【前言】
使用DPDK开发的朋友应该都了解使用dpdk的fwd线程的工作模式是polling模式,即100%轮询的方式去加速网络IO,这样我们在操作系统层面上来观察目标processer会发现usage一直为100%,但是这真的是系统的真实负载么?很显然并不是,本文给出一种方法来计算dpdk的fwd线程的真实负载的方法。
【场景】
使用DPDK头痛的一点就是DPDK的fwd线程工作在polling模式,会直接消耗一整个processer的计算资源,有的时候为了性能考虑,往往还会给当前processer设置isolcpus,将当前processer从内核的CFS调度器中“剥离”出来,防止有其他的task被“不长眼”的CFS调度器调度到和fwd线程同一个processer上,出现context switch,引起性能下降。
而工作在polling模式的fwd线程会出现非常蛋疼的一点就是面临“无法有效的感知当前processer的压力”的问题。查看操作系统的相关信息,会发现这个processer的usage一直处于100%,但是真实情况真的是这样么?并不是,在流量处于低谷的时候,这个processer往往会出现空转的情况,就是调用dpdk的api收包函数调100次,次次收包个数都是0,因为根本就没有流量,所以需要一种新的方法来计算使用dpdk fwd线程的负载情况。
额外多说一点,为了防止fwd线程出现空转,目前有不同种方法来“尽量”解决这种空转问题,主流的通常有两种:
- 利用sleep函数,简单粗暴,结合内核的NAPI策略,设定一个期望收包个数值,当实际收包个数小于这个数值就判断当前流量不大,sleep一下。
- 利用dpdk的rsc中断来解决,由于uio驱动只有一个中断号,因此这种方法在uio驱动基本没法用,只能在vfio场景下用。
当然怎么防止dpdk fwd线程出现空转的解决方法不是这篇文章想讨论的主题,我后续会写我个人的解决方案,本篇文章更多的会聚焦在如何估算负载情况。
【分析】
这里首先说明一下,这个方法里面有一部分是来自于dpdk社区的一篇文章,由intel专家ilia所写,这里是文章原文地址,本文中会有不少部分来自于这篇文章原文,但是本篇文章在实际应用中仍然是有些地方需要注意的。
https://software.intel.com/en-us/vtune-cookbook-core-utilization-in-dpdk-apps
接下来我会结合实际应用和ilia的文章来阐述怎么“估算”dpdk fwd线程的负载情况。
先直接说结论:
在不同的流量压力下,dpdk fwd线程对某个网卡队列的收包行为实际上是存在一定的分布的
这句话怎么理解呢?实际上这句话就是intel专家ilia那篇文章的主要思想。这句话完整的解释是这样的:
在不同的流量压力下,dpdk fwd线程对某个网卡的某条队列进行收包操作,单位时间内的收包次数中,收到数据包的个数存在一定的分布
举个例子:
我在10s内,执行了1000次收包操作,在满载的流量压力下,1000次收包可能次次收包都能收上来32个数据包;在50%压力下,我可能只有300次收包是一次调用收上来32个包;在10%的压力下,我可能只有不到100次的收包是一次性收上来32个包。
如果能明白这个例子,就能明白前面所说的结论,关于这个结论可以直接看【测试结果】一章,观察测试结果是否符合结论。
以收包个数为0的次数为基准,那么可以推导出一个公式:
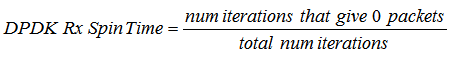
此公式也正是ilia的文章中提到的公式。
公式的解释就是在循环一定次数的收包情况下,收包个数为0的次数占比,即为dpdk rx spin time,直译就是dpdk 收包空转次数,那么再将此值用1减去,即可得到dpdk fwd的压力情况。
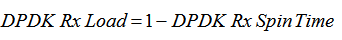
【测试结果】
以新建来测试上述公式的结果(新建比较吃cpu...)
