此文章理论部分内容大多数摘自网站 开心技术园 的一篇文章,但并做了一些修改与调整。理论部分原文链接:图文并茂 RAID 技术全解 – RAID0、RAID1、RAID5、RAID100……
本文实验部分,完全由本人亲自动手实践得来
文章中有部分的内容是我个人通过实验测试出来的,虽以目前本人的能力还没发现不通之处,但错误难免,所以若各位朋友发现什么错误,或有疑惑、更好的建议等,盼请各位能在评论区不吝留下宝贵笔迹。最后,希望各位能读有所获。
实验环境
[Allen@Centos7 ~]$ uname -r
3.10.0-693.el7.x86_64
[Allen@Centos7 ~]$ cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
1. RAID概述
RAID(RedundantArrayofIndependentDisks)即独立磁盘冗余阵列,通常简称为磁盘阵列。简单地说,RAID是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。RAID是一类多磁盘管理技术,其向主机环境提供了成本适中、数据可靠性高的高性能存储。
RAID主要利用数据条带、镜像和数据校验技术来获取高性能、可靠性、容错能力和扩展性,根据运用或组合运用这三种技术的策略和架构,可以把RAID分为不同的等级,以满足不同数据应用的需求。D.A.Patterson等的论文中定义了RAID1RAID5原始RAID等级,1988年以来又扩展了RAID0和RAID6。近年来,存储厂商不断推出诸如RAID7、RAID10/01、RAID50、RAID53、RAID100等RAID等级,但这些并无统一的标准。目前业界公认的标准是RAID0RAID5,除RAID2外的四个等级被定为工业标准,而在实际应用领域中使用最多的RAID等级是RAID0、RAID1、RAID3、RAID5、RAID6和RAID10。
从实现角度看,RAID主要分为软RAID、硬RAID以及软硬混合RAID三种。软RAID所有功能均有操作系统和CPU来完成,没有独立的RAID控制/处理芯片和I/O处理芯片,效率自然最低。硬RAID配备了专门的RAID控制/处理芯片和I/O处理芯片以及阵列缓冲,不占用CPU资源,但成本很高。软硬混合RAID具备RAID控制/处理芯片,但缺乏I/O处理芯片,需要CPU和驱动程序来完成,性能和成本在软RAID和硬RAID之间。
RAID 每一个等级代表一种实现方法和技术,等级之间并无高低之分。在实际应用中,应当根据用户的数据应用特点,综合考虑可用性、性能和成本来选择合适的 RAID 等级,以及具体的实现方式。
2. RAID基本原理
RAID的两个关键目标是提高数据可靠性和I/O性能。磁盘阵列中,数据分散在多个磁盘中,然而对于计算机系统来说,就像一个单独的磁盘。通过把相同数据同时写入到多块磁盘(典型地如镜像),或者将计算的校验数据写入阵列中来获得冗余能力,当单块磁盘出现故障时可以保证不会导致数据丢失。
磁盘阵列可以在部分磁盘(单块或多块,根据实现而论)损坏的情况下,仍能保证系统不中断地连续运行。在重建故障磁盘数据至新磁盘的过程中,系统可以继续正常运行,但是性能方面会有一定程度上的降低。一些磁盘阵列在添加或删除磁盘时必须停机,而有些则支持热交换(HotSwapping),允许不停机下替换磁盘驱动器。这种高端磁盘阵列主要用于要求高可能性的应用系统,系统不能停机或尽可能少的停机时间。一般来说,RAID不可作为数据备份的替代方案,它对非磁盘故障等造成的数据丢失无能为力,比如病毒、人为破坏、意外删除等情形。此时的数据丢失是相对操作系统、文件系统、卷管理器或者应用系统来说的,对于RAID系统来身,数据都是完好的,没有发生丢失。所以,数据备份、灾备等数据保护措施是非常必要的,与RAID相辅相成,保护数据在不同层次的安全性,防止发生数据丢失。
RAID中主要有三个关键概念和技术:镜像(Mirroring)、数据条带(DataStripping)和数据校验(Dataparity)[3][4][5]。镜像,将数据复制到多个磁盘,一方面可以提高可靠性,另一方面可并发从两个或多个副本读取数据来提高读性能。显而易见,镜像的写性能要稍低,确保数据正确地写到多个磁盘需要更多的时间消耗。数据条带,将数据分片保存在多个不同的磁盘,多个数据分片共同组成一个完整数据副本,这与镜像的多个副本是不同的,它通常用于性能考虑。数据条带具有更高的并发粒度,当访问数据时,可以同时对位于不同磁盘上数据进行读写操作,从而获得非常可观的I/O性能提升。数据校验,利用冗余数据进行数据错误检测和修复,冗余数据通常采用海明码、异或操作等算法来计算获得。利用校验功能,可以很大程度上提高磁盘阵列的可靠性、鲁棒性和容错能力。不过,数据校验需要从多处读取数据并进行计算和对比,会影响系统性能。不同等级的RAID采用一个或多个以上的三种技术,来获得不同的数据可靠性、可用性和I/O性能。至于设计何种RAID(甚至新的等级或类型)或采用何种模式的RAID,需要在深入理解系统需求的前提下进行合理选择,综合评估可靠性、性能和成本来进行折中的选择。
总体说来,RAID主要优势有如下几点:
- 大容量
