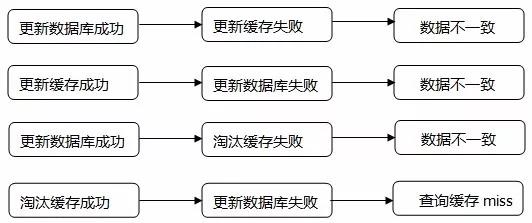
缓存一致性问题
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
缓存穿透问题
缓存穿透在有些地方也称为“缓存击穿”。大多数人对缓存穿透的理解是:由于缓存故障或者缓存过期导致大量并发请求穿透到后端数据库服务器,从而对数据库造成巨大冲击。
下列几种情况,可能导致缓存穿透问题。
缓存并发导致的穿透问题
缓存过期后将尝试从后端数据库获取数据,这是一个看似合理的流程。但是,在高并发场景下,请求并发的穿透到数据库中获取数据,对后端数据库造成极大的冲击,甚至导致“雪崩”现象。此外,当某个缓存key在被更新时,同时也可能被大量请求在获取,这也会导致一致性的问题。那如何避免类似问题呢?我们会想到类似“锁”的机制,在缓存更新或者过期的情况下,先尝试获取到锁,当更新或者从数据库获取完成后再释放锁,其他的请求只需要牺牲一定的等待时间,即可直接从缓存中继续获取数据。如图:

