一、循环链表
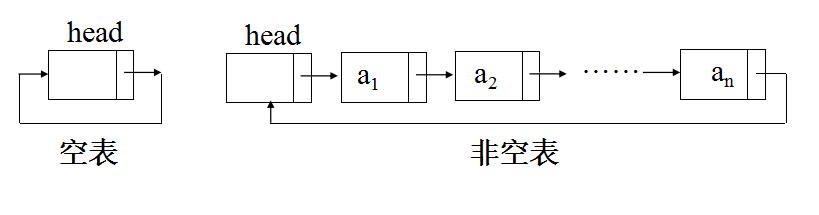
循环链表:是一种头尾相接的链表。其特点是最后一个结点的指针域指向链表的头结点,整个链表的指针域链接成一个环。
特点是: 从循环链表的任意一个结点出发都可以找到链表中的其它结点,使得表处理更加方便灵活。
其示意图如下图所示
循环链表的操作:
对于单循环链表,除链表的合并外,其它的操作和单线性链表基本上一致,仅仅需要在单线性链表操作算法基础上作以下简单修改:
⑴ 判断是否是空链表:head->next==head ;
⑵ 判断是否是表尾结点:p->next==head ;
二、双向链表
双向链表(Double Linked List) :指的是构成链表的每个结点中设立两个指针域:一个指向其直接前趋的指针域prior,一个指向其直接后继
的指针域next。这样形成的链表中有两个方向不同的链,故称为双向链表。
(1)双向链表的类型定义:
typedef struct Dulnode {
ElemType data ;
struct Dulnode *prior ,*next ;
}DulNode ;
其节点形式如下图所示:

带头结点的双向单链表如下图所示:

双向链表的特点有:
双向链表结构具有对称性,设p指向双向链表中的某一结点,则其对称性可用下式描述:
(p->prior)->next=p=(p->next)->prior ;
结点p的存储位置存放在其直接前趋结点p->prior的直接后继指针域中,同时也存放在其直接后继结点p->next的直接前趋指针域中。
(2)双向链表的基本操作
1、双向链表的插入: 将值为e的结点插入双向链表中。插入前后链表的变化如下图所示。
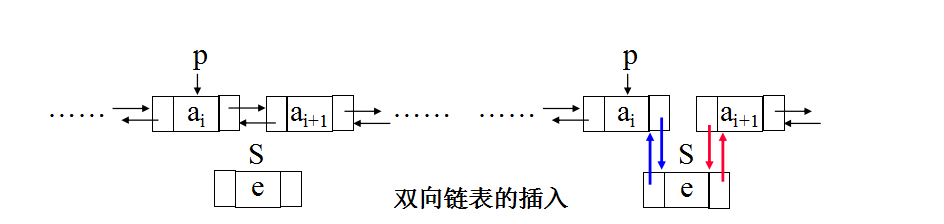
① 插入时仅仅指出直接前驱结点,钩链时必须注意先后次序是: “先右后左” 。部分语句组如下:
S=(DulNode *)malloc(sizeof(DulNode));
S->data=e;
S->next=p->next; p->next->prior=S;
p->next=S; S->prior=p; /* 钩链次序非常重要 */
② 插入时同时指出直接前驱结点p和直接后继结点q,钩链时无须注意先后次序。部分语句组如下:
S=(DulNode *)malloc(sizeof(DulNode));
S->data=e;
p->next=S; S->next=q;
S->prior=p; q->prior=S;
2、 双向链表的结点删除
设要删除的结点为p ,删除时可以不引入新的辅助指针变量,可以直接先断链,再释放结点。部分语句组如下:
p->prior->next=p->next;
p->next->prior=p->prior; free(p);
注意: 与单链表的插入和删除操作不同的是,在双向链表中插入和删除必须同时修改两个方向上的指针域的指向。