- 这是RAID的一个显然优势,它扩大了磁盘的容量,多个磁盘组成的RAID系统具有海量的存储空间,一般来说,RAID可用容量要小于所有成员磁盘的总容量。如果已知RAID算法和容量,可以计算出RAID的可用容量。通常,RAID容量利用率在50%~90%之间。
- 高性能
- RAID的高性能受益于数据条带化技术。单个磁盘的I/O性能受到接口、带宽等计算机技术的限制,性能往往很有限,容易成为系统性能的瓶颈。通过数据条带化,RAID将数据I/O分散到各个成员磁盘上,从而获得比单个磁盘成倍增长的聚合I/O性能。
- 可靠性
- RAID采用镜像和数据校验等数据冗余技术。镜像是最为原始的冗余技术,把某组磁盘驱动器上的数据完全复制到另一组磁盘驱动器上,保证总有数据副本可用。比起镜像50%的冗余开销,数据校验要小很多,它利用校验冗余信息对数据进行校验和纠错。RAID冗余技术大幅提升数据可用性和可靠性,保证了若干磁盘出错时,不会导致数据的丢失,不影响系统的连续运行。
- 可管理性
- 实际上,RAID是一种虚拟化技术,它对多个物理磁盘驱动器虚拟成一个大容量的逻辑驱动器。对于外部主机系统来说,RAID是一个单一的、快速可靠的大容量磁盘驱动器。RAID可以动态增减磁盘驱动器,可自动进行数据校验和数据重建,这些都可以大大简化管理工作。
3. 关键技术
3.1 镜像
镜像是一种冗余技术,为磁盘提供保护功能,防止磁盘发生故障而造成数据丢失。对于RAID而言,采用镜像技术典型地将会同时在阵列中产生两个完全相同的数据副本,分布在两个不同的磁盘驱动器组上。镜像提供了完全的数据冗余能力,当一个数据副本失效不可用时,外部系统仍可正常访问另一副本,不会对应用系统运行和性能产生影响。而且,镜像不需要额外的计算和校验,故障修复非常快,直接复制即可。镜像技术可以从多个副本进行并发读取数据,提供更高的读I/O性能,但不能并行写数据,写多个副本会会导致一定的I/O性能降低。
镜像技术提供了非常高的数据安全性,其代价也是非常昂贵的,需要至少双倍的存储空间。高成本限制了镜像的广泛应用,主要应用于至关重要的数据保护,这种场合下数据丢失会造成巨大的损失。另外,镜像通过“拆分”能获得特定时间点的上数据快照,从而可以实现一种备份窗口几乎为零的数据备份技术。
3.2 数据条带
磁盘存储的性能瓶颈在于磁头寻道定位,它是一种慢速机械运动,无法与高速的CPU匹配。再者,单个磁盘驱动器性能存在物理极限,I/O性能非常有限。RAID由多块磁盘组成,数据条带技术将数据以块的方式分布存储在多个磁盘中,从而可以对数据进行并发处理。这样写入和读取数据就可以在多个磁盘上同时进行,并发产生非常高的聚合I/O,有效提高了整体I/O性能,而且具有良好的线性扩展性。这对大容量数据尤其显著,如果不分块,数据只能按顺序存储在磁盘阵列的磁盘上,需要时再按顺序读取。而通过条带技术,可获得数倍与顺序访问的性能提升。
数据条带技术的分块大小选择非常关键。条带粒度可以是一个字节至几KB大小,分块越小,并行处理能力就越强,数据存取速度就越高,但同时就会增加块存取的随机性和块寻址时间。实际应用中,要根据数据特征和需求来选择合适的分块大小,在数据存取随机性和并发处理能力之间进行平衡,以争取尽可能高的整体性能。
数据条带是基于提高I/O性能而提出的,也就是说它只关注性能,而对数据可靠性、可用性没有任何改善。实际上,其中任何一个数据条带损坏都会导致整个数据不可用,采用数据条带技术反而增加了数据发生丢失的概念率。
3.3 数据校验
镜像具有高安全性、高读性能,但冗余开销太昂贵。数据条带通过并发性来大幅提高性能,然而对数据安全性、可靠性未作考虑。数据校验是一种冗余技术,它用校验数据来提供数据的安全,可以检测数据错误,并在能力允许的前提下进行数据重构。相对镜像,数据校验大幅缩减了冗余开销,用较小的代价换取了极佳的数据完整性和可靠性。数据条带技术提供高性能,数据校验提供数据安全性,RAID不同等级往往同时结合使用这两种技术。
采用数据校验时,RAID要在写入数据同时进行校验计算,并将得到的校验数据存储在RAID成员磁盘中。校验数据可以集中保存在某个磁盘或分散存储在多个不同磁盘中,甚至校验数据也可以分块,不同RAID等级实现各不相同。当其中一部分数据出错时,就可以对剩余数据和校验数据进行反校验计算重建丢失的数据。校验技术相对于镜像技术的优势在于节省大量开销,但由于每次数据读写都要进行大量的校验运算,对计算机的运算速度要求很高,必须使用硬件RAID控制器。在数据重建恢复方面,检验技术比镜像技术复杂得多且慢得多。
海明校验码和异或校验是两种最为常用的数据校验算法。海明校验码是由理查德.海明提出的,不仅能检测错误,还能给出错误位置并自动纠正。海明校验的基本思想是:将有效信息按照某种规律分成若干组,对每一个组作奇偶测试并安排一个校验位,从而能提供多位检错信息,以定位错误点并纠正。可见海明校验实质上是一种多重奇偶校验。异或校验通过异或逻辑运算产生,将一个有效信息与一个给定的初始值进行异或运算,会得到校验信息。如果有效信息出现错误,通过校验信息与初始值的异或运算能还原正确的有效信息。
RAID实现了什么:
- 提高IO能力:
- 磁盘并行读写
- 提高可靠性:
- 磁盘冗余来实现
有了RAID还用做数据备份么?
