Storm基本概念
Storm是一个分布式的、可靠地、容错的数据流处理系统。Storm分布式计算结构称为Topology(拓扑)结构,顾名思义,与拓扑图十分类似。该拓扑图主要由数据流Stream、数据流的生成者Spout和数据流的运算者Bolt组成。如下图所示:

在Storm系统中,数据主要是通过tuple数据结构进行传输的。tuple就是一个列表,列表中可以存放任何类型的数据(该数据类型必须要实现序列化)。
Spout的作用就是从数据源中获取需要的数据,起到一个数据采集器的作用。然后spout将获取到的数据封装成为tuple类型,最后传输给计算者bolt。Storm为实现Spout的功能,为用户提供了非常简单的API结构。Spout常用的数据源一般包括以下几个:
- web或者移动程序的点击流
- 社交网路的消息
- 传感器的输出
- 应用程序的日志事件
Spout通常只负责采集数据,并不做数据的业务逻辑处理,所以一般可以被复用。
Bolt是Storm中的计算核心骨干成员,负责接受数据流并实现业务逻辑。bolt将一个或者多个数据流作为输入数据,经过逻辑处理运算后再选择性的输出给一个或者多个数据流。bolt只可以订阅一个或者多个由Spout或者上游Bolt输出的数据流。通过Spout和Bolt以及Bolt和Bolt之间的订阅关系,可以产生复杂topology结构图,也就可以实现复杂的业务逻辑啦。Storm也为Bolt提供了简单明了的API接口,简化用户实现逻辑功能的过程。
下面主要通过一个单词统计的实例初步体验一下Storm的功能以及简单的API使用。这个实例在网上有很多版本,也很容易找的到,是Storm单机版入门的经典实例。抛开Storm架构,在统计一个文章中每个单词的出现频数,最简单粗暴的方法就是计数,细分过程就是首先读取一个语句,然后将该语句中的每个单词与统计表进行比对,进行数据统计,最后将统计表进行输出。那么,把这个过程与Storm结合起来就如下所示啦:

下面首先看一下完工后的项目框架:
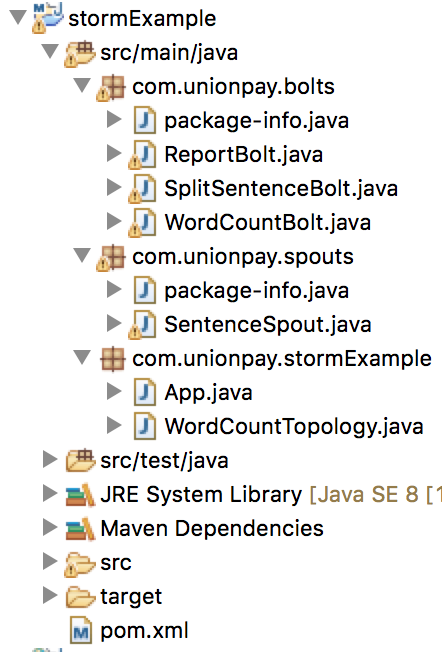
本地运行WordCountTopology.java文件,Eclipse终端打印计数结果如下(随着环境的不同,计数结果可能不同):

开发环境:
- 集成开发环境:Eclipse Neon.2 Release (4.6.2)
- Java版本:java version "1.8.0 121"
- Storm版本:storm-core-0.10.2.jar
在思路清晰的基础上,我们就要开始干活了。首先搭建一个基础的maven Java项目开发框架,大家可以在网上搜索相关教程,也可以参考本人随笔 maven 基础框架搭建。本项目起名为stormExample。
当项目框架搭建完成后,就需要通过maven配置文件pom引入Storm依赖包:
pom.xml
1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 5 <groupId>com.unionpay</groupId> 6 <artifactId>stormExample</artifactId> 7 <version>0.0.1-SNAPSHOT</version> 8 <packaging>jar</packaging> 9 10 <name>stormExample</name> 11 <url>http://maven.apache.org</url> 12 13 <properties> 14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 15 </properties> 16 17 <dependencies> 18 <dependency> 19 <groupId>junit</groupId> 20 <artifactId>junit</artifactId> 21 <version>3.8.1</version> 22 <scope>test</scope> 23 </dependency> 24 <dependency> 25 <groupId>org.apache.storm</groupId> 26 <artifactId>storm-core</artifactId> 27 <version>0.10.2</version> 28 </dependency> 29 </dependencies> 30 </project>
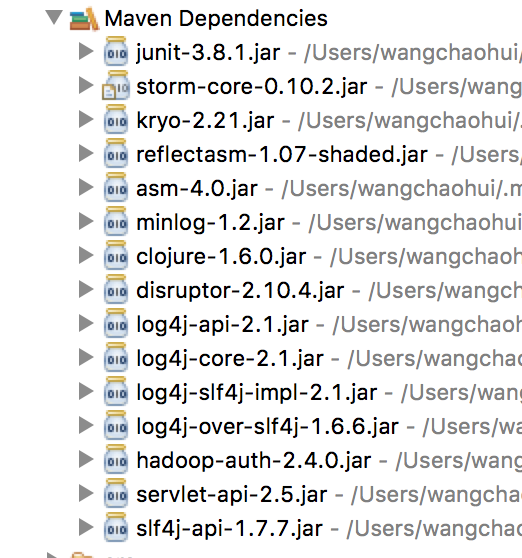
对pom.xml文件编写完后进行保存并update Project,就可以在项目结构中看见引入了许多相关的jar依赖包:
下面按照上面分析的伪流程图来一步步编写代码。首先编写Spout文件,这是因为Spout在Storm中充当着数据采集的工作。在src/main/java目录下建立package,然后在该package中新建java文件: SentenceSpout.java
SentenceSpout.java
1 package com.unionpay.spouts; 2 3 import java.util.Map; 4 import java.util.UUID; 5 import java.util.concurrent.ConcurrentHashMap; 6 7 import backtype.storm.spout.SpoutOutputCollector; 8 import backtype.storm.task.TopologyContext; 9 import backtype.storm.topology.OutputFieldsDeclarer; 10 import backtype.storm.topology.base.BaseRichSpout; 11 import backtype.storm.tuple.Fields; 12 import backtype.storm.tuple.Values; 13 import backtype.storm.utils.Utils; 14 15 public class SentenceSpout extends BaseRichSpout{ 16 17 // 一个可靠的单词计数需要对tuple的传输进行确认 18 private ConcurrentHashMap<UUID, Values> pending; 19 private SpoutOutputCollector collector; 20 21 private String[] sentences = { 