一:hive中的三种join
1.map join
应用场景:小表join大表
一:设置mapjoin的方式:
)如果有一张表是小表,小表将自动执行map join。
默认是true。
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
</property>
)判断小表
<property>
<name>hive.mapjoin.smalltable.filesize</name>
<value>25000000</value>
</property>
二:隐式执行
/*+ MAPJOIN(tb_name) */
两种方式说明:

2.reduce join
应用场景:大表join大表
但是效率不高。
3.SMB join(sort merger bucket):hash取余
排序合并桶。
条件:A桶个数必须与B桶的个数相同,或者B桶的个数是A桶的个数的倍数
例如:
A:4
B:8
——》A的每一个桶joinB桶的两个小桶就可以了。
设置:
hive.auto.convert.sortmerge.join=true
二:数据倾斜
1.原因
指在mapreduce中某一个值数据量过多,导致reduce的负载不均衡
主要分为
join
group by
三:参考数据倾斜
1.链接
https://my.oschina.net/leejun2005/blog/178631
2.前言
在做Shuffle阶段的优化过程中,遇到了数据倾斜的问题,造成了对一些情况下优化效果不明显。
主要是因为在Job完成后的所得到的Counters是整个Job的总和,优化是基于这些Counters得出的平均值,而由于数据倾斜的原因造成map处理数据量的差异过大,
使得这些平均值能代表的价值降低。Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。
3.操作
其实就两种,因为,count distinct的底层就是group by。
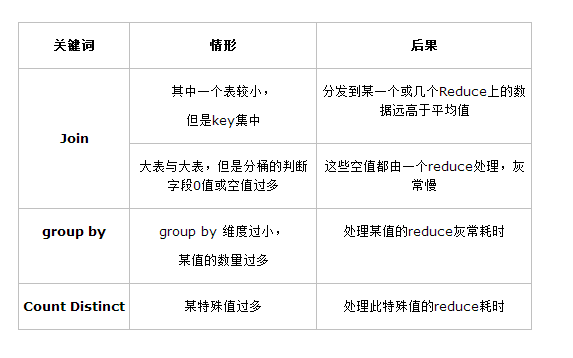
4.原因
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
5.表现
任务进度长时间维持在99%,查看任务监控页面,发现只有少量的reduce子系统未完成。
单一的reduce的记录与平均记录差距过大,通常达到3倍甚至更多。
四:解决方案
1.主要针对的group by
map的combiner
hive.groupby.skewindata
替换值,将不要的值替换掉,然后过滤掉。
2.参数调节
)hive.map.aggr=true
map端的combiner,提前聚合一下。
)hive.groupby.skewindata=true
不按照key进行分区,map端的结果到了reduce后就进行一次聚合,达到reduce负载均衡。
这时,再进行一次mapreduce,group by key 分布到reduce,实现最终的聚合。
2.SQL调节
)如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
)大小表Join:
使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce.
)大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
)count distinct大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。
如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
)group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。
五:业务场景(实际中会遇到的情况)
1.空值产生数据倾斜
)过滤
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all select * from log a where a.user_id is null;
)赋予新的值
select *
from log a left outer join users b on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
)比较
方法2比方法1效率更好,不但io少了,而且作业数也少了。
解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 。
2适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
2.不同的数据类型进行关联
)原因
用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分 配,这样会导致所有string类型id的记录都分配到一个Reducer中。
)把数字类型转换成字符串类型
select * from users a
left outer join logs b on a.usr_id = cast(b.user_id as string)
3.表不大不小
)解决
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;