需要做的,因为raid只能防止磁盘故障,在磁盘故障的时候
RAID实现的方式:
- 硬件RAID
- 外接式的磁盘阵列:通过扩展卡提供适配能力
- 内接式RAID:主板集成RAID控制器
- Software RAID
- 软硬混合RAID
4. RAID等级
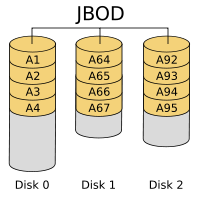
4.1 JBOD
JBOD(JustaBunchOfDisks)不是标准的RAID等级,它通常用来表示一个没有控制软件提供协调控制的磁盘集合。JBOD将多个物理磁盘串联起来,提供一个巨大的逻辑磁盘。JBOD(如图)的数据存放机制是由第一块磁盘开始按顺序往后存储,当前磁盘存储空间用完后,再依次往后面的磁盘存储数据。JBOD存储性能完全等同于单块磁盘,而且也不提供数据安全保护。它只是简单提供一种扩展存储空间的机制,JBOD可用存储容量等于所有成员磁盘的存储空间之和。目前JBOD常指磁盘柜,而不论其是否提供RAID功能。
4.2 标准RAID等级
SNIA、Berkeley等组织机构把RAID0、RAID1、RAID2、RAID3、RAID4、RAID5、RAID6七个等级定为标准的RAID等级,这也被业界和学术界所公认。标准等级是最基本的RAID配置集合,单独或综合利用数据条带、镜像和数据校验技术。标准RAID可以组合,即RAID组合等级,满足对性能、安全性、可靠性要求更高的存储应用需求。[6][7][8][9][10][11]
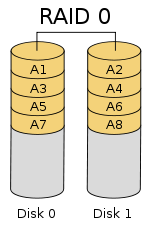
4.2.1 RAID0
RAID0是一种简单的、无数据校验的数据条带化技术。实际上不是一种真正的RAID,因为它并不提供任何形式的冗余策略。RAID0将所在磁盘条带化后组成大容量的存储空间(如图所示),将数据分散存储在所有磁盘中,以独立访问方式实现多块磁盘的并读访问。由于可以并发执行I/O操作,总线带宽得到充分利用。再加上不需要进行数据校验,RAID0的性能在所有RAID等级中是最高的。理论上讲,一个由n块磁盘组成的RAID0,它的读写性能是单个磁盘性能的n倍,但由于总线带宽等多种因素的限制,实际的性能提升低于理论值。
RAID0具有低成本、高读写性能、100%的高存储空间利用率等优点,但是它不提供数据冗余保护,一旦数据损坏,将无法恢复。因此,RAID0一般适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频、音频存储、临时数据缓存空间等。
- 读性能:提升N-1倍(理论上)
- 写性能:提升N-1倍(理论上)
- 可用空间:N块硬盘中最小的硬盘空间 * N
- 容错能力:无
- 最少磁盘数:2个,支持2个以上(在linux上使用mdadm做软RAID,需要使用--force才可以创建1块硬盘的RAID0)
- 是否支持空闲盘:不支持
4.2.2 RAID1
RAID1称为镜像,它将数据完全一致地分别写到工作磁盘和镜像磁盘,它的磁盘空间利用率为50%。RAID1在数据写入时,响应时间会有所影响,但是读数据的时候没有影响。RAID1提供了最佳的数据保护,一旦工作磁盘发生故障,系统自动从镜像磁盘读取数据,不会影响用户工作。工作原理如图所示。
RAID1与RAID0刚好相反,是为了增强数据安全性使两块磁盘数据呈现完全镜像,从而达到安全性好、技术简单、管理方便。RAID1拥有完全容错的能力,但实现成本高。RAID1应用于对顺序读写性能要求高以及对数据保护极为重视的应用,如对邮件系统的数据保护。

- 读性能:提升N-1倍(理论上)
- 写性能:没有提升,可能还会有所下降,速度取决于N块硬盘中速度最慢的那一块。
- 可用空间:N块硬盘中最小的硬盘空间 * 1
- 容错能力:N-1块
- 最少磁盘数:2个,支持2个以上(在linux上使用mdadm做软RAID,需要使用--force才可以创建1块硬盘的RAID1)
- 是否支持空闲盘:支持
4.2.3 RAID4
RAID4与RAID3的原理大致相同,区别在于条带化的方式不同。RAID4按照块的方式来组织数据,写操作只涉及当前数据盘和校验盘两个盘,多个I/O请求可以同时得到处理,提高了系统性能。RAID4按块存储可以保证单块的完整性,可以避免受到其他磁盘上同条带产生的不利影响。
RAID4在不同磁盘上的同级数据块同样使用XOR校验,结果存储在校验盘中。写入数据时,RAID4按这种方式把各磁盘上的同级数据的校验值写入校验盘,读取时进行即时校验。因此,当某块磁盘的数据块损坏,RAID4可以通过校验值以及其他磁盘上的同级数据块进行数据重建。假如所要读取的数据块正好位于失效磁盘,则系统需要读取所有同一条带的数据块,并根据校验值重建丢失的数据,提供给系统使用(这种工作模式叫做降级工作模式,不光读取,其实写也是可以的,只不过风险太大),系统性能将受到影响。当故障磁盘被更换后,系统按相同的方式重建故障盘中的数据至新磁盘。
RAID4提供了非常好的读性能,但单一的校验盘往往成为系统性能的瓶颈。对于写操作,RAID4只能一个磁盘一个磁盘地写,并且还要写入校验数据,因此写性能比较差。而且随着成员磁盘数量的增加,校验盘的系统瓶颈将更加突出。正是如上这些限制和不足,RAID4在实际应用中很少见,主流存储产品也很少使用RAID4保护。

- 读性能:提升N-2倍
- 写性能:提升N-2倍。(使用专门的硬盘做校验盘,不论哪块硬盘读取数据,都需要访问校验盘,所以校验盘的访问压力最大,是性能瓶颈)
- 可用空间:N块硬盘中最小的硬盘空间 * (N-1)
- 容错能力:1块
- 独立校验盘:是
- 最少磁盘数:3个,支持3个以上
- 是否支持空闲盘:支持
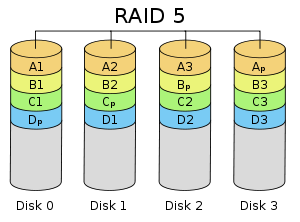
4.2.4RAID5
RAID5应该是目前最常见的RAID等级,它的原理与RAID4相似,区别在于校验数据分布在阵列中的所有磁盘上,而没有采用专门的校验磁盘。对于数据和校验数据,它们的写操作可以同时发生在完全不同的磁盘上。因此,RAID5不存在RAID4中的并发写操作时的校验盘性能瓶颈问题。另外,RAID5还具备很好的扩展性。当阵列磁盘数量增加时,并行操作量的能力也随之增长,可比RAID4支持更多的磁盘,从而拥有更高的容量以及更高的性能。
RAID5的磁盘上同时存储数据和校验数据,数据块和对应的校验信息存保存在不同的磁盘上,当一个数据盘损坏时,系统可以根据同一条带的其他数据块和对应的校验数据来重建损坏的数据。与其他RAID等级一样,重建数据时,RAID5的性能会受到较大的影响。
RAID5兼顾存储性能、数据安全和存储成本等各方面因素,它可以理解为RAID0和RAID1的折中方案,是目前综合性能最佳的数据保护解决方案。RAID5基本上可以满足大部分的存储应用需求,数据中心大多采用它作为应用数据的保护方案。
- 读性能:提升N-2倍
- 写性能:提升N-2倍。(一块数据会被切分成N块,分别存放到N个硬盘上,其中有两块硬盘上存放的是校验,校验码会平均分布在N块硬盘上,所以说任意一块硬盘上都有数据和校验码,不会存在校验盘是性能瓶颈的问题)
- 可用空间:N块硬盘中最小的硬盘空间 * (N-1)
- 容错能力:1块
- 独立校验盘:否
- 最少磁盘数:3个,支持3个以上
- 是否支持空闲盘:支持
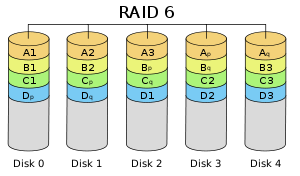
4.2.5 RAID-6
前面所述的各个RAID等级都只能保护因单个磁盘失效而造成的数据丢失。如果两个磁盘同时发生故障,数据将无法恢复。RAID6引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。RAID6等级是在RAID5的基础上为了进一步增强数据保护而设计的一种RAID方式,它可以看作是一种扩展的RAID5等级。
RAID6不仅要支持数据的恢复,还要支持校验数据的恢复,因此实现代价很高,控制器的设计也比其他等级更复杂、更昂贵。RAID6思想最常见的实现方式是采用两个独立的校验算法,假设称为P和Q,校验数据可以分别存储在两个不同的校验盘上,或者分散存储在所有成员磁盘中。当两个磁盘同时失效时,即可通过求解两元方程来重建两个磁盘上的数据。
RAID6具有快速的读取性能、更高的容错能力。但是,它的成本要高于RAID5许多,写性能也较差,并有设计和实施非常复杂。因此,RAID6很少得到实际应用,主要用于对数据安全等级要求非常高的场合。它一般是替代RAID10方案的经济性选择。
- 读性能:提升N-3倍
- 写性能:提升N-3倍。(一块数据会被切分成N块,分别存放到N个硬盘上,其中有两块硬盘上存放的是校验,校验码会平均分布在N块硬盘上,两块盘做校验盘,循环校验)
- 可用空间:N块硬盘中最小的硬盘空间 * (N-2)
- 容错能力:2块
- 独立校验盘:否
- 最少磁盘数:4个,支持4个以上
- 是否支持空闲盘:支持
4.3 RAID组合等级
标准RAID等级各有优势和不足。自然地,我们想到把多个RAID等级组合起来,实现优势互补,弥补相互的不足,从而达到在性能、数据安全性等指标上更高的RAID系统。目前在业界和学术研究中提到的RAID组合等级主要有RAID00、RAID01、RAID10、RAID100、RAID30、RAID50、RAID53、RAID60,但实际得到较为广泛应用的只有RAID01和RAID10两个等级。当然,组合等级的实现成本一般都非常昂贵,只是在少数特定场合应用。
4.3.1 RAID00
简单地说,RAID00是由多个成员RAID0组成的高级RAID0。它与RAID0的区别在于,RAID0阵列替换了原先的成员磁盘。可以把RAID00理解为两层条带化结构的磁盘阵列,即对条带再进行条带化。这种阵列可以提供更大的存储容量、更高的I/O性能和更好的I/O负均衡。
4.3.2 RAID01
RAID01是先做条带化再作镜像,本质是对物理磁盘实现镜像;

- 读性能:提升N-1倍
- 写性能:假设一共3组RAID0来做RAID1,每组RAID0中有2块硬盘,那就提升1倍;假设一共2组RAID0来做RAID1,每组RAID0中有3块硬盘,那就是提升2倍。所以说跟实际情况有关。
- 可用空间:N块硬盘中最小的硬盘空间 * 单组RAID0中硬盘数量
- 容错能力:假设有12块硬盘,5块硬盘为一组做RAID0,然后对两个RAID0做RAID1。在这种情况下,支持坏一个RAID0组。
- 有人会想,可不可以RAID0-A中坏第2块,RAID0-B中坏第3块,这样是不是也可以?
- 这种情况,看似没有问题,但是谁能确保,两组raid0的分片是一致的。
- 有人会想,可不可以RAID0-A中坏第2块,RAID0-B中坏第3块,这样是不是也可以?
- 独立校验盘:否
- 最少磁盘数:4个,支持4个以上(要分别满足RAID0和RAID1的硬盘数量要求)
- 是否支持空闲盘:支持
4.3.3 RAID10
而RAID10是先做镜像再作条带化,是对虚拟磁盘实现镜像。

- 读性能:提升N-1倍
- 写性能:假设一共3组RAID1来做RAID0,每组RAID1中有2块硬盘,那就提升2倍;假设一共2组RAID1来做RAID0,每组RAID1中有3块硬盘,那就是提升1倍。所以说跟实际情况有关。
- 可用空间:N块硬盘中最小的硬盘空间 * RAID1组的数量
- 容错能力:假设有12块硬盘,5块硬盘为一组做RAID1,然后对2个RAID1做RAID0。在这种情况下,每组RAID1最多可以坏4块硬盘,所以最多可以坏8块硬盘(2组RAID1总共),但是不同直接坏一组RAID1.
- 独立校验盘:否
- 最少磁盘数:4个,支持4个以上(要分别满足RAID0和RAID1的硬盘数量要求)
- 是否支持空闲盘:支持
4.3.4 RAID100
通常看作RAID1+0+0,有时也称为RAID10+0,即条带化的RAID10。原理如图所示。RAID100的缺陷与RAID10相同,任意一个RAID1损坏一个磁盘不会发生数据丢失,但是剩下的磁盘存在单点故障的危险。最顶层的RAID0,即条带化任务,通常由软件层来完成。
RAID100突破了单个RAID控制器对物理磁盘数量的限制,可以获得更高的I/O负载均衡,I/O压力分散到更多的磁盘上,进一步提高随机读性能,并有效降低热点盘故障风险。因此,RAID100通常是大数据库的最佳选择。
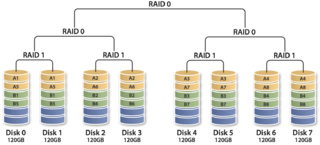
4.3.5 RAID30(RAID53)、RAID50和RAID60
这三种RAID等级与RAID00原理基本相同,区别在于成员“磁盘”换成了RAID3、RAID5和RAID6,分别如图11、12、13所示。其中,RAID30通常又被称为RAID53。其实,可把这些等级RAID统称为RAIDX0等级,X可为标准RAID等级,甚至组合等级(如RAID100)。利用多层RAID配置,充分利用RAIDX与RAID0的优点,从而获得在存储容量、数据安全性和I/O负载均衡等方面的大幅性能提升。
RAID30

RAID50
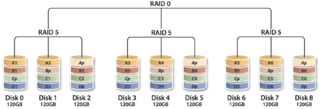
RAID60
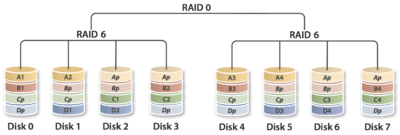
4.4 非标准RAID等级
4.4.1 RAID7
RAID7的全称是最优化的异步高I/O速率和高数据传输率,它与其他RAID等级有着明显区别。它不仅仅是一种技术,它还是一个独立存储计算机,自身带的操作系统和管理工具,完全可以独立运行。
RAID7的存储计算机操作系统是一套实时事件驱动操作系统,其主要用来进行系统初始化和安排RAID7磁盘阵列的所有数据传输,并把它们转换到相应的物理存储驱动器上。RAID7通过自身系统中的专用控制板来控制读写速度,存储计算机操作系统可使主机I/O传递性能达到最佳。如果一个磁盘出现故障,RAID7还能够自动执行恢复操作,并可管理备份磁盘的重建过程。
RAID7突破了以往RAID标准的技术架构,采用了非同步访问,极大地减轻了数据写瓶颈,提高了I/O速度。RAID7系统内置实时操作系统还可自动对主机发送过来的读写指令进行优化处理,以智能化方式将可能被读取的数据预先读入快速缓存中,从而大大减少了磁头的转动次数,提高存储系统的I/O速度。