22 "my dog has fleas", 23 "i like could beverage", 24 "the dog ate my homework", 25 "don't have a cow man", 26 "i don't think i like fleas" 27 }; 28 29 private int index = 0; 30 31 public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { 32 // TODO Auto-generated method stub 33 this.collector = collector; 34 this.pending = new ConcurrentHashMap<UUID, Values>(); 35 36 } 37 38 public void nextTuple() { 39 // TODO Auto-generated method stub 40 41 Values values = new Values(sentences[index]); 42 UUID msgid = UUID.randomUUID(); 43 this.pending.put(msgid, values); 44 this.collector.emit(values,msgid); 45 index++; 46 if(index>=sentences.length){ 47 index = 0; 48 } 49 Utils.sleep(1); 50 } 51 52 public void declareOutputFields(OutputFieldsDeclarer declarer) { 53 // TODO Auto-generated method stub 54 declarer.declare(new Fields("sentence")); 55 } 56 57 public void ack(Object msgid){ 58 this.pending.remove(msgid); 59 } 60 61 public void fail(Object msgid){ 62 this.collector.emit(this.pending.get(msgid)); 63 } 64 65 }
该段代码包括了Storm Spout API的五个方法:open,nextTuple,declearOutputFields,ack和fail。open方法接受三个参数(Map、TopologyContext和SpoutOutCollector),Map包含了Storm的配置信息,TopologyContext包含了Topology结构中的组件信息,SpoutOutCollector定义了数据流tuple是如何发送给bolt的。nextTuple方法是Spout的核心所在,收集数据的操作就是在这里面完成的。Storm也是通过这个方法将数据通过collector发送给bolt的。declareOutputFields声明了该Spout/Bolt中emit输出的字段个数,供下游使用,如果declareOutputFields中声明的输出字段的个数与emit中输出的字段个数数目不同,则会报错。为了保证数据能够被正确的处理掉,对于每一个产生的tuple,Storm都会进行跟踪,这里面涉及到了ack和fail的处理,如果一个tuple处理成功,则会调用Spout的ack方法,如果处理失败,则会调用fail方法。
下面接着编写将语句分割成单词的bolt。同样在src/main/java目录下新建bolt package,然后在该package中新建SplitSentenceBolt.java文件。
SplitSentenceBolt.java
1 package com.unionpay.bolts; 2 3 import java.util.Map; 4 5 import backtype.storm.task.OutputCollector; 6 import backtype.storm.task.TopologyContext; 7 import backtype.storm.topology.OutputFieldsDeclarer; 8 import backtype.storm.topology.base.BaseRichBolt; 9 import backtype.storm.tuple.Fields; 10 import backtype.storm.tuple.Tuple; 11 import backtype.storm.tuple.Values; 12 13 public class SplitSentenceBolt extends BaseRichBolt{ 14 15 private OutputCollector collector; 16 17 public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { 18 // TODO Auto-generated method stub 19 this.collector = collector; 20 21 } 22 23 public void execute(Tuple input) { 24 // TODO Auto-generated method stub 25 String sentence = input.getStringByField("sentence"); 26 if(sentence!=null && sentence.trim().length()>0){ 27 String[] words = sentence.split(" "); 28 for(String word : words){ 29 this.collector.emit(input,new Values(word)); 30 } 31 this.collector.ack(input); 32 } 33 34 } 35 36 public void declareOutputFields(OutputFieldsDeclarer declarer) { 37 // TODO Auto-generated method stub 38 declarer.declare(new Fields("word")); 39 40 } 41 42 }
