一、简介和操作
Redis 读写分离的实现非常简单,就是启动两个实例,一个负责读(称之为:读实例),一个负责写(称之为:写实例),读实例复制写实例的数据。
这里我以 Windows 环境下举例,Linux 环境的网上案例更多,它们的思想是一样的。
首先,准备两份一模一样的 Redis 程序,这是 Windows 环境下的目录,都是免安装的,拿来即用。
第一个写实例,我们直接用命令启动,这里就不演示了,默认的IP和端口号是:127.0.0.1 和 6379。
第二个读实例,我们就不能用 6379 了,我们换一个用 6380,所以,我们需要修改配置文件,同时,我们需要读实例去监听写实例,所以也要修改这部分内容,改起来特别简单。
修改默认端口号
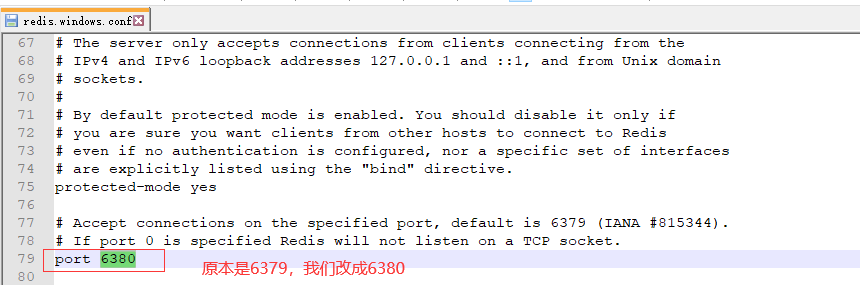
指定需要复制的主服务器

修改完以后,我们启动读实例,在写实例上我们 set 一个值,从读实例上我们就可以 get 到这个数据,这样就实现了读写分离。

二、Redis 读写分离是怎么做数据同步的?
进行复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作“数据库状态一致”。
Redis 有两种持久化数据的方法。一种是:全量持久化(RDB);另一种是:增量持久化(AOF)。
简单的形容:全量持久化就是把数据完完全全的复制一遍;增量持久化就是把本次和上次数据进行对比,有差别的地方复制一遍,旧数据+更改数据=现在的数据
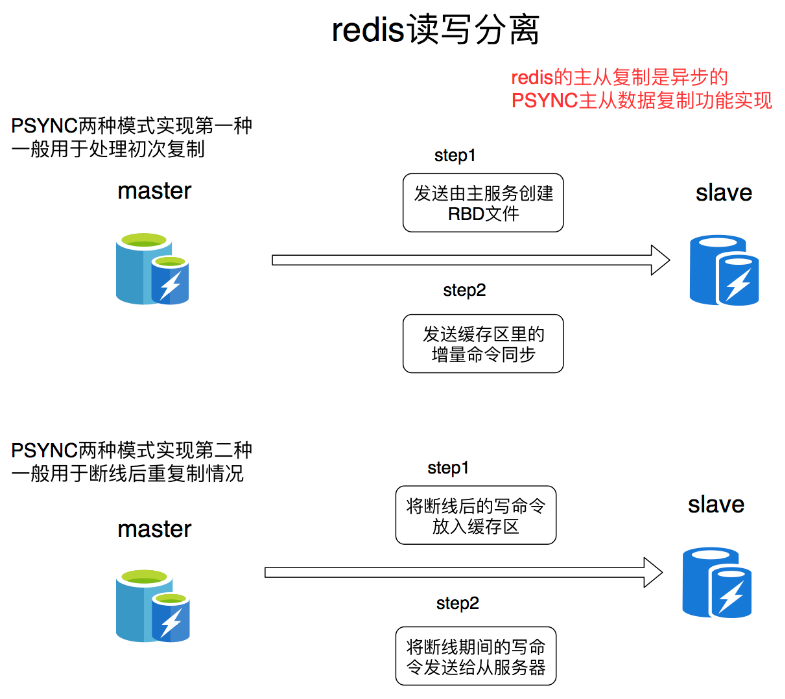
Redis 2.8 版本之前使用旧版复制功能 SYNC
SYNC 是一个非常耗费资源的操作。主服务器需要执行 BGSAVE 命令来生成 RDB 文件,这个生成操作会耗主服务器大量的CPU、内存和盘读写资源。主服务器将 RDB 文件发送绐从服务器,这个发送操作会耗费主从服务器大量的网络带宽和流量,并对主服务器晌应命令请求的时间产生影响:接收到 RDB 文件的从服务器在载入文件的过裎是阻塞的,无法处理命令请求
Redis 2.8 之后使用 PSYNC
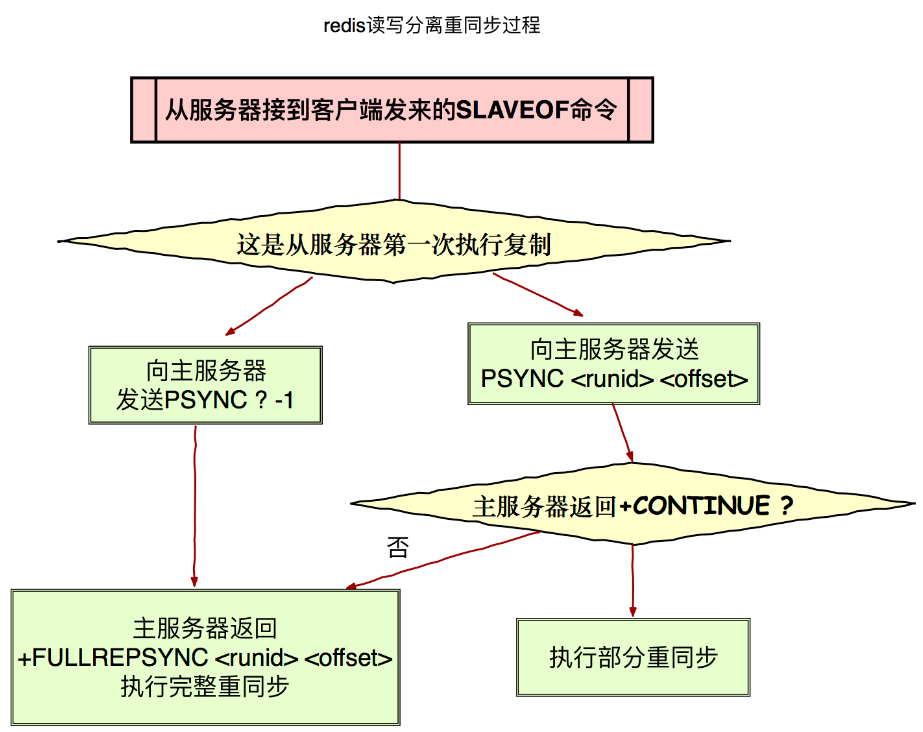
