一:使用
1.实质
提供JDBC/ODBC连接的服务
服务运行方式是一个Spark的应用程序,只是这个应用程序支持JDBC/ODBC的连接,
所以:可以通过应用的4040页面来进行查看操作
2.启动服务

3.配置(已经被隐含)
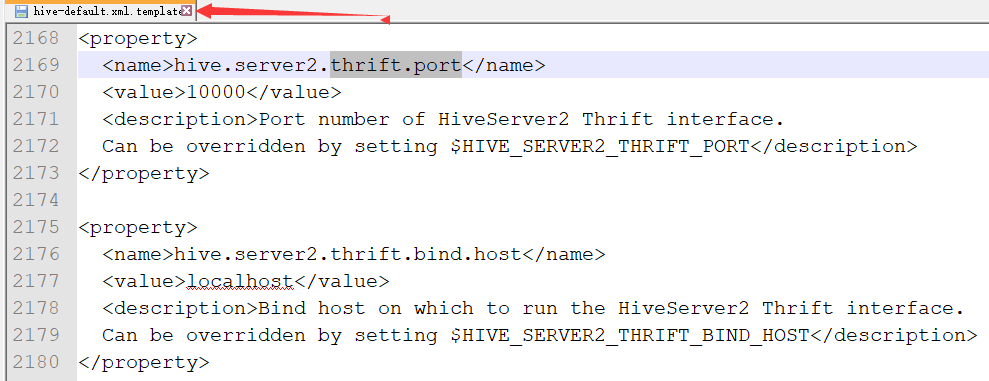
1. 配置thriftserver2的ip地址和端口号
修改hive-site.xml文件
hive.server2.thrift.port=10000
hive.server2.thrift.bind.host=localhost
2. 集成Hive环境(类似SparkSQL)
3. 启动服务
$ sbin/start-thriftserver.sh
$ sbin/stop-thriftserver.sh
4. 测试
二:测试
重要的是需要哪些服务的开启。
1.前提
首先是hadoop的两个服务要开启
然后是hive 的metastore
然后启动spark-shell,如果没有启动hive的metastore,则会在这一步报错,说找不到hive的9083端口。至于启动spark-shell,则是为了看4040端口上的JDBS/ODBC服务
然后启动hive thriftservice
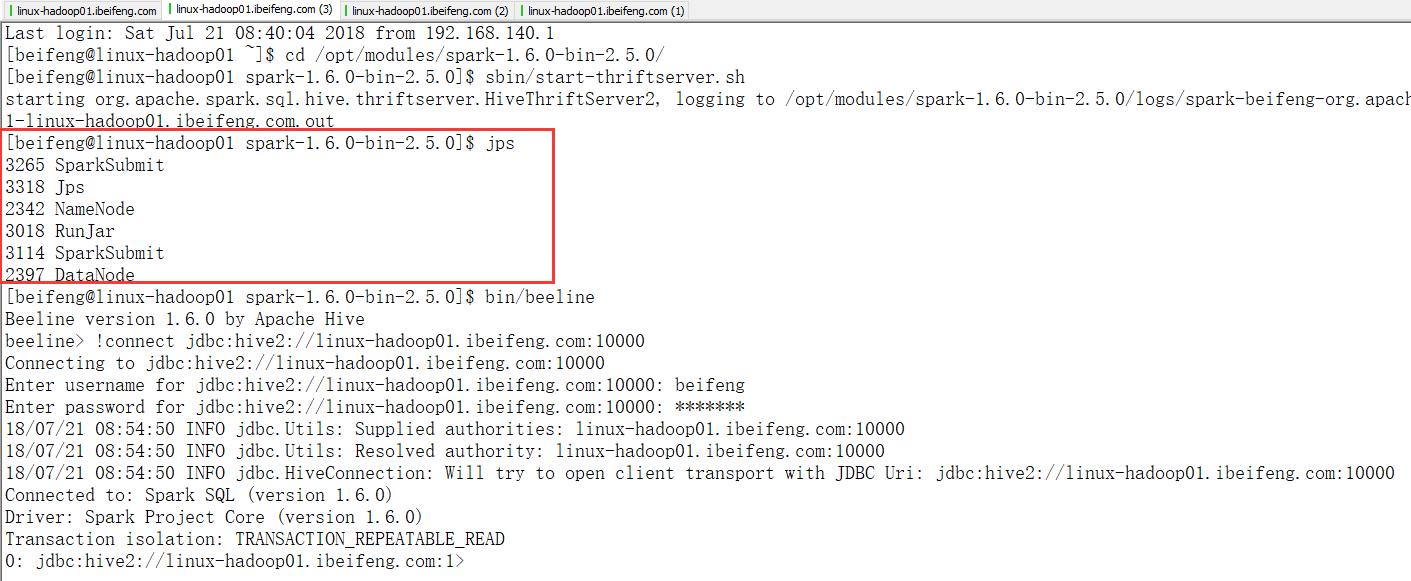
2.测试
命令行测试,使用beeline脚本连接
上面的截图已经操作了。

3.界面(4040端口)

4.测试sql语句
测试一:

测试二:

三:程序
1.结构
2.添加依赖包

3.程序
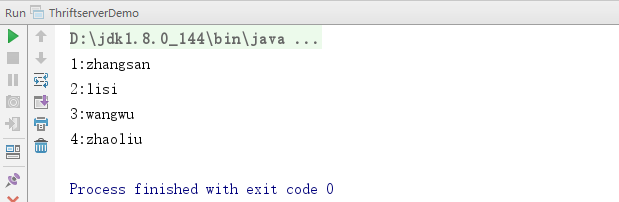
1 package com.scala.it 2 3 import java.sql.DriverManager 4 5 object ThriftserverDemo { 6 def main(args: Array[String]):Unit= { 7 //add driver 8 val driver="org.apache.hive.jdbc.HiveDriver" 9 Class.forName(driver) 10 11 //get connection 12 val (url,username,userpasswd)=("jdbc:hive2://linux-hadoop01.ibeifeng.com:10000","beifeng","beifeng") 13 val connection=DriverManager.getConnection(url,username,userpasswd) 14 15 //get statement 16 connection.prepareStatement("use hadoop09").execute() 17 val sql="select * from student" 18 val statement=connection.prepareStatement(sql) 19 20 //get result 21 val rs=statement.executeQuery() 22 while(rs.next()){ 23 println(s"${rs.getInt(1)}:${rs.getString(2)}") 24 } 25 26 //close 27 rs.close() 28 statement.close() 29 connection.close() 30 } 31 }
4.运行结果