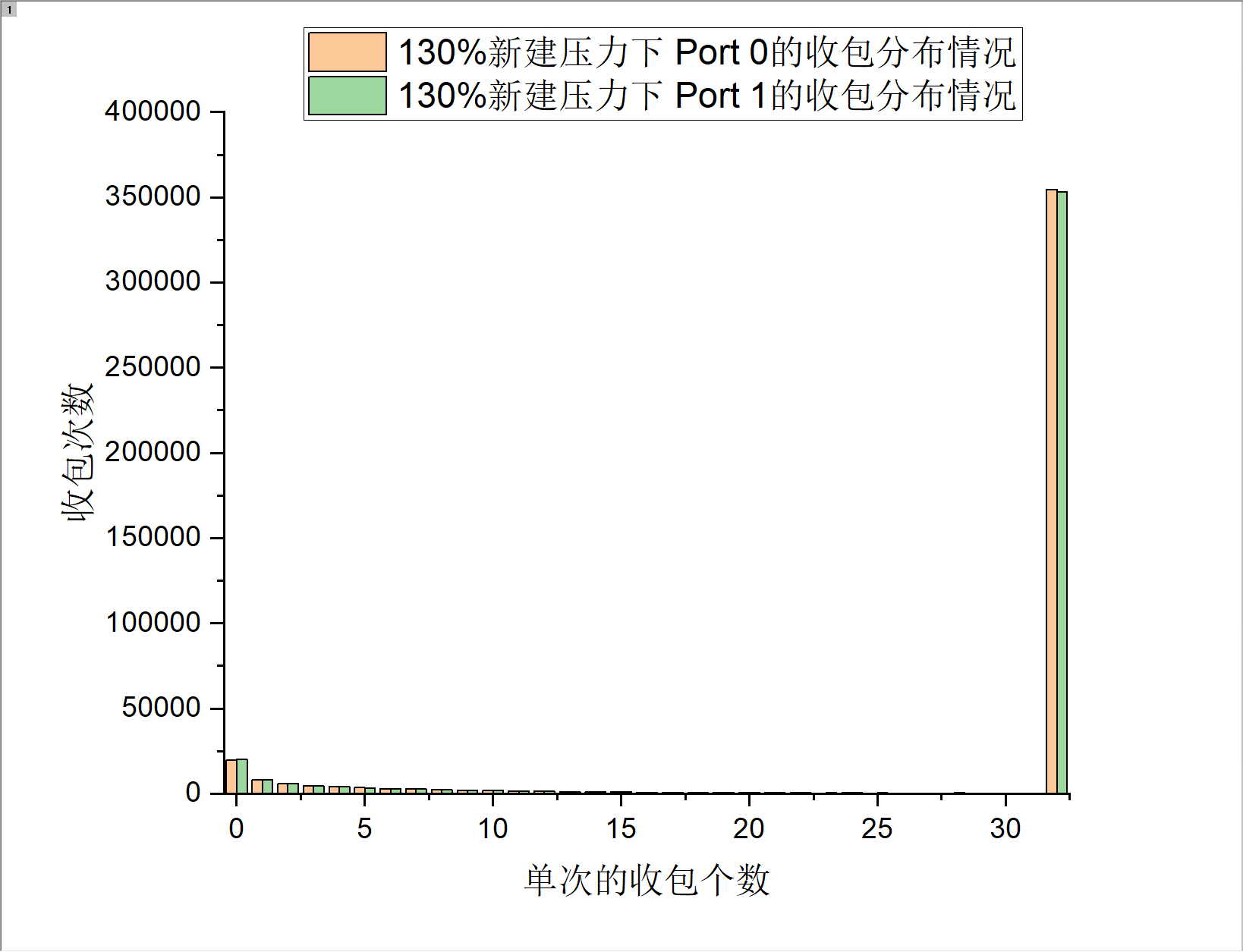
测试结果1
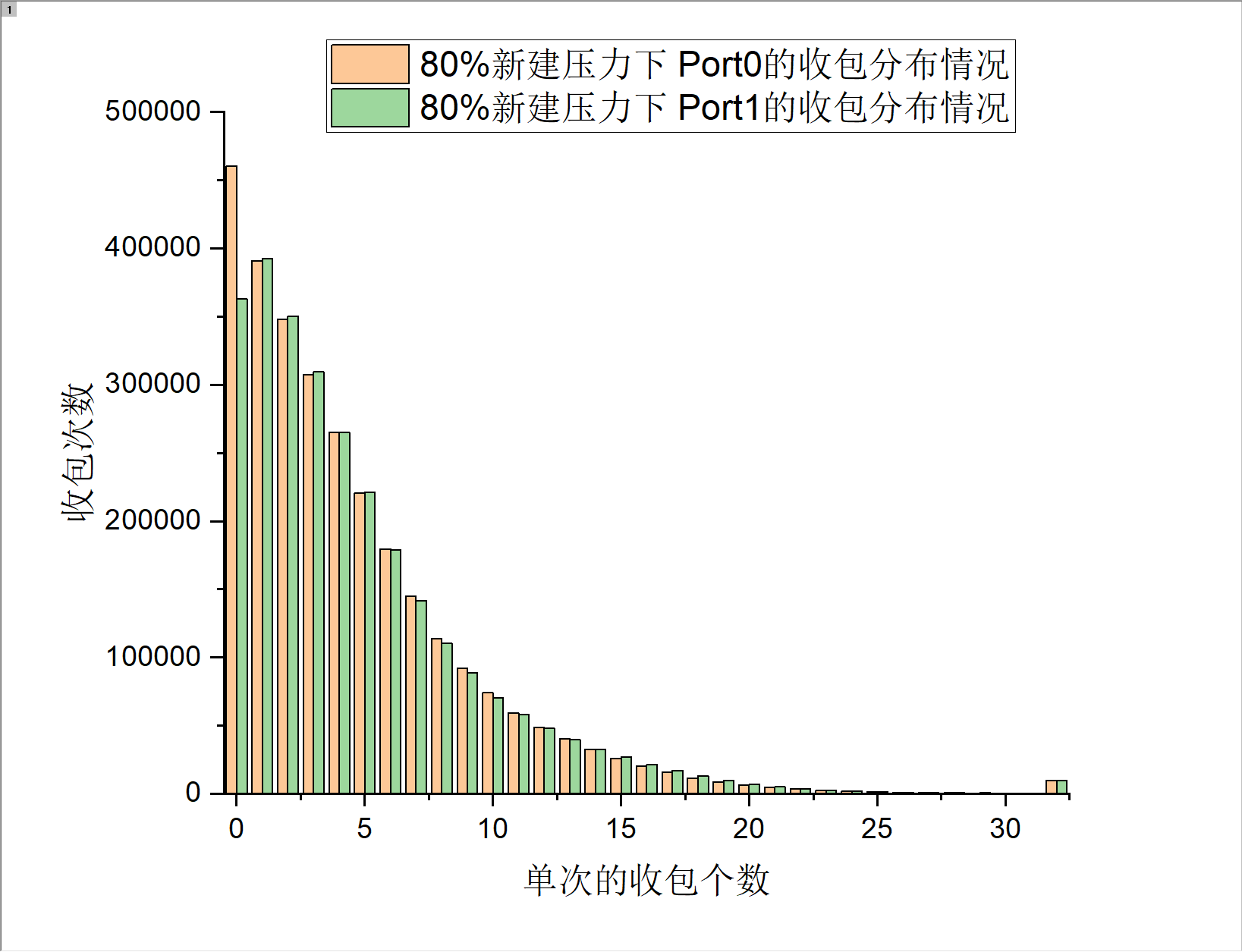
测试结果2
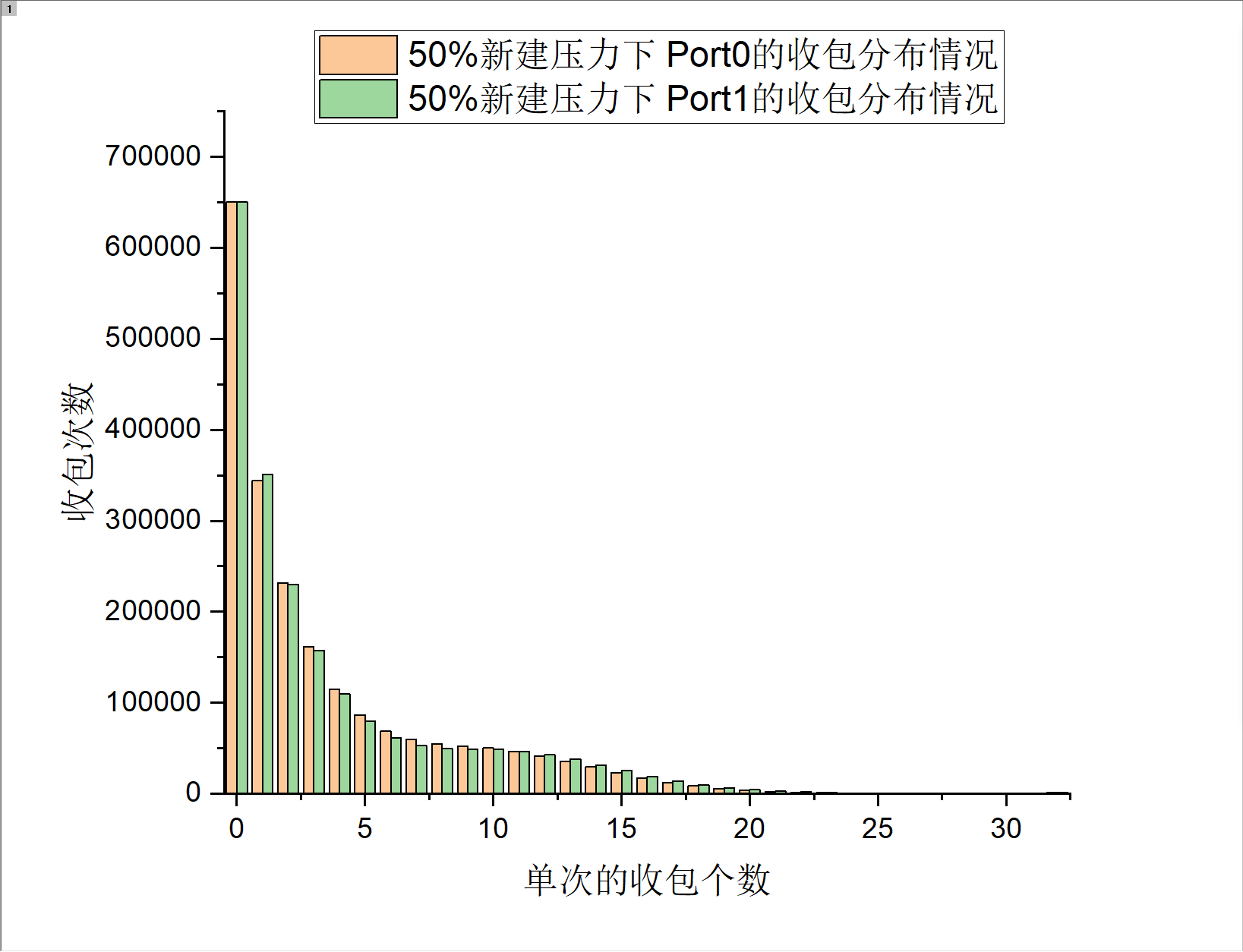
测试结果3
【结论】
根据测试结果来看,可以清晰的看到,在不同的系统压力下,DPDK在单位时间内的收包个数为0的次数占单位时间内总的收包次数的比重是存在一定分布的,在压力越高的情况下,收包为0的次数越少,在100%满载压力的情况下,收包个数为0的次数与收包个数为32的次数比的差距已经非常巨大,这也是ilia那篇文章中主要说的内容,但是是存在以下几个问题。
- 在真实场景下,一个fwd线程往往不止对单独的某个网卡队列进行收包,可能会有多个网卡队列,这个时候怎么来评估负载呢?
- 这种估算方法实际上依赖于DPDK的收包队列,但是如果某个fwd线程没有队列呢?这种情况往往发生在设备processer的数量大于所有的网卡队列之和的情况。就是所谓的“僧多粥少”情况,面对这种情况,常见的处理方法是接管网卡驱动的processer收上来数据包后,通过计算RSS将数据包通过ring发送到其他没有接管网卡队列的processer上,那么面对这些没有“抢到”网卡队列的processer来说,怎么计算出负载呢?
