1.广播变量机制
将传递给task的值,变成传递给executor。
为什么可以共用,因为task是executor下的线程。
只读的变量,在task中不允许修改

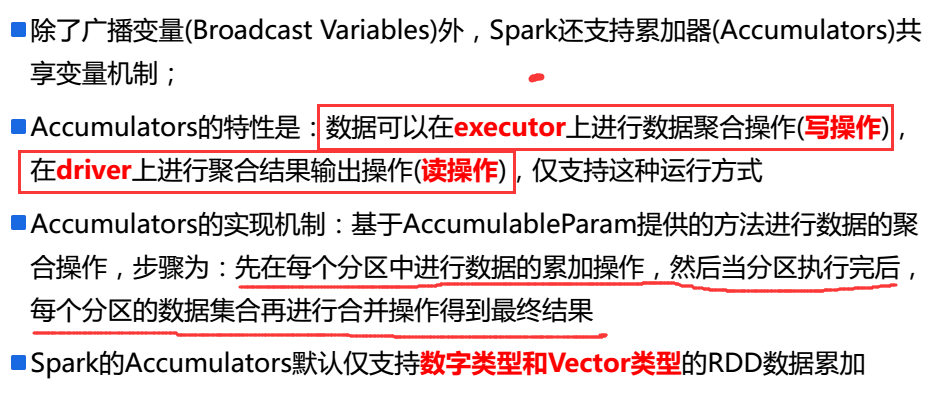
2.累加器介绍
在只写的变量,在task中只允许被修改,不允许读的操作。
但是在driver中就只能读操作。
3.程序
需求一:对应于MR中的累加器,累积计算次数
需求二:将累加器做成共享变量来使用。避免了shuffle过程,提高了效率。
1 package com.ibeifeng.senior.accumulator 2 3 import org.apache.spark.{AccumulableParam, SparkConf, SparkContext} 4 5 import scala.collection.mutable 6 import scala.util.Random 7 8 /** 9 * Spark累加器 10 * Created by ibf on 02/15. 11 */ 12 object AccumulatorDemo { 13 def main(args: Array[String]): Unit = { 14 val conf = new SparkConf() 15 //.setMaster("local[*]") // local模式下默认不进行失败重启机制 16 .setMaster("local[*,4]") // 开启local模式的失败重启机制,重启次数4-1=3次 17 .setAppName("accumulator") 18 val sc = SparkContext.getOrCreate(conf) 19 20 // =============================== 21 val rdd = sc.parallelize(Array( 22 "hadoop,spark,hbase", 23 "spark,hbase,hadoop", 24 "", 25 "spark,hive,hue", 26 "spark,hadoop", 27 "spark,,hadoop,hive", 28 "spark,hbase,hive", 29 "hadoop,hbase,hive", 30 "hive,hbase,spark,hadoop", 31 "hive,hbase,hadoop,hue" 32 ), 5) 33 34 // 需求一:实现WordCount程序,同时统计输入的记录数量以及最终输出结果的数量 35 val inputRecords = sc.accumulator(0, "Input Record Size") 36 val outputRecords = sc.accumulator(0, "Output Record Size") 37 rdd.flatMap(line => { 38 // 累计数量 39 inputRecords += 1 40 val nline = if (line == null) "" else line 41 // 进行数据分割、过滤、数据转换 42 nline.split(",") 43 .map(word => (word.trim, 1)) // 数据转换 44 .filter(_._1.nonEmpty) // word非空,进行数据过滤 45 }) 46 .reduceByKey(_ + _) 47 .foreachPartition(iter => { 48 iter.foreach(record => { 49 // 累计数据 50 outputRecords += 1 51 println(record) 52 }) 53 }) 54 55 println(s"Input Size:${inputRecords.value}") 56 println(s"Ouput Size:${outputRecords.value}") 57
58 // 需求二:假设wordcount的最终结果可以在driver/executor节点的内存中保存下,要求不通过reduceByKey相关API实现wordcount程序 59 /** 60 * 1. 每个分区进行wordcount的统计,将结果保存到累加器中 61 * 2. 当分区全部执行完后,各个分区的累加器数据进行聚合操作 62 */ 63 val mapAccumulable = sc.accumulable(mutable.Map[String, Int]())(MapAccumulableParam)//MapAccumulableParam是强制转换 64 try 65 rdd.foreachPartition(iter => { 66 val index = Random.nextInt(2) // index的取值范围[0,1] 67 iter.foreach(line => { 68 val r = 1 / index 69 print(r) 70 val nline = if (line == null) "" else line 71 // 进行数据分割、过滤、数据转换 72 nline.split(",") 73 .filter(_.trim.nonEmpty) // 过滤空单词 74 .map(word => { 75 mapAccumulable += word // 统计word出现的次数 76 }) 77 }) 78 }) 79 catch { 80 case e: Exception => println(s"异常:${e.getMessage}") 81 } 82 println("result================") 83 mapAccumulable.value.foreach(println) 84 85 Thread.sleep(100000) 86 } 87 } 88 89 90 object MapAccumulableParam extends AccumulableParam[mutable.Map[String, Int], String] { 91 /** 92 * 添加一个string的元素到累加器中 93 * 94 * @param r 95 * @param t 96 * @return 97 */ 98 override def addAccumulator(r: mutable.Map[String, Int], t: String): mutable.Map[String, Int] = { 99 r += t -> (1 + r.getOrElse(t, 0)) 100 } 101 102 /** 103 * 合并两个数据 104 * 105 * @param r1 106 * @param r2 107 * @return 108 */ 109 override def addInPlace(r1: mutable.Map[String, Int], r2: mutable.Map[String, Int]): mutable.Map[String, Int] = { 110 r2.foldLeft(r1)((a, b) => { 111 a += b._1 -> (a.getOrElse(b._1, 0) + b._2) 112 }) 113 } 114 115 /** 116 * 返回初始值 117 * 118 * @param initialValue 119 * @return 120 */ 121 override def zero(initialValue: mutable.Map[String, Int]): mutable.Map[String, Int] = initialValue 122 }