缓存不命中导致的穿透问题
在高并发场景下,如果某一个key被高并发访问,没有被命中(查出来为空),出于容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求达到数据库。而当该key对应在数据库中的数据本身就为空的情况下,这就导致数据库中并发的去执行了很多不必要的查询,从而给数据库带来巨大冲击和压力。
可以通过下面的几种常用方式来避免缓存穿透问题:
-
缓存空对象
对查询结果为空的对象也进行缓存,如果是集合,可以缓存一个空的集合(非null),如果是缓存单个对象,可以通过字段标识来区分。这样避免请求穿透到后端数据库。同时,也需要保证缓存数据的时效性。这种方式实现起来成本较低,比较适合命中不高,但可能被频繁更新的数据。
-
单独过滤处理
对所有可能对应数据为空的key进行统一的存放,并在请求前做拦截,这样避免请求穿透到后端数据库。这种方式实现起来相对复杂,比较适合命中不高,但是更新不频繁的数据。
缓存颠簸问题
缓存的颠簸问题,有些地方可能被称为“缓存抖动”,可以看作是一种比“雪崩”更轻微的故障,但是也会在一段时间内对系统造成冲击和性能影响。一般是由于缓存节点故障导致。业内推荐的做法是通过一致性Hash算法(参考“一致性哈希算法原理”)来解决。
缓存的雪崩现象
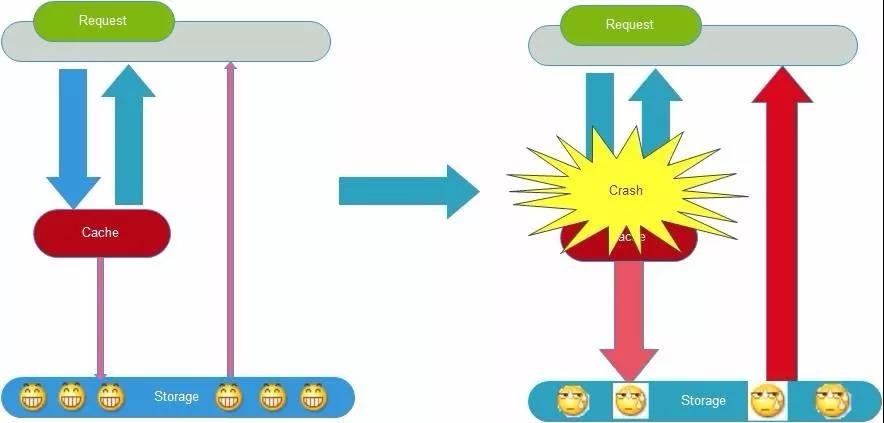
缓存雪崩就是指由于缓存的原因,导致大量请求到达后端数据库,从而导致数据库崩溃,整个系统崩溃,发生灾难。导致这种现象的原因有很多种,上面提到的“缓存并发”,“缓存穿透”,“缓存颠簸”等问题,其实都可能会导致缓存雪崩现象发生。这些问题也可能会被恶意攻击者所利用。还有一种情况,例如某个时间点内,系统预加载的缓存周期性集中失效了,也可能会导致雪崩。为了避免这种周期性失效,可以通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效。
从应用架构角度,我们可以通过限流、降级、熔断等手段来降低影响,也可以通过多级缓存来避免这种灾难。
此外,从整个研发体系流程的角度,应该加强压力测试,尽量模拟真实场景,尽早的暴露问题从而防范。
缓存并发导致的穿透问题如何解决
下面具体的聊聊我在实际工作中一般是如何应对解决“缓存并发穿透”问题的。
方案A(后台刷新):
在缓存过期之前,通过后台线程或者job主动更新缓存。例如,缓存的过期时间为30分钟,而后台job则每隔29分钟执行一次(job中查询出最新的数据并写入到缓存中)。
这种方案比较容易理解,但会增加系统复杂度。比较适合那些key相对固定、cache粒度较大的业务,key比较分散不确定的则不太适合,实现起来也比较复杂。
方案B(检查更新):
将缓存key的过期时间(绝对时间)也一起保存到缓存中(可以拼接,也可以加新字段,也可以采用单独的key保存,反正需要两者建立好关联关系)。在每次执行get操作后,都将get出来的缓存过期时间与当前系统时间做一个对比,如果发现缓存过期时间-当前系统时间<=1分钟,则主动更新缓存。这样就能保证缓存中始终是最新的(和方案A的思路本质上一样,就是为了保证缓存“始终是最新的”且“永不过期”),不用担心缓存失效和一致性的问题。当然,这个1分钟只是举例,可以根据实际情况定义或者配置的。
这种方案在特殊情况下也会有问题。假设缓存过期时间是11:30分,而11:29到11:30这1分钟时间里恰好没有get请求过来,恰好请求都在11:30分的时候并发过来,那就悲剧了。这种情况比较极端,但并不是没有可能。因为“高并发”也可能是阶段性在某个时间点爆发。
方案C(分级缓存):
分级缓存。采用L1和L2缓存方式,L1缓存失效时间短,L2缓存失效时间长。请求优先从L1缓存获取数据,如果L1缓存未命中则加锁,只有1个线程获取到锁,该线程从数据库中读取,再将数据set到L1缓存和L2缓存中,而其他线程依旧从L2缓存获取数据并返回。
这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰L1缓存,不能同时将L1和L2中的缓存同时淘汰。L2缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
方案D(互斥锁):
加锁等待。采用互斥锁的方式。
注意,不能直接在缓存加载逻辑判断时直接采用synchronize。下面列出几种常见做法:
方法1:
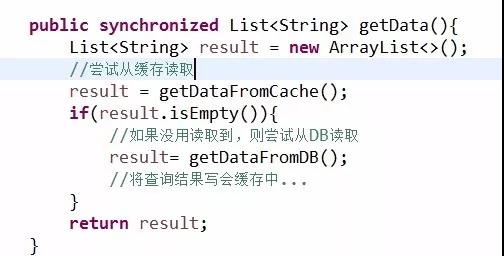
这种方式,确实能够防止缓存失效时并发打到数据库,但缓存没有失效的时候呢?也需要排队获取锁然后去获取数据,岂不是大大降低了系统的吞吐量。
还有另外一种写法:
方法2:
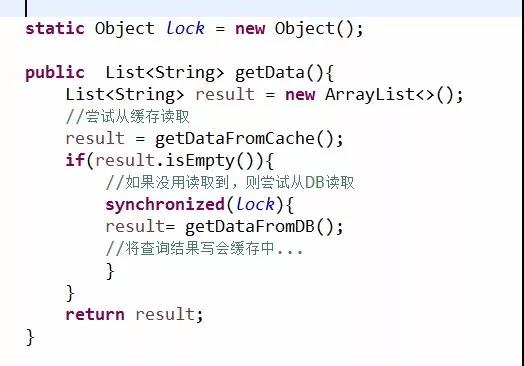
这种方式,当缓存命中的时候,系统的吞吐量是不会受影响的。但是,缓存失效的时候,请求还是会打到数据库中,只不过不是并发的,而是阻塞进行的,无疑会牺牲用户体验,并给数据库带来额外的压力。
方法3:

这种做法呢。似乎避免了前面那2种问题,但似乎还是不太完美。因为执行双重检查的那里,虽然是避免了请求打到数据库,但是命中缓存的过程依旧是排队进行的。
例如:当缓存失效时,有30个请求并发读库。使用同步加双重检查机制,可以让1个线程先读库然后写缓存了,剩下的29个线程命中缓存。但是,那29个线程是串行排队的在读缓存,效率方面肯定有影响。
方法4:

使用互斥锁的方式来实现,可以有效避免前面几种问题。为了方便演示和测试,就直接使用的Java中的ReentranLock。
在实际分布式场景中,可以使用redis、tair、zookeeper等提供的分布式锁来实现。
参考资料
缓存实战二三事:http://mp.weixin.qq.com/s/1fncm4s82C7J9r79w0pk8A
AutoLoadCache:https://github.com/qiujiayu/AutoLoadCache