1.匹配一行文字中某个单词后面的内容,但仅限于本行,换行后的内容不匹配.假设这个词是XXX
XXX[^ ]+
2.匹配第一次出现的字符
^.*?(chars) 匹配从头到第一次出现chars的内容
注意:使用notepad++ 替换时会匹配后面的情况,建议先替换为指定字符串,比如“==”,再进行替换
3.匹配空格后的所有内容
[[:blank:]].*
不能使用s.*,这样会匹配新一行
4.oracle中sql语句使用正则表达式
1)使用regexp_like函数
语法:
1.source_char,输入的字符串,可以是列名或者字符串常量、变量。
2.pattern,正则表达式。
3.match_parameter,匹配选项。
取值范围: i:大小写不敏感; c:大小写敏感;n:点号 . 不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。
例子:
1)查询所有包含小写的所有数据
select name from Student where regexp_like(name,'[a-z]');
2)查询只包含小写的所有数据
select name from Student where regexp_like(name,'^[a-z]+$');
2)regexp_substr 函数
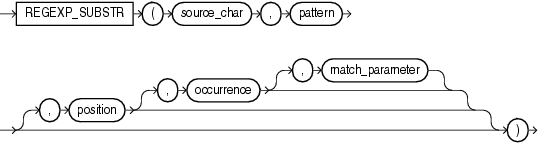
/*查找一段话,第一句(第一个句号之前)的内容*/ select regexp_substr(t.chinesetablename, '[^。]+。') str from jieguo1 t where length(t.chinesetablename) >= 15 and t.chinesetablename like '%主要包括%';
正则解释:[^。] 非。
5.linux中匹配中文
[root@localhost opt]# du -a
4 ./zw/你好.txt
4 ./zw
4 .
[root@localhost opt]# du -a|grep "[一-龥]"
4 ./zw/你好.txt
[root@localhost opt]#
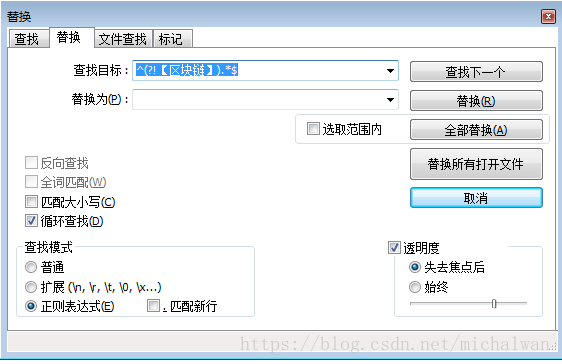
6.Notepad++用正则表达式删除非特定字符串开始的行

7.替换掉非数字的字符
var s ="价格4500元,等级:2";
var num = s.replace(/[^0-9]/ig,"");
alert(num);//45002
https://www.cnblogs.com/xiaochongchong/p/5304909.html
8.包含、以前、以后
1.正则查找不包含某些字符串 ^((?!不想包含的字符串).)*$ ^((?!().)*$ 查找不包含( 2.查找字符串以前的 ^.*字符串 ^.*( 3.查找字符串以后的 字符串.*$ ).*$
d+$ 末尾的数字
注意:粘贴的时候小心空格
http://www.runoob.com/regexp/regexp-metachar.html
9.包含A同时包含B
例子:.*权限.*方案.*
参考资料:
2)https://www.cnblogs.com/lizhaoxian/p/11260260.html