一、背景知识:
软件开发的基本过程:
需求定义→软件设计→软件实现→软件测试→软件维护
软件的定义:
软件=程序+数据+文档
程序:可以按照设计好的功能和性能要求执行的指令序列
数据:程序能正确处理信息的数据结构
文档:与程序的开发、维护、使用有关的图文资料
软件的特点:
- 包含个人因素的大规模知识型工作
- 有工具辅助的软件开发也尚未实现自动化(即无法像硬件加工一样,机械组装已有部件,软件开发还未达到组装已有模块的程度)
- 对开发和运行的计算机软硬件环境具有依赖性
- 需求往往在变更,开发进度难估算
- 软件测试困难,覆盖所有路径的测试难实现。软件测试只能证明软件中有缺陷,不能证明软件中没有缺陷。
- 软件不会损耗,(参考硬件的磨损和老化),软件维护不再具有经济性时,软件即被淘汰
软件危机:
- 1965年——1985年,20世纪60——80年代
- 于1968年提出
- 催生了软件工程这一学科
- 没有化解软件危机的灵丹妙药,已知的技术和方法都是进一步改进
SWEBOK(软件工程知识体系指南)
PDCA环(戴明环):

二、软件过程:
以质量为中心,以软件工程,方法,工具为三要素。其中软件过程是基础,是联系各层的桥梁,工具为过程和方法提供支持。
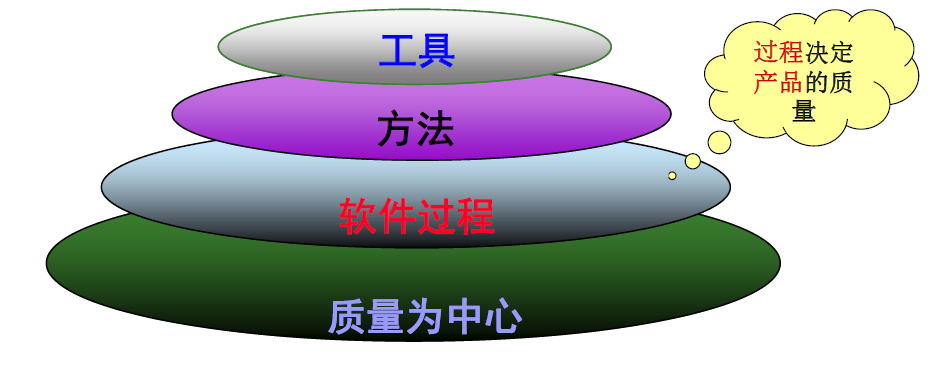
软件过程的定义:软件过程定义了软件开发中的一系列活动,所以过程都具有下列活动:
- 沟通
- 建模
- 计划
- 构造
- 部署
- 项目管理(贯穿于以上所有活动)
软件生命周期:
- 定义时期:问题定义,可行性研究,需求分析
- 开发时期:概要设计,详细设计,编码,测试
- 运行/维护时期
软件过程模型:
- 模型不是过程的直接描述,而是过程的抽象。可以用于解释软件产品不同的开发方法。
- 从项目需求定义到运行维护为止,跨越整个生命周期的过程,活动和任务的结构框架。
- 也被称为:软件生命周期模型,软件开发模型,软件工程范型
瀑布模型:
- 20世纪80年代之前被广泛使用,因此被称为经典的生命周期模型。
- 线性模型:软件开发过程与生命周期是一致的,规定了各项工程活动的自上而下,逐级下落的次序。
- 以文档为驱动
传统的瀑布模型:
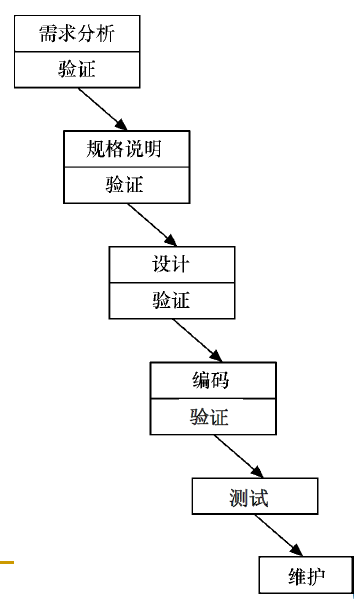
- 各个阶段都按顺序执行
- 每个阶段完成规定的文档
- 每个阶段结束有一个验证环节,只有通过验证才能进入下一个阶段
- 阶段间具有顺序性和依赖性:前一阶段的输出文档就是后一阶段的输入文档
- 推迟实现的观点(重要思想):区分开逻辑设计和物理设计,推迟程序的物理实现
