1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
· 逻辑回归降拟合方法:
(1)增加样本量;
(2)使用正则化:L1、L2正则化;
(3)特征选择,剔除一些不重要的特征,从而降低模型复杂度;
(4)进行离散化处理,这也是最主要的。
· 防止过拟合:
函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。这里我们是对X数据本身求导,导数里面包含W系数,所以当X的导数很大,即拟合曲线很弯曲时,W就会很大。所以让W变小就可以防止过拟合,L2正则化正是通过让W变小,来防止过拟合的。
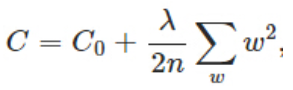 (对w求导)→
(对w求导)→ 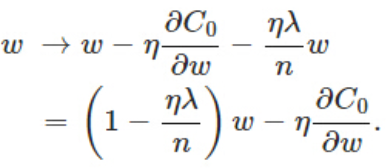
η、λ、n都是正的,所以 1−ηλ/n小于1,w就减小了。
2.用logiftic回归来进行实践操作,数据不限。
来预测泰坦尼克号上幸存、死亡人数与层数、性别、年龄的关系,数据如下(一部分):

代码如下:
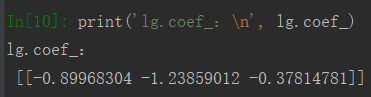
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_error from sklearn.metrics import classification_report import numpy as np import pandas as pd # 读取数据 data = pd.read_csv('./venv/titanic_data.csv') # 数据预处理 data.drop('PassengerId', axis=1, inplace=True) # 删除PassengerId这一列 # 归类,male为1,female为0 data.loc[data['Sex'] == 'male', 'Sex'] = 1 data.loc[data['Sex'] == 'female', 'Sex'] = 0 data.fillna(data['Age'].mean(), inplace=True) # 年龄如果为空就用平均值代替 data # 数据分割 x_data = data.iloc[:, 1:] y_data = data.iloc[:, 0] x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3) # 标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 构建和训练模型 lg = LogisticRegression() lg.fit(x_train, y_train) print('lg.coef_: ', lg.coef_) lg_predict = lg.predict(x_test) print('准确率: ', lg.score(x_test, y_test)) print('召回率: ', classification_report(y_test, lg_predict, labels=[0, 1], target_names=['死亡', '存活']))
预测结果: