为什么使用CDH版本?
这个主要考虑到兼容性。
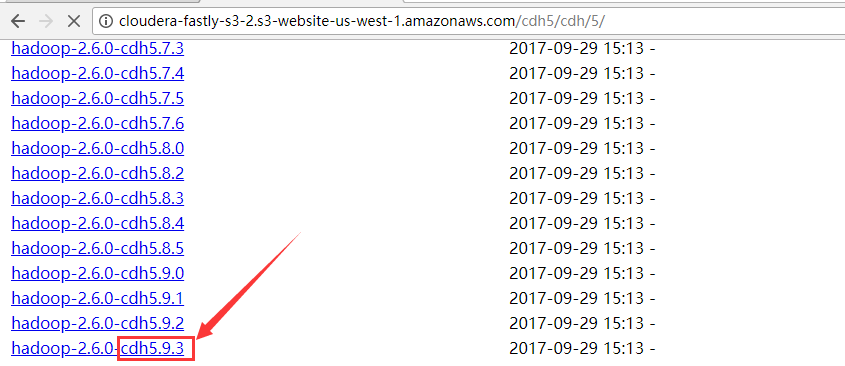
下载地址:http://archive.cloudera.com/cdh5/cdh/5
最新的CDH公司的hadoop版本:
一:准备工作
1.步骤
1)hadoop
-》下载解压
-》修改配置文件
-》hadoop-env
JAVA_HOME
-》core-site
fs.defaultFS
hadoop.tmp.dir
-》hdfs-site
dfs.replication
permission
-》mapred-site
mapreduce.frame.work
historyserver
-》yarn-site
mapreduce-》shuffle
resourcemanager地址:0.0.0.0
日志聚集
-》yarn-env
JAVA_HOME
-》slaves
datanode/nodemanager hostname
-》格式化
bin/hdfs namenode -formatf
-》启动
2)hive
-》下载解压
-》创建数据仓库
/user/hive/warehouse
-》修改配置
-》hive-env
HADOOP_HOME
HIVE_CONF_DIR
-》log4j
-》日志目录
-》hive-site
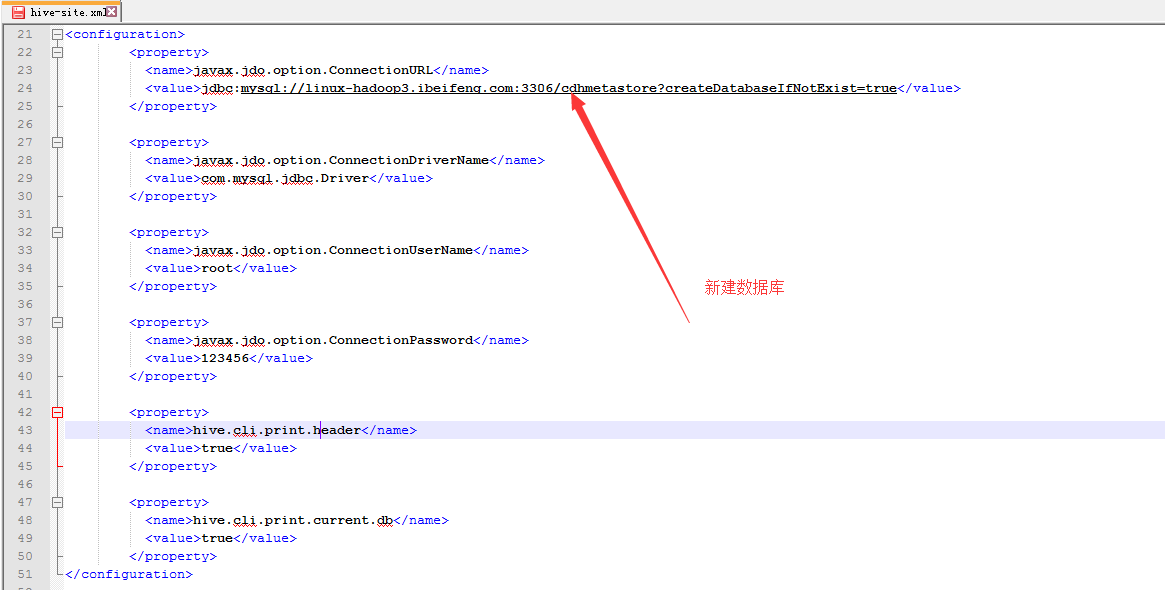
-》连接mysql
-》数据库地址
-》连接驱动
-》用户名
-》密码
-》显示当前数据库
-》显示表头
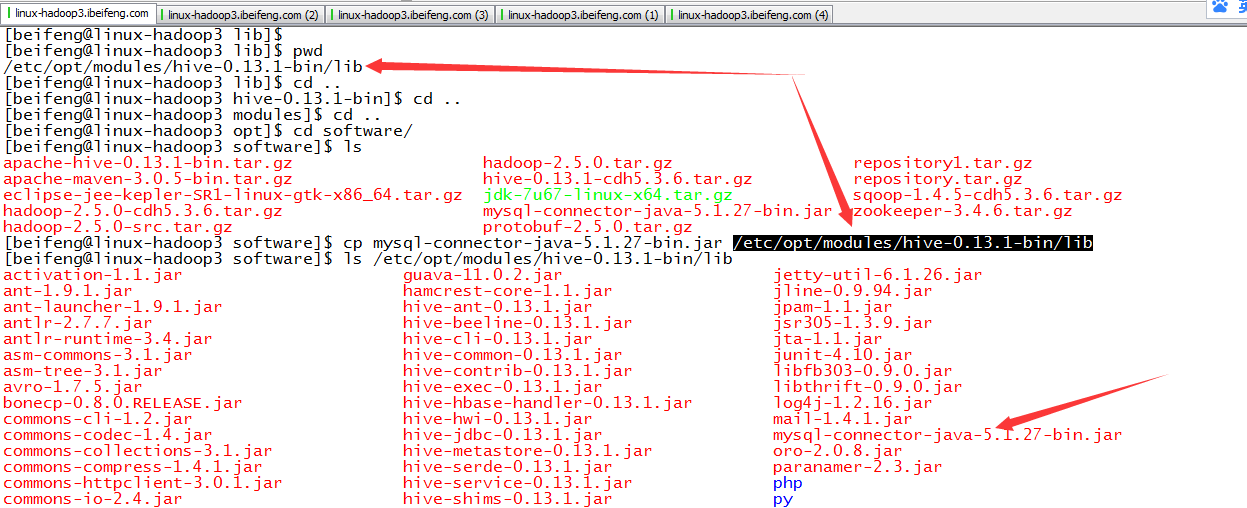
-》把mysql连接驱动放入lib
-》启动
3)sqoop
-》解压
-》修改*env.sh
-》加载驱动
-》驱动
二:安装Hadoop
1.新建目录cdh-5.3.6,并修改权限