PSYNC 命令有完整重同步(full resynchronization 也就是 SYNC)和部分重同步(partial resynchronizationl)两种模式。部分重同步功能由以下三个部分构成:
- 主服务的复制偏移量(replication offset)和从服务器的复制偏移量。
- 主服务器的复制积压缓冲区(replication backlog),默认大小为1M。
- 服务器的运行ID(run ID),用于存储服务器标识,如从服务器断线重新连接,取到主服务器的运行 ID 与重接后的主服务器运行 ID 进行对比,从而判断是执行部分重同步还是执行完整重同步。
三、高可用的概念?
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
通过三大要点解释高可用:
- 单点是系统高可用的大敌,应该尽量在系统设计的过程中避免单点。
- 保证系统高可用,架构设计的核心准则是:冗余。
- 每次出现故障需要人工介入恢复势必会增加系统的不可服务时间,实现自动故障转移。
- 重启服务,看服务是否每次都获取锁失败。
四、分布式高可用经典架构环节分析
- 【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余来实现的。以 nginx 为例:有两台 nginx,一台对线上提供服务,另一台冗余以保证高可用, 常见的实践是 keepalived 存活探测。
- 【反向代理层】到【web 应用】的高可用,是通过站点层的冗余来实现的。假设反向代理层是 nginx,nginx.conf 里能够配置多个 web 后端,并且 nginx 能够探测到多个后端的存活性。自动故障转移:当 web-server 挂了的时候,nginx 能够探测到,会自动的进行故障转移,将流量自动迁移到其他的 web-server,整个过程由 nginx 自动完成,对调用方是透明的。
- 【服务层】到【缓存层】的高可用,是通过缓存数据的冗余来实现的。 redis 天然支持主从同步,redis 官方也有 sentinel 哨兵机制,来做 redis 的存活性检测。
- 【服务层】到【数据库层】的高可用,数据库层用“主从同步,读写分离”架构,所以数据库层的高可用,又分为“读库高可用”与“写库高可用”两类。读库采用冗余的方式实现高可用,写库采用 keepalived 存活探测,binlog 进行同步。