java内存模型是一个抽象的概念,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
Java内存模型解决的问题
1.CPU和缓存一致性问题
程序执行的每条指令都是在CPU上执行的,指令的执行就需要读写内存数据,随着CPU技术的发展,CPU的执行速度越来越快。而由于内存的技术并没有太大的变化,所以从内存中读取和写入数据的过程和CPU的执行速度比起来差距就会越来越大,这就导致CPU每次操作内存都要耗费很多等待时间。为了解决这个问题,人们在CPU与主存之间加了高速缓存,这样CPU操作数据直接操作缓存中的数据,操作完成之后再刷新到主存,随着CPU能力的不断提升,一级缓存发展为多级缓存。按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存(L1),二级缓存(L3),部分高端CPU还具有三级缓存(L3),每一级缓存中所储存的全部数据都是下一级缓存的一部分。当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。
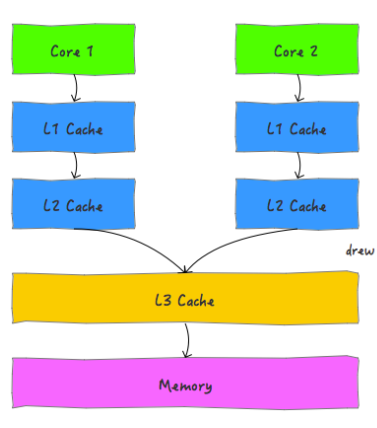
随着计算机能力不断提升,开始支持多线程。那么问题就来了。我们分别来分析下单线程、多线程在单核CPU、多核CPU中的影响。
- 单线程:cpu核心的缓存只被一个线程访问。缓存独占,不会出现访问冲突等问题。
- 单核CPU,多线程:进程中的多个线程会同时访问进程中的共享数据,CPU将某块内存加载到缓存后,不同线程在访问相同的物理地址的时候,都会映射到相同的缓存位置,这样即使发生线程的切换,缓存仍然不会失效。但由于任何时刻只能有一个线程在执行,因此不会出现缓存访问冲突。
- 多核CPU,多线程:每个核都至少有一个L1 缓存。多个线程访问进程中的某个共享内存,且这多个线程分别在不同的核心上执行,则每个核心都会在各自的caehe中保留一份共享内存的缓冲。由于多核是可以并行的,可能会出现多个线程同时写各自的缓存的情况,而各自的cache之间的数据就有可能不同。
因此,多核CPU,多线程情况下就可能出现缓存不一致的情况。
2.处理器优化和指令重排问题
那就是为了使处理器内部的运算单元能够尽量的被充分利用,处理器可能会对输入代码进行乱序执行处理。这就是处理器优化。除了现在很多流行的处理器会对代码进行优化乱序处理,很多编程语言的编译器也会有类似的优化,比如Java虚拟机的即时编译器(JIT)也会做指令重排。可想而知,如果任由处理器优化和编译器对指令重排的话,就可能导致各种各样的问题。
Java内存模型就是为了解决上面两种问题。Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。而JMM就作用于工作内存和主存之间数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。
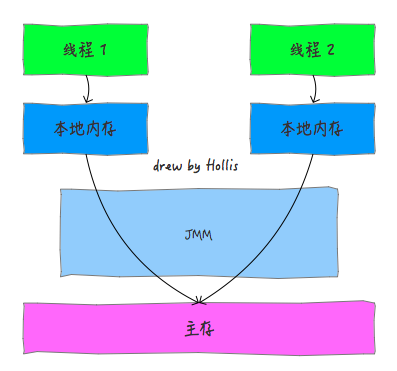
Java内存模型的实现
在Java中提供了一系列和并发处理相关的关键字,比如volatile、synchronized、final、concurren包等。其实这些就是Java内存模型封装了底层的实现后提供给程序员使用的一些关键字。在开发多线程的代码的时候,我们可以直接使用synchronized等关键字来控制并发,从来就不需要关心底层的编译器优化、缓存一致性等问题。所以,Java内存模型,除了定义了一套规范,还提供了一系列原语,封装了底层实现后,供开发者直接使用。
synchronized可以保证程序的可见性,原子性,有序性。volatile可以保证可见性和有序性。而CPU缓存一致问题就是可见性问题,编译器优化和指令重排就是有序性问题。