2.解压

3.修改/etc/profile

4.配置*env.sh中的JAVA_HOME
5.配置core-site.xml环境

6.配置hdfs-site.xml环境

7.配置mapred-site.xml

8.配置slaves

9.配置yarn-site.xml

10.格式化

11.启动

三:hive
1.解压

2.在HDFS上创建数据仓库并修改权限
在hadoop主目录下创建并修改权限。

3.启用一些配置

4.配置env.sh
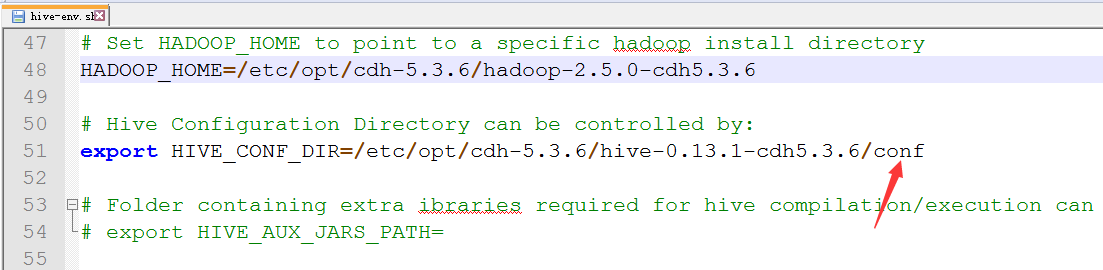
5.log4j的配置

6.hive-site.xml的配置
7.加载驱动
8.启动hive之前mysql的内容

9.启动

10.出现新的数据库

四:sqoop
1.概述
用于关系型数据库与hadoop之间的数据转换。
底层是mapreduce模板,通过不同的参数,封装打包成jar,提交给yarn。
导入与导出是基于hdfs而言。
2.解压到cdh-5.3.6
3.拷贝相关的配置文件

4.配置sqoop.env.sh

5.加载驱动

6.简单使用
