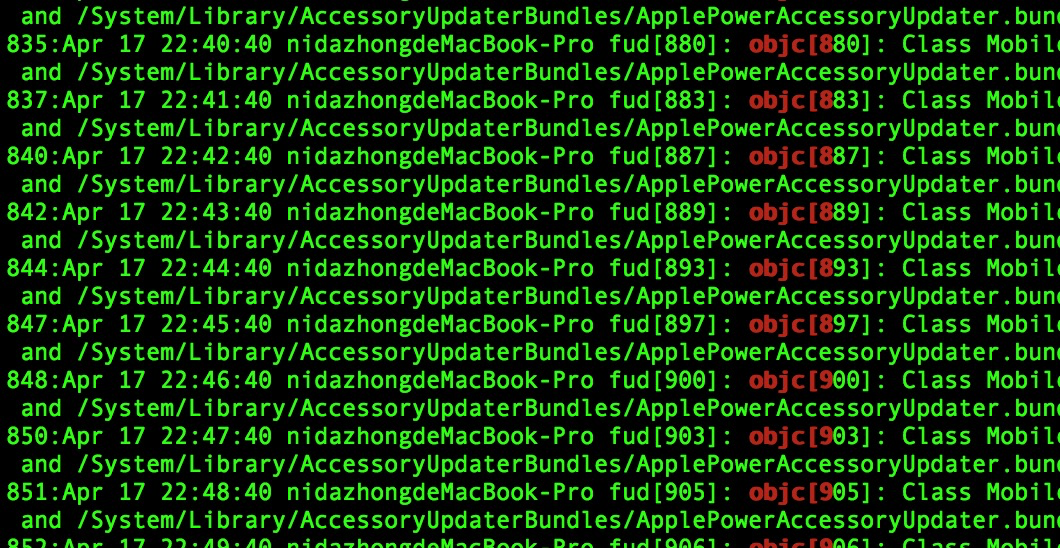
1、#显示system.log 匹配 有objc[8或objc[9 的文本信息 ,其中[为转义,-n显示行号,[89]里面无论有多少字节,都会是一个字节,示例图如下
$ grep -n --color=auto 'objc[[89]' system.log
1.1、#正则中加个^,则正好反过来
$ grep -n --color=auto 'objc[[^89]' system.log
1、统计匹配项出现的行数
$ ifconfig | grep -c "en"
2、统计匹配项的数量
$ echo -e "1 2 3 4
hello
5 6" | egrep -o "[0-9]" | wc -l
3、打印匹配项出现的行号
$ ifconfig | grep "inet" -n
4、打印字符或字节出现的index(mac无效,仅linux)
$ echo gnu is not unix | grep -b -o "not"
5、匹配多个样式 -e
$ echo this is a line of text | grep -e "this" -e "line" -o
6、忽略大小写 -i
echo hello world | grep -i "HELLO"
7、递归搜索文件中的内容 --include 指定从哪些文件中匹配
$ grep "main()" . -r --include *.{c,cpp}
8、删除内容匹配有test字符的文件,文件以file开头,xargs 将文件名传递给rm (仅linux)
#准备测试文件
$ echo "test" > file1
$ echo "cool" > file2
$ echo "test" > file3
#执行命令
$ grep "test" file* -lZ | xargs -0 rm
9、打印匹配结果的后三行
$ seq 10 | grep 5 -A 3
二、awk
awk [options] 'pattern{action}' file
#awk
1、脚本结构 BEGIN{ print "start" } 只执行一次,可省略,BEGIN{ print "start" } 有多少行执行多少次,默认{print} ,END{ print "end" } 在结束时执行,也只执行一次
awk ' BEGIN{ print "start" } pattern { commands } END{ print "end" } file
#举例
$ echo -e "line1
line2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" } '
2、统计文件行数
$ awk 'END{ print NR }' file
3、传递外部变量给awk
$ VAR=10000
$ echo |awk -v VARIABLE=$VAR '{print VARIABLE}'
三、sed
1、搜索Apr全部替换Fri 并将源文件备份
$ sed -i '.bak' 's/Apr/Fri/g' test.log
#sed
1、从第2处匹配开始替换 2g(仅linux) /g没有数字 将替换所有
$ echo thisthisthisthis | sed 's/this/THIS/2g'
2、移除空白行,会打印出移初后的内容,并不会替换编辑原文件 (想要直接替换调原文件就加 -i 选项)
sed '/^$/d' file1.txt
3、匹配到任意单词然后用[]包裹替换
$ echo this is an example | sed 's/w+/[&]/g'
4、 子串匹配标记(1,是匹配第一个子串),digit 7 替换成7 ,([0-9])是匹配子串
echo this is digit 7 in a number | sed "s/digits([0-9])/1/"
5、组合多个表达式
$ echo abc | sed -e 's/a/A/' -e 's/c/C/'
6、引用
$ text=hello
$ echo hello world | sed "s/$text/HELLO/"
HELLO world