- 质量保证的观点:每个阶段必须完成规定的文档,并在阶段结束前进行审核
实际的(带反馈的)瀑布模型:

若后面的阶段发现前面阶段的错误,则返回前面阶段进行修改。
瀑布模型的优缺点:
- 每个阶段交出的作品都是经过验证的,每个阶段都有文档
- 能较好的与其它过程模型结合
- 不够灵活:下一阶段开始前,当前阶段的结果需固定下来
- 整体性太强:分析阶段出现任何失误,交互用户后才能发现,增加了开发的风险
- 严格文档驱动,较为繁琐
- 开发早期投入大量成本,难以应对用户需求变更
瀑布模型适用于:需求很明确且将来没有太大改变的情况。大型项目中一些部分的开发。
演化模型(分为原型模型和并行开发模型):
首先实现软件最核心,最重要的功能,待用户进一步了解软件后再实现细节。
相比瀑布模型能更高效地生产出符合要求的系统,灵活面对客户需求变更。
小型和中型系统:演化模型
大型系统:混合瀑布模型和演化模型(采用演化模型难以建立稳定的系统架构,不利于团队工作整合)
原型模型:
快速建立起可以在计算机上运行的程序,是最终产品的子集。
与用户确定下原型以后,再开始完整的开发过程。
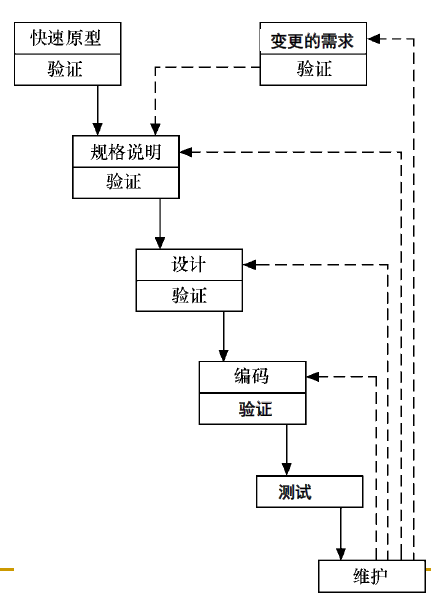
原型确定后,下面的开发过程基本不带反馈。
原型模型的优缺点:
-
- 有助于了解用户的真正需求
- 不会因为需求规格说明文档的错误进行大规模返工
- 开发人员在实现原型系统学到了东西,后续出错率降低
- 为了快速开发出原型,开发人员可能不会长远考虑,而降低质量,放弃部分需求
并行开发模型(并发模型):
所有活动同时存在但是处于不同状态。
增量过程模型(分为增量模型,RAD模型,螺旋模型):
非整体开发的模型,从部分需求出发,建立一个不完整的系统——测试——添加增量。
增量模型:
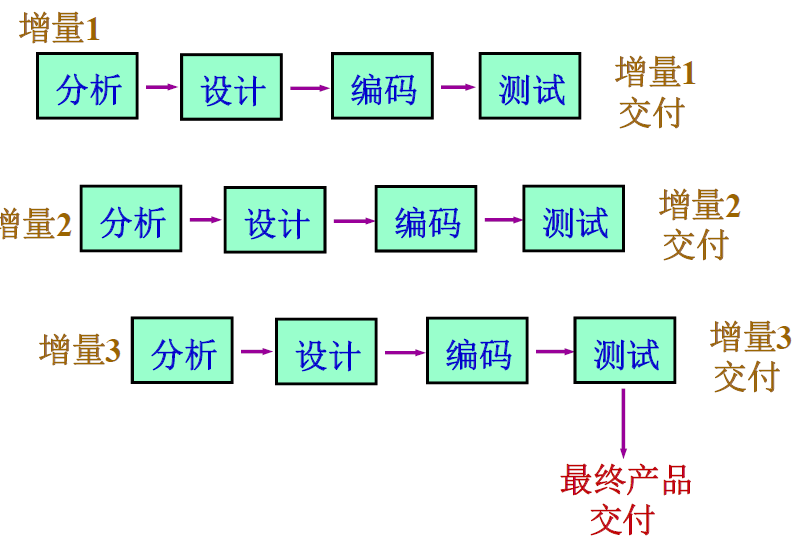
增量:小而可用的软件
- 增量模型与原型模型的不同在于:每个增量都是可运行的产品,能完成特定功能。
- 每个增量的开发可以采用瀑布模型或快速原型模型。
- 第一个增量通常是核心产品。
- 在前面增量的基础上开发后面的增量。
- 一个增量部署后,进入下一次迭代,直到出现最终产品。
- XP极限编程:基于小增量的开发和交付
增量模型的优缺点:
- 无需完整需求,只要一个增量包,开发即可进行。
- 项目初始阶段无需大量人力资源,被认可后才投入。
- 不能在ddl前完成项目,核心增量产品也能交付。
- 很难根据需求给出大小合适的增量。
- 加入新增量不能破坏已开发出的产品。
- 需要比瀑布和原型模型更精心的设计。