RAID7可帮助用户有效地管理日益庞大的数据存储系统,并使系统的运行效率大大提高,满足不同用户的存储需求。但是,RAID7的成本比其他RAID等级要高许多。另外,RAID7已被某公司注册为商标,目前仅有一家公司提供RAID7的产品,用户没有更多的选择。技术封闭,缺乏主流专业存储厂商的参与和研发严重制约了RAID7的发展。
5. 实现方式
通常计算机功能既可以由硬件来实现,也可以由软件来实现。对于RAID系统而言,自然也不例外,它可以采用软件方式实现,也可以采用硬件方式实现,或者采用软硬结合的方式实现。
5.1 软RAID
软RAID没有专用的控制芯片和I/O芯片,完全由操作系统和CPU来实现所的RAID的功能。现代操作系统基本上都提供软RAID支持,通过在磁盘设备驱动程序上添加一个软件层,提供一个物理驱动器与逻辑驱动器之间的抽象层。目前,操作系统支持的最常见的RAID等级有RAID0、RAID1、RAID10、RAID01和RAID5等。比如,WindowsServer支持RAID0、RAID1和RAID5三种等级,Linux支持RAID0、RAID1、RAID4、RAID5、RAID6等,MacOSXServer、FreeBSD、NetBSD、OpenBSD、Solaris等操作系统也都支持相应的RAID等级。
软RAID的配置管理和数据恢复都比较简单,但是RAID所有任务的处理完全由CPU来完成,如计算校验值,所以执行效率比较低下,这种方式需要消耗大量的运算资源,支持RAID模式较少,很难广泛应用。
软RAID由操作系统来实现,因此系统所在分区不能作为RAID的逻辑成员磁盘,软RAID不能保护系统盘D。对于部分操作系统而言,RAID的配置信息保存在系统信息中,而不是单独以文件形式保存在磁盘上。这样当系统意外崩溃而需要重新安装时,RAID信息就会丢失。另外,磁盘的容错技术并不等于完全支持在线更换、热插拔或热交换,能否支持错误磁盘的热交换与操作系统实现相关,有的操作系统热交换。
5.2 硬RAID
硬RAID拥有自己的RAID控制处理与I/O处理芯片,甚至还有阵列缓冲,对CPU的占用率和整体性能是三类实现中最优的,但实现成本也最高的。硬RAID通常都支持热交换技术,在系统运行下更换故障磁盘。
硬RAID包含RAID卡和主板上集成的RAID芯片,服务器平台多采用RAID卡。RAID卡由RAID核心处理芯片(RAID卡上的CPU)、端口、缓存和电池4部分组成。其中,端口是指RAID卡支持的磁盘接口类型,如IDE/ATA、SCSI、SATA、SAS、FC等接口。
5.3 软硬混合RAID
软RAID性能欠佳,而且不能保护系统分区,因此很难应用于桌面系统。而硬RAID成本非常昂贵,不同RAID相互独立,不具互操作性。因此,人们采取软件与硬件结合的方式来实现RAID,从而获得在性能和成本上的一个折中,即较高的性价比。
这种RAID虽然采用了处理控制芯片,但是为了节省成本,芯片往往比较廉价且处理能力较弱,RAID的任务处理大部分还是通过固件驱动程序由CPU来完成。
6. Linux上软件实现RAID
Centos6/7上的软件RAID实现:
结合内核中的md(multi devices)
manage MD devices aka Linux Software RAID
6.1 madam:模式化工具
命令的语法格式:
madam [mode] <raiddevice> [options] <component-devices>
<raiddevice>:/dev/md#
<component-devices>:任意块设备
支持的RAID级别:LINEAR、RAID0、RAID1、RAID4、RAID5、RAID6、RAID10
模式:
创建一个新的阵列:-C
装配实现存在的阵列:-A
选择监控模式:-F
管理:-f,-r,-a
增长,更改活动阵列的大小和状态:-G
混合模式:
-S, --stop deactivate array, releasing all resources. ##停用阵列,释放所有资源
-D, --detail Print details of one or more md devices. ##打印一个或多个md设备的详细信息
--zero-superblock ##如果一个设备包含有效的md超级块信息,这个块信息会被零填充。加上--froce选项之后,即使块信息不是有效的md信息也会被零填充。 If the device contains a valid md superblock, the block is overwritten with zeros. With --force the block where the superblock would be is overwritten even if it doesn't appear to be valid.