- fwd线程使用了sleep方法来休眠减少空转,理论上经过sleep后会影响最终估算的“负载”,使计算的负载值偏大。这个也很好理解,利用进程sleep的方法去减少压力,最常见的影响就是包的时延会增大,数据包会在进程睡眠的时候在rx ring中“积压”,那么每次收数据包的时候收到的数据包的个数就会偏多,出现0的次数就会少。
- fwd线程开了rxq中断,这种情况也不需要用本文的方法去计算负载了,直接pidstat就可以看了...
面对上述几个问题:
- 多队列的情况下,我个人认为可以采取方案是取压力最大的队列的压力值,实际测试之后发现效果还不错,因此最后采用了这种方案。
- 这种情况下,我个人觉得可以通过和收网卡队列相同的思路,在没有接管到网卡队列的fwd线程去收ring中的数据包时,也采用这种计算策略,当时由于需求问题,我本人并没有验证,有兴趣的道友可以去尝试一下。
- sleep的这种情况比较难以避免,需要根据实际情况去分析,由于采用sleep降低空转的策略中常常会有两个参数,一个是sleep的时间,一个是期望的权重,我本人实际测试,这两者的参数设置的不同对负载的估算是不同的,同样需要实际场景你测试调整。
【另一个问题:DPDK应用怎么“预见”即将可能发生的流量过载】
在估算出实际fwd线程的压力后,会发现有这样的一个问题,系统可以感知逼近的压力,但是无法得知压力的具体大小,举个例子,当上述公式计算出最后fwd线程压力为100%时,此时是过载还是满载呢?在性能测试时,这两种状态虽然在表现上是压力皆为100%,但是满载的情况下,并不会发生丢包,而过载的情况下网卡会发生无差别丢包。
相信搞过性能的朋友常常会遇到一种丢包情况:
rx_missed
rx_missed,这种错误在性能测试时测试系统上线会常常预见,在传统linux场景下,利用ethtool -S [port name]即可观察到此种丢包。这种丢包常常是由于网卡的rx队列被数据包“打爆”了,cpu收包的速度比不上实际数据包来的速度,那么就会形成类似于“漏斗”一样的流程,漏斗上方的进水量大于漏斗下方的出水量,那么只要时间足够,漏斗上方溢水是迟早的事情。在网卡收包时,cpu从rx ring中收取数据包,但是当流量压力过大时,rx ring会充满待处理的数据包,此时网卡无法再将数据包扔到rx ring中,那么网卡会将接下来来临的数据包进行无差别丢弃,并在rx_missed计数上进行增加。
那么面对这种场景,有没有方法可以尽可能的预见到即将可能来临的流量高峰呢?经过上述的叙述相信心中已经有了一种答案,那就是查看网卡rx ring,查看rx ring中还有多少待处理的描述符(description)即可,这里需要对processer怎么从网卡上收包有一定了解,不了解的话也没关系,我大概介绍一下原理接口,先上图
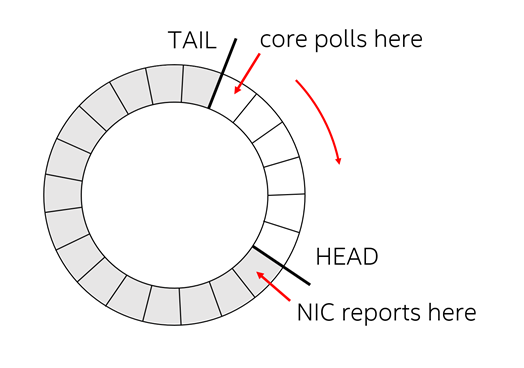
图4.收包原理图
P.S.这个图同样来自ilia专家的那篇文章中,感谢专家...
