k8s简介
在学习k8s之前,相信大家和我一样,肯定都学习和使用过docker容器,并且对容器技术有了一个基本的认识。引用张磊老师的总结:其实一个“容器”,实际上是一个由Linux NameSpace、linux Cgroups和rootfs三种技术构建出来的进程隔离环境。
而k8s又是什么呢,官方给出的定义是:k8s是一个开源的容器集群管理系系统,可以实现容器集群的自动化部署、自动化扩容和维护等功能。说白了,我们是用k8s是为了管理docker集群,即docker可以看成k8s内部使用的低级别组件。但是k8s不仅仅支持docker,我们在
后面学习k8s的架构时候可以看到。
和很多其他组件先有工程实践,后有方法论的法杖路径不同。k8s的理论基础则比工程实践走的领先很多,这主要是得益于谷歌内部的Borg系统。k8s项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
在这面我们要先记住一个概念,Pod。它是k8s中的最小编排单位,而不是容器。因此后面的架构设计等内容都是围绕pod进行。
k8s的架构设计
k8s项目和它的原型项目Borg很类似,都是由Master和Node两种类型的节点组成,其主要架构如下:
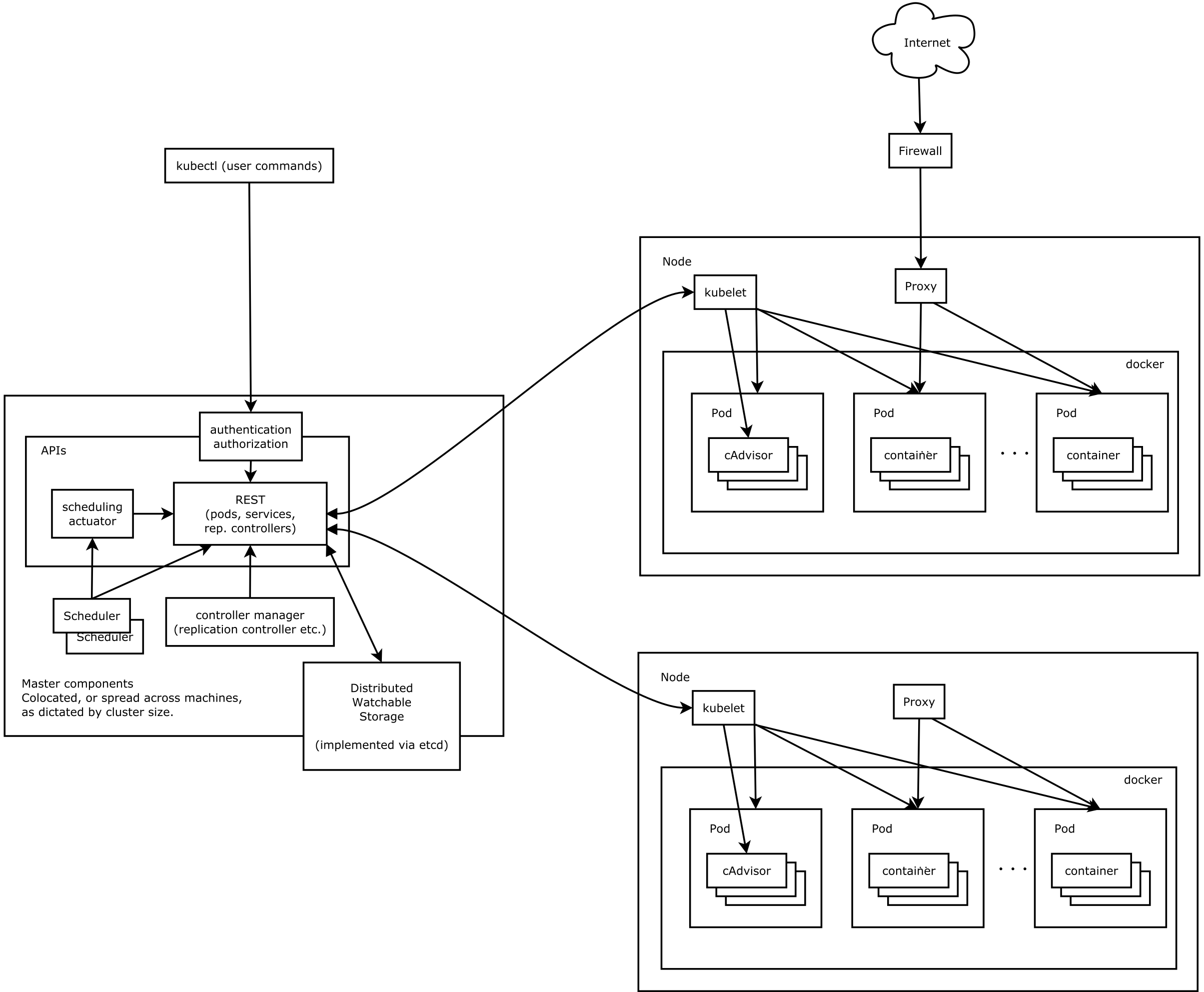
其中,Master节点由如下三个组件组成:
-
apiServer:提供了资源操作的唯一入口,并提供认证、授权,访问控制、API注册和发现等机制。并且将整个集群的数据处理以后,持久化到etcd当中。
-
controller manager:负责维护集群的状态,比如状态检测、自动扩展和滚动更新等
-
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上。
而在Node节点上,主要有以下一些核心组件:
-
kubelet:其是最核心的组件,主要负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理。
-
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)。
-
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡。
k8s的设计理念
对于云计算系统,系统API实际上处于系统设计的主导地位。在k8s中,系统没支持一项新功能,引入一项新技术,一定会引入对应的API对象,支持对该功能的管理操作。
每个API对象都有以下三个属性:
-
元数据(metadata):元数据是用来标识API对象的,每个对象至少有3个元数据,namespace,name和uid
-
规范(spec):规范描述了用户期望k8s急群众的分布式系统达到的理想状态,例如用户可以设置期望的Pod的副本数为3
-
状态(status):状态描述了系统当前实际达到的状态。