standalone也存在单节点问题,这里主要是配置两个master。
1.官网

2.具体的配置

3.配置方式一(不是太理想)
这种知识基于未来可以重启,但是不能在宕机的时候提供服务。
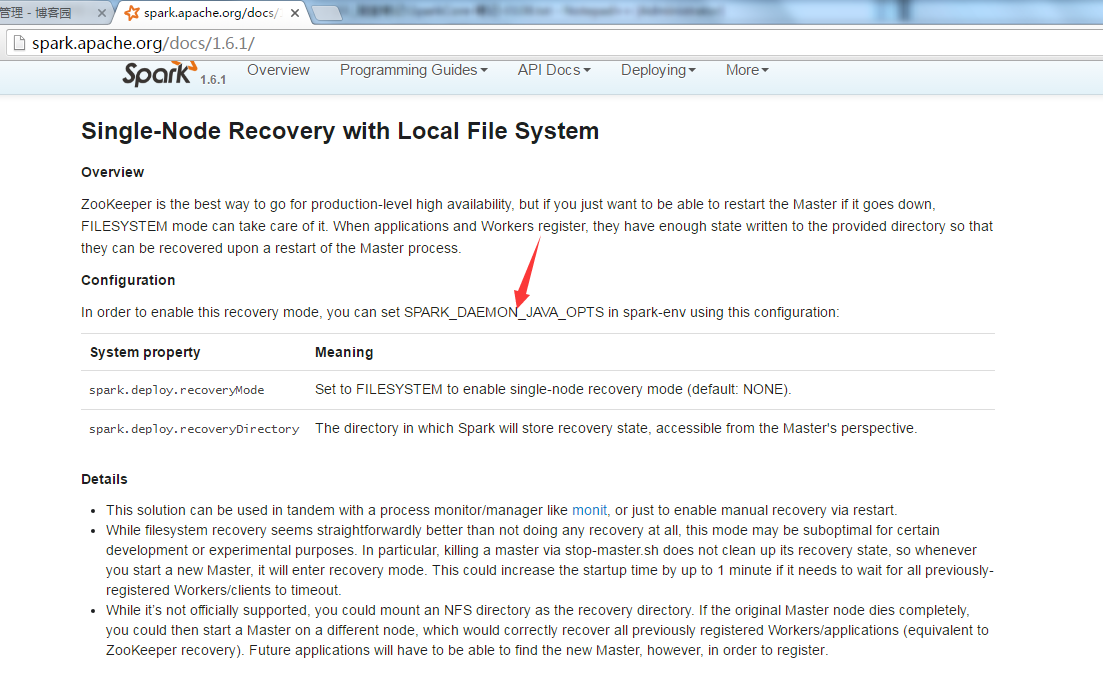
方式一:Single-Node Recovery with Local File System
类似于Hadoop1中的SecondaryNameNode
当出现单点故障的时候,需要手动启动master,然后master会读刚刚断掉之前的日志,类似于secondarynamenode方式。
做法:
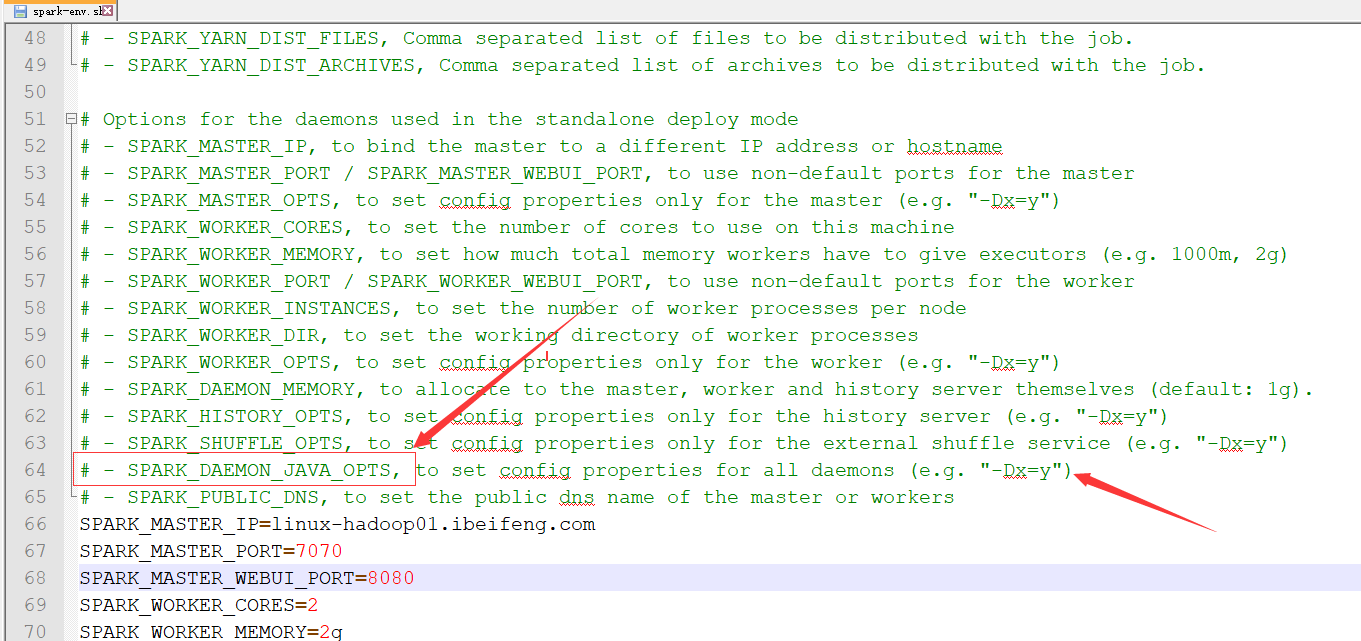
1. 修改conf/sparn-env.sh配置文件,打开conf/sparn-env.sh
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/tmp/xxxx"
一个参数是恢复模式,一个参数是恢复路劲
4.配置方式二(比较给力)
方式二:Standby Masters with ZooKeeper
类似于Hadoop2中的NameNode的HA机制,因此会自动转移
做法:
1. 修改conf/sparn-env.sh配置文件
2. 给参数SPARK_DAEMON_JAVA_OPTS添加配置参数
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop-senior01:2181,hadoop-senior02:2181,hadoop-senior03:2181 -Dspark.deploy.zookeeper.dir=/spark"