Bolt中的prepare方法如同Spout中的open一样,起到了一个初始工作准备的作用,在该方法内可以完成执行过程中需要的资源,比如数据库连接等等。execute方法是Bolt的核心,该bolt的逻辑功能就在这个方法中实现。该方法有一个参数Tuple,这个Tuple就是从上文Spout中订阅的数据流tuple,现在是不是还没有看出来是如何订阅的,不要着急,下文中在main执行函数中可以让你看见。该方法接受上流的tuple进行处理,处理完后又将处理结果封装成为一个tuple发送给下文。在declareOutputFields方法中,声明了一个输出流,也就是说,该类通过execute方法输出的所有tuple中都包含着一个字段“word”,该字段在后续会影响着数据流的分配。
下面编写单词计数Bolt。新建WordCountBolt.java方法:
WordCountBolt.java
1 package com.unionpay.bolts; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 import backtype.storm.task.OutputCollector; 7 import backtype.storm.task.TopologyContext; 8 import backtype.storm.topology.OutputFieldsDeclarer; 9 import backtype.storm.topology.base.BaseRichBolt; 10 import backtype.storm.tuple.Fields; 11 import backtype.storm.tuple.Tuple; 12 import backtype.storm.tuple.Values; 13 14 public class WordCountBolt extends BaseRichBolt{ 15 16 private OutputCollector collector; 17 private HashMap<String,Long> counts = null; 18 19 public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { 20 // TODO Auto-generated method stub 21 this.collector = collector; 22 this.counts = new HashMap<String,Long>(); 23 24 } 25 26 public void execute(Tuple input) { 27 // TODO Auto-generated method stub 28 String word = input.getStringByField("word"); 29 Long count = this.counts.get(word); 30 if(count==null){ 31 count = 0L; 32 } 33 count++; 34 this.counts.put(word, count); 35 this.collector.emit(new Values(word,count)); 36 } 37 38 public void declareOutputFields(OutputFieldsDeclarer declarer) { 39 // TODO Auto-generated method stub 40 declarer.declare(new Fields("word","count")); 41 } 42 43 }
WordCountBolt类在prepare方法中初始化了一个HashMap<String,Long> counts用来存储word以及对应的计数。
下面完成最后一个输出Bolt:ReportBolt.java
ReportBolt.java
1 package com.unionpay.bolts; 2 3 import java.util.ArrayList; 4 import java.util.Collections; 5 import java.util.HashMap; 6 import java.util.List; 7 import java.util.Map; 8 import java.util.Set; 9 10 11 import backtype.storm.task.OutputCollector; 12 import backtype.storm.task.TopologyContext; 13 import backtype.storm.topology.OutputFieldsDeclarer; 14 import backtype.storm.topology.base.BaseRichBolt; 15 import backtype.storm.tuple.Tuple; 16 17 public class ReportBolt extends BaseRichBolt{ 18 19 private HashMap<String,Long> counts = null; 20 21 public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { 22 // TODO Auto-generated method stub 23 this.counts = new HashMap<String,Long>(); 24 25 } 26 27 public void execute(Tuple input) { 28 // TODO Auto-generated method stub 29 String word = input.getStringByField("word"); 30 Long count = input.getLongByField("count"); 31 this.counts.put(word, count); 32 33 } 34 35 public void declareOutputFields(OutputFieldsDeclarer declarer) { 36 // TODO Auto-generated method stub 37 38 } 39 40 public void cleanup(){ 41 System.out.println("......FINAL COUNT......"); 42 List<String> keys= new ArrayList<String>(); 43 keys.addAll(counts.keySet()); 44 Collections.sort(keys); 45 for(String key : keys){ 46 System.out.println(key + " : " + counts.get(key)); 47 } 48 System.out.println("----------"); 49 50 } 51 52 }
