最近对Python爬虫比较迷恋,看了些爬虫相关的教程
于是乎跟着一起爬取了58上面的一些商品信息,并存入到xlsx文件中,并通过xlsxwirter的方法给表格设置了一些格式。好了,直接贴代码吧~
#coding:utf-8 from bs4 import BeautifulSoup import requests import sys import xlsxwriter import re reload(sys) sys.setdefaultencoding('utf8') def get_links_from(urls,who_sell=0,page=1): list_view = 'http://bj.58.com/haidian/pbdn/{}/pn{}/'.format(str(who_sell), str(page)) web_data = requests.get(list_view) soup = BeautifulSoup(web_data.text, "lxml") for url in soup.select('td.t a.t'): url = url.get('href').split('?')[0] if url.find('zhuanzhuan.58.com') != -1: urls.append(url) is_next = soup.select('.next') if is_next: #如果存在下一页,继续获取url并保存到urls get_links_from(urls,who_sell,page+1) return urls def get_views_from(url): id = url.split('/')[-1].strip('z.shtml') api = 'http://jst1.58.com/counter?infoid={}'.format(id) js = requests.get(api) view = js.text.split('=')[-1] return view def get_item_info(who_sell): datas = [] urls = [] urls = get_links_from(urls,who_sell,1) workbook = xlsxwriter.Workbook(u'F:/Python27/magua/download/二手平板.xlsx') worksheet = workbook.add_worksheet('haidian') format = workbook.add_format({'bold':True, 'font_color': 'B452CD', 'font_size': 16, 'align':'center', 'bg_color':'FFA54F'}) worksheet.set_row(0, 20) #设置第1行的单元格高度 worksheet.set_column('A:A', 100) #设置第A列的单元格长度 worksheet.set_column('C:C', 15) #设置第C列的单元格长度 worksheet.set_column('D:D', 15) #设置第D列的单元格长度 worksheet.set_column('E:E', 15) #设置第E列的单元格长度 worksheet.write(0, 0, '标题', format) worksheet.write(0, 1, '价格', format) worksheet.write(0, 2, '区域', format) worksheet.write(0, 3, '个人/商家', format) worksheet.write(0, 4, '浏览量', format) # workbook.close() # return row_num = 1 for url in urls: web_data = requests.get(url) soup = BeautifulSoup(web_data.text, "lxml") data = { 'title':soup.title.text.strip(), #strip 去掉字符串中的换行、制表符 'price':soup.select('.price_now i')[0].text, # #代表id 'area':soup.select('.palce_li i')[0].text, 'cate':u'个人' if who_sell ==0 else u'商家', 'view':soup.select('.look_time')[0].text.split('次')[0], # 'views':get_views_from(url), } # datas.append(data) if row_num%2: format_ = workbook.add_format({'bg_color': 'FFEC8B', 'font_size': 12}) else: format_ = workbook.add_format({'bg_color': 'FFDAB9', 'font_size': 12}) #write the data into .xlsx file worksheet.write(row_num, 0, data['title'], format_) worksheet.write(row_num, 1, data['price'], format_) worksheet.write(row_num, 2, data['area'], format_) worksheet.write(row_num, 3, data['cate'], format_) worksheet.write(row_num, 4, data['view'], format_) row_num = row_num + 1 workbook.close() ''' for item in datas: print repr(item).decode("unicode-escape") # print item print "total: %d" % len(datas) ''' get_item_info(0) #参数 0为个人,1为商家
在这过程中有点不明白的地方就是xlsxwriter.Workbook 方法在创建xlsx文件的时候,必须要绝对路径才能成功,看官方文档也没找到问题的原因
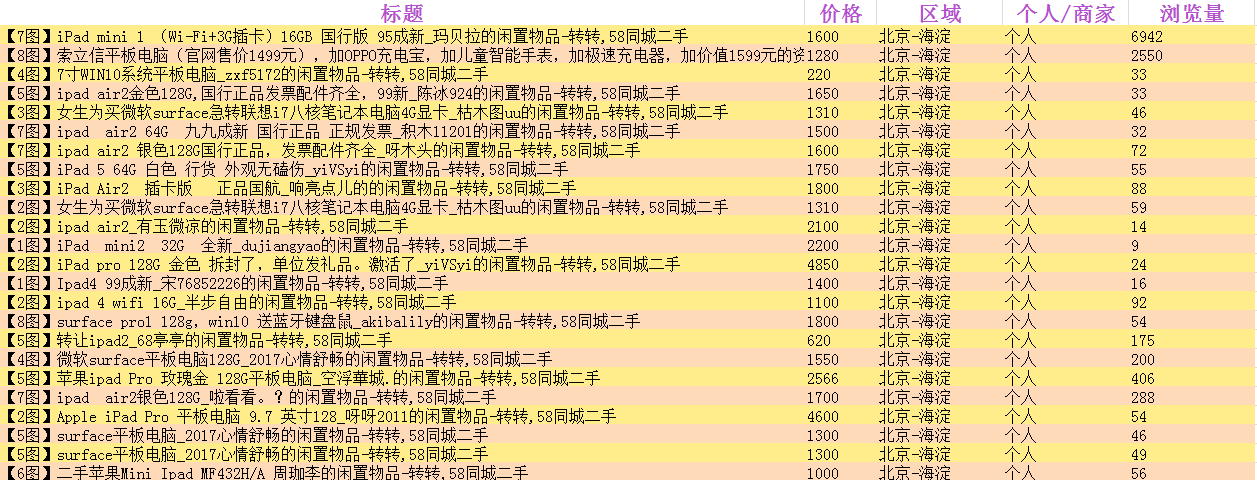
最后抓取信息所生成的表格文件截图