RAD(Rapid Application Development)快速应用开发模型:
- 强调短暂的开发周期,瀑布模型的“高速”变体
- 主要用于信息系统的开发
- 包括业务建模,数据建模,过程建模
- 需要足够的人力资源
- 并非所有系统都适合,不能合理模块化和技术风险高的系统都不适合
螺旋模型:
结合了瀑布模型和原型模型,加入了两种模型都没有的风险分析。
强调风险管理:适用于大型系统的开发。
基本思想:使用原型及其它方法来尽量降低风险。

理解为:在每个阶段都加入风险分析的快速原型模型
特点:
- 能应对开发过程中的各种变化。
- 仅适用于内部项目,不能用于合同性的软件开发,因为过程中有风险评估。
- 风险驱动:要求开发人员具有丰富的风险评估经验和专业知识。
- 只适用于大型软件的开发。
基于构件的模型:
- 构件(也称组件):支持软件重用(复用)Software Reuse
- 以重用为导向,以大量可用的组件及一些集成框架为基础。
- 根据需求规格搜索可重用的组件,通常情况下没有,则对组件加以修改或构造新的组件,再将组件进行开发和集成。
敏捷过程模型:
基本原理和开发过程的结合。
如何选择过程模型?
- 各种过程模型并不互相排斥,在开发中通常一起使用。
- 软件过程决定了软件产品的质量。
- 可根据实际创造新的模型。
软件开发中的两种倾向:以产品为中心/以过程为中心(以过程为中心更能生产高质量的产品)
能力成熟度模型:
软件过程成熟度:1.角色与职责 2.处理变更的方式 3.对发生问题的反应 4.可信性 5.对工作人员的奖励 6.预见性
CMM(Capibility Maturity Model):能力成熟度模型:
- 最早提出时,它指的是软件过程能力成熟度模型。
- 按照成熟度划分为5个等级。1级最低,5级最高。
SEI(Software Engineering Institute):软件工程研究所(发布CMM,CMMI)
CMMI(Capibility Maturity Model Integration):能力成熟度模型集成
CMMI 1.2:当前实施的有效版本
- 将成熟度分为5个等级,只有达到某个等级后,才能进入下一等级。
- 只定义要达到什么目标,不定义如何达到。
- 初始级:依赖于有能力的人
- 可重复级:有基本的项目管理
- 已定义级:过程标准化
- 量化管理级:收集分析数据,来支持决策。制定量化目标,以此作为管理过程的标准
- 优化级:持续地改进过程
过程域(Process Area PA):
CMMI每个等级都规定了过程域。即若干个值得重视的软件过程。