创建模式OPTIONS
-n # ##使用#个块设备来创建此RAID(指定阵列的活动设备数量), 这里的数量加上热备设备必须等于 --create时在命令行列出的设备数量。
##该值设置为1时为错误,需要加上--force参数。创建linear, multipath, RAID0 and RAID1时可设置值为1,
##但是创建RAID4, RAID5 or RAID6时不可指定为1。
##如果内核支持,可以使用--grow选项为RAID1,RAID4,RAID5,RAID6增加磁盘数量
-l # ##指明要创建的RAID的级别
-e {yes|no} ##自动创建目标RAID设备的设备文件
-c CHUNK_SIZE ##指明块大小,指定块大小,默认为512KB。RAID4、5、6、10需要块大小为2的次方,大多数情况下必须是4KB的倍数,单位为K、M、G
-x # ##指定初始创建的阵列中热备盘的数量,后续可对热备盘添加或移除。
-a, --auto{=yes,md,mdp,part,p}{NN} ##如需要,指引mdadm如何创建设备文件,通常会配置一个未使用的设备编号。 ##如果在配置文件中或命令行中未给出--auto选项,默认情况下为--auto=yes.
-a, --add ##该选项在两种模式下可用在增长模式下
为指定模式的命令:
-s, --scan ##从配置文件或者/proc/mdstat中寻找丢失的md信息
管理模式:
-f ##把列出的设备标记故障
-a ##热添加列出的设备
-r ##移除列出的设备。其必须为非活动的。即为故障设备或热备设备。
观察md的状态
cat /proc/mdstat
停止md设备
mdadm -S /dev/md#
6.2 创建RAID
使用3块硬盘创建RAID5,外加1块热备盘,其chunk大小为4M,RAID设备名字是md0
NOTE:(盘的个数越多,浪费的空间就越少)
##创建的磁盘分区,必须转换成fd Linux raid auto(在fdisk中可通过t命令指定) ,否则的话可能不能用,即便是能用,也装载不了配置。
[root@m01 ~]# fdisk -l /dev/sdb
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x3a1866fc
Device Boot Start End Blocks Id System
/dev/sdb1 1 1305 10482381 5 Extended
/dev/sdb5 1 132 1060227 fd Linux raid autodetect
/dev/sdb6 133 264 1060258+ fd Linux raid autodetect
/dev/sdb7 265 396 1060258+ fd Linux raid autodetect
/dev/sdb8 397 528 1060258+ fd Linux raid autodetect
##使用3块硬盘创建RAID5,外加1块热备盘,其chunk大小为4M,RAID设备名字是md0
[root@m01 ~]# mdadm -C /dev/md0 -a yes -c 4M -n 3 -x 1 -l 5 /dev/sdb{5,6,7,8}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@m01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 200M 0 part /boot
├─sda2 8:2 0 2G 0 part [SWAP]
└─sda3 8:3 0 17.8G 0 part /
sdb 8:16 0 10G 0 disk
├─sdb1 8:17 0 1K 0 part
├─sdb5 8:21 0 1G 0 part
│ └─md0 9:0 0 2G 0 raid5
├─sdb6 8:22 0 1G 0 part
│ └─md0 9:0 0 2G 0 raid5
├─sdb7 8:23 0 1G 0 part
│ └─md0 9:0 0 2G 0 raid5
└─sdb8 8:24 0 1G 0 part
└─md0 9:0 0 2G 0 raid5
##查看raid信息信息
[root@m01 ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Aug 23 11:40:27 2018
Raid Level : raid5
Array Size : 2117632 (2.02 GiB 2.17 GB)
Used Dev Size : 1058816 (1034.00 MiB 1084.23 MB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Aug 23 11:40:40 2018
State : clean
Active Devices : 3 ##活动的设备
Working Devices : 4 ##工作的设备
Failed Devices : 0 ##错误的设备
Spare Devices : 1 ##空闲的设备
Layout : left-symmetric
Chunk Size : 4096K
Name : m01:0 (local to host m01)
UUID : d3a7f800:2d343092:11964718:0ead8c4c
Events : 18
Number Major Minor RaidDevice State
0 8 21 0 active sync /dev/sdb5
1 8 22 1 active sync /dev/sdb6
4 8 23 2 active sync /dev/sdb7
3 8 24 - spare /dev/sdb8
##做完raid之后
[root@m01 ~]# blkid | grep raid
/dev/sdb5: UUID="d3a7f800-2d34-3092-1196-47180ead8c4c" UUID_SUB="738affe4-0d75-f4e0-0e53-b0840c99db45" LABEL="m01:0" TYPE="linux_raid_member"
/dev/sdb6: UUID="d3a7f800-2d34-3092-1196-47180ead8c4c" UUID_SUB="758f7e71-0686-dcbc-9c54-4203ff42e9e8" LABEL="m01:0" TYPE="linux_raid_member"
/dev/sdb7: UUID="d3a7f800-2d34-3092-1196-47180ead8c4c" UUID_SUB="a2824c94-a3dc-40cd-59ff-52ebc7010d6f" LABEL="m01:0" TYPE="linux_raid_member"
/dev/sdb8: UUID="d3a7f800-2d34-3092-1196-47180ead8c4c" UUID_SUB="99a28761-0f9b-a1ab-def7-10b11312b3f8" LABEL="m01:0" TYPE="linux_raid_member"
##观察md的状态
[root@m01 ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md127 : active (auto-read-only) raid5 sdb5[0] sdb6[1] sdb7[4] sdb8[3](S)
2117632 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
##重启一次系统之后,发现md0这个名字变成了md127,所以说如果想要写入到/etc/fstab中,一定要使用UUID进行挂载
[root@m01 ~]# mkfs.ext4 /dev/md127
[root@m01 ~]# mount /dev/md127 /mnt/
[root@m01 ~]# df -h ##空间是1.9G,不是2G了,但是不用管,空间误差在10%以内都没啥问题