在该类中比前两个Bolt多了一个cleanup方法,从代码中也可已看出,该方法的主要作用就是输出最终的统计信息。其实,cleanup方法一般在终结的bolt中调用,一般用于释放bolt资源,也就是说,一般在Storm需要终止一个bolt时调用该方法。
从目前的状态来看,伪流程图中的四个阶段相关代码我们都编写了,那是不是就完成了,可以运行测试了呢?答案是否定的,因为我们虽然将四个阶段都分别完成啦,可是却没有一条主线将这四个阶段串联起来。再说,还没编写main方法呢。那么要怎么将这四个阶段串联起来呢?答案就是TopologyBuilder。也就是说,我们需要在main方法中通过TopologyBuilder建立一个topology结构实例,然后将上述的四个过程填充到这个topology结构实例。下面编写主类WordCountTopology.java
WordCountTopology.java
1 package com.unionpay.stormExample; 2 3 import com.unionpay.bolts.ReportBolt; 4 import com.unionpay.bolts.SplitSentenceBolt; 5 import com.unionpay.bolts.WordCountBolt; 6 import com.unionpay.spouts.SentenceSpout; 7 8 import backtype.storm.Config; 9 import backtype.storm.LocalCluster; 10 import backtype.storm.topology.TopologyBuilder; 11 import backtype.storm.tuple.Fields; 12 import backtype.storm.utils.Utils; 13 14 public class WordCountTopology { 15 16 private static final String SENTENCE_SPOUT_ID = "sentence_spout"; 17 private static final String SPLIT_BOLT_ID = "split_bolt"; 18 private static final String COUNT_BOLT_ID = "count_bolt"; 19 private static final String REPORT_BOLT_ID = "report_bolt"; 20 private static final String TOPOLOGY_NAME = "word_count_topology"; 21 22 public static void main(String[] args) { 23 // TODO Auto-generated method stub 24 SentenceSpout spout = new SentenceSpout(); 25 SplitSentenceBolt splitBolt = new SplitSentenceBolt(); 26 WordCountBolt countBolt = new WordCountBolt(); 27 ReportBolt reportBolt = new ReportBolt(); 28 29 TopologyBuilder builder = new TopologyBuilder(); 30 builder.setSpout(SENTENCE_SPOUT_ID, spout); 31 32 // 设置SentenceSpout 的 executor 为 2; 33 // builder.setSpout(SENTENCE_SPOUT_ID, spout, 2); 34 35 builder.setBolt(SPLIT_BOLT_ID, splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID); 36 37 // 设置SplitBolt的executor 为2,task数为4,这样,每个executor线程指派2个task; 38 // builder.setBolt(SPLIT_BOLT_ID, splitBolt,2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID); 39 40 builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")); 41 42 // builder.setBolt(COUNT_BOLT_ID, countBolt,4).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")); 43 44 builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID); 45 46 Config config = new Config(); 47 // 通过config配置类为topology增加Worker 48 // config.setNumWorkers(2); 49 50 LocalCluster cluster = new LocalCluster(); 51 52 cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology()); 53 54 Utils.sleep(10000); 55 56 cluster.killTopology(TOPOLOGY_NAME); 57 58 cluster.shutdown(); 59 60 } 61 62 }
从代码中可以看出,通过TopologyBuilder的setSpout和setBolt方法将前文中的Spout实例和Bolt实例填充到topology结构中。Storm的LocalCluster类在本地开发环境模拟一个Storm集群。由于Storm是不间断运行的,我们将进程运行10s中后强制停止,统计单词计数。最后本地运行该类,就可以看到终端打印出统计数据。
源码下载:stormExample.zip