上图是一个网卡和processer常见的收包协作图(发包就是反过来),通常网卡的rx ring上会有两个index变量,一个叫做Head,一个叫做Tail,网卡会将收取的数据包push到Head指向的包描述符的内存中(不知道描述符是啥的童鞋就当做网卡收包向Head指针指向的空间去扔就行了),然后Head++,同样,processer从Tail指向的包描述符的内存中去收数据包,这样一个环形队列,网卡作为producer,而processer作为consumer演出了一场网卡收包的协奏。这种场景下,并且网卡在将数据包扔到rx ring时,会将对应位置的包描述符回写一个0x01的状态位,以ixgbe驱动为例:代码目录drivers/net/ixgbe/base/ixgbe_type.h
/* Receive Descriptor bit definitions */ #define IXGBE_RXD_STAT_DD 0x01 /* Descriptor Done */ #define IXGBE_RXD_STAT_EOP 0x02 /* End of Packet */ #define IXGBE_RXD_STAT_FLM 0x04 /* FDir Match */ #define IXGBE_RXD_STAT_VP 0x08 /* IEEE VLAN Packet */
也就是上述代码中的IXGBE_RXD_STAT_DD标志,那综上所述,我们只需要统计Tai -> Head之间有多少个0X01状态的描述符就可以确定(也就是上述图4的右侧Tail和Head之间的方块数),目前网卡rx ring中“积存”了多少数据包。
但是,上述在操作,在DPDK的代码中都已经实现啦!
uint32_t
ixgbe_dev_rx_queue_count(struct rte_eth_dev *dev, uint16_t rx_queue_id)
{
#define IXGBE_RXQ_SCAN_INTERVAL 4
volatile union ixgbe_adv_rx_desc *rxdp;
struct ixgbe_rx_queue *rxq;
uint32_t desc = 0;
rxq = dev->data->rx_queues[rx_queue_id];
rxdp = &(rxq->rx_ring[rxq->rx_tail]);
while ((desc < rxq->nb_rx_desc) &&
(rxdp->wb.upper.status_error &
rte_cpu_to_le_32(IXGBE_RXDADV_STAT_DD))) {
desc += IXGBE_RXQ_SCAN_INTERVAL;
rxdp += IXGBE_RXQ_SCAN_INTERVAL;
if (rxq->rx_tail + desc >= rxq->nb_rx_desc)
rxdp = &(rxq->rx_ring[rxq->rx_tail +
desc - rxq->nb_rx_desc]);
}
return desc;
}
上述代码位置:drivers/net/ixgbe/ixgbe_rxtx.c中,但是上述函数有个很大的问题就是时间复杂度很高...最极端的情况下要循环4096/4 = 1024次(网卡rx ring最大4096,4是由于上述函数遍历的步长为4)才可以算出有多少个待处理的包。所以上述函数可以利用二分法来加速获取计算的过程,最极端的情况下也只需要循环12次就可以算出网卡队列中积存的数据包个数,关键就在于IXGBE_RXDADV_STAT_DD这个标志,这里就不说了,有兴趣的可以思考一下。
那得到了网卡队列中积存的数据包个数之后我们怎么才能判断出是否将要出现“过载流量”呢?
这个也很简单,只要网卡队列中积存的数据包处于一个较低的水平,那么就不会出现丢包的可能;如果网卡队列中积存的数据包数量突然上升,那么很有可能网卡的rx ring直接被流量打爆,在高端设备中,数据包量非常庞大的场景下,打爆最大4096长度的网卡队列(最多只能缓存4096个数据包)就是一瞬间的事情,这个同样也很好理解,还是以漏斗举例,实际上,如果注水的速度小于出水的速度,无论注水的时间长短,漏斗中积存的水量必定为一个较低的水平,或者是根本不会有积存的水量;而当注水的速度大于出水的速度,那么将漏斗打满只是时间问题。
经过我的实际测试,满载的情况下,网卡队列中积存的数据包一直处于300个以下的水平,但是只要测试机的网络流量超过了系统的处理能力,网卡队列中积存的数据包很快就上了1000以上.....
【一点想法】
单单靠ilia专家的公式只能计算出当前系统的压力情况(且有条件限制),无法预知即将到来的流量高峰;单单靠网卡rx ring中积存的数据包个数只能判断出即将来流量高峰,但是却无法得知fwd线程压力,那么我们需要一套组合拳:
if (fwd_rx_load >= 90 && rte_get_rx_queue_count() >= 512)
//需要采取措施,流量很可能即将过载