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 18G 1.7G 15G 11% /
tmpfs 364M 0 364M 0% /dev/shm
/dev/sda1 190M 32M 149M 18% /boot
/dev/md127 2.0G 3.1M 1.9G 1% /mnt
##将/dev/sdb6标记为损坏
[root@m01 ~]# mdadm /dev/md127 -f /dev/sdb6
mdadm: set /dev/sdb6 faulty in /dev/md127
[root@m01 ~]# cat /proc/mdstat ##可以看到磁盘正在revocery ,刚创建RAID的时候也会recovery一次
Personalities : [raid6] [raid5] [raid4]
md127 : active raid5 sdb5[0] sdb6[1](F) sdb7[4] sdb8[3]
2117632 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [U_U]
[====>................] recovery = 22.8% (242560/1058816) finish=0.1min speed=121280K/sec
##此时可以看到,sdb8顶上来了,sdb6被标记为错误
[root@m01 ~]# mdadm -D /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Thu Aug 23 14:00:33 2018
Raid Level : raid5
Array Size : 2117632 (2.02 GiB 2.17 GB)
Used Dev Size : 1058816 (1034.00 MiB 1084.23 MB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Aug 23 14:56:25 2018
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : m01:0 (local to host m01)
UUID : f8cd3a92:da0ef586:c11a4f1d:8887e949
Events : 39
Number Major Minor RaidDevice State
0 8 21 0 active sync /dev/sdb5
3 8 24 1 active sync /dev/sdb8
4 8 23 2 active sync /dev/sdb7
1 8 22 - faulty /dev/sdb6
##将sdb6移除,然后将sdb7标注为错误(不标记为错误直接移除的话显示Device or resource busy)
[root@m01 ~]# mdadm /dev/md127 -r /dev/sdb6
mdadm: hot removed /dev/sdb6 from /dev/md127
[root@m01 ~]# mdadm /dev/md127 -r /dev/sdb7
mdadm: hot remove failed for /dev/sdb7: Device or resource busy
[root@m01 ~]# mdadm /dev/md127 -f /dev/sdb7
mdadm: set /dev/sdb7 faulty in /dev/md127
[root@m01 ~]# mdadm /dev/md127 -r /dev/sdb7
mdadm: hot removed /dev/sdb7 from /dev/md127
##此时查看md127的信息,发现状态为degraded状态(降级模式)
[root@m01 ~]# mdadm -D /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Thu Aug 23 14:00:33 2018
Raid Level : raid5
Array Size : 2117632 (2.02 GiB 2.17 GB)
Used Dev Size : 1058816 (1034.00 MiB 1084.23 MB)
Raid Devices : 3
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Thu Aug 23 15:02:48 2018
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : m01:0 (local to host m01)
UUID : f8cd3a92:da0ef586:c11a4f1d:8887e949
Events : 43
Number Major Minor RaidDevice State
0 8 21 0 active sync /dev/sdb5
3 8 24 1 active sync /dev/sdb8
4 0 0 4 removed
##添加sdb7到raid中
[root@m01 ~]# mdadm /dev/md127 -a /dev/sdb7
mdadm: added /dev/sdb7
##显示正在重建
[root@m01 ~]# mdadm -D /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Thu Aug 23 14:00:33 2018
Raid Level : raid5
Array Size : 2117632 (2.02 GiB 2.17 GB)
Used Dev Size : 1058816 (1034.00 MiB 1084.23 MB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Thu Aug 23 15:08:27 2018
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 56% complete
Name : m01:0 (local to host m01)
UUID : f8cd3a92:da0ef586:c11a4f1d:8887e949
Events : 60
Number Major Minor RaidDevice State
0 8 21 0 active sync /dev/sdb5
3 8 24 1 active sync /dev/sdb8
4 8 23 2 spare rebuilding /dev/sdb7
6.3 移除raid方法
1、umount卸载RAID设备
[root@yufei ~]# umount /dev/md5
2、停止RAID设备
[root@yufei ~]# mdadm -S /dev/md5
mdadm: stopped /dev/md5
3、移除RAID里面的磁盘
[root@yufei ~]# mdadm --misc --zero-superblock /dev/sde
[root@yufei ~]# mdadm --misc --zero-superblock /dev/sdc
[root@yufei ~]# mdadm --misc --zero-superblock /dev/sdd
[root@yufei ~]# mdadm --misc --zero-superblock /dev/sdf
4、删除相关配置文件里面的RAID信息
[root@yufei ~]# vim /etc/mdadm.conf
把我们增加的这一行删除
ARRAY /dev/md5 metadata=1.2 spares=1 name=yufei:5 UUID=69443d97:7e32415d:7f3843c5:4d5015cf
[root@yufei ~]# vim /etc/fstab
把我们增加的这一行删除
/dev/md5 /mnt ext4 defaults 0 0