一:概述
1.单个namenode的局限性
namespace的限制
单个namenode所能存储的对象受到JVM中的heap size的限制
namenode的扩张性
不可以水平扩张
隔离性
单个namenode难以提供隔离性,各自管理自己的数据,只是共享一个存储领域。
截图:

2.好处(可以与HA兼容)
各自管理各自的数据
共享数据空间

二:配置hdfs-site.xml
1.配置
配置三台namenode,但是这里只有第一台的配置,将下面的配置再拷贝两份,修改成对应的namenode的机器。
8022,可以减缓端口号的压力。

2.分发
3.格式化namenodes
$HADOOP_PREFIX_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
需要格式化三台namenode。
需要有相同的集群名,就是上面的<cluster_id>,就是说namenode所在的机器的格式化语句都是相同的。
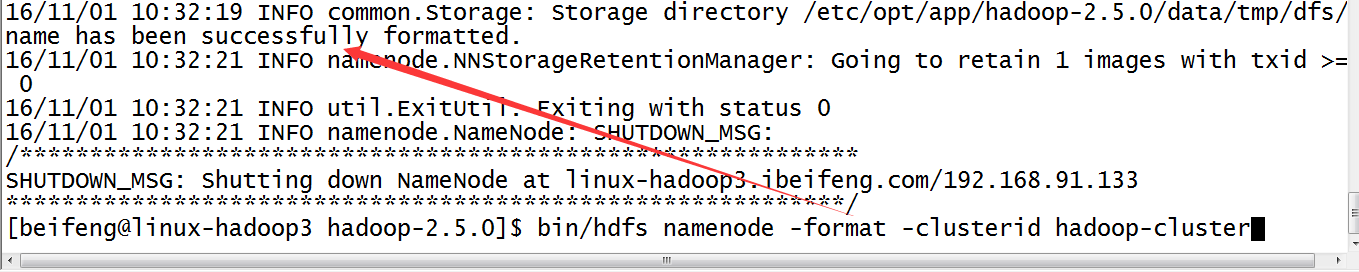
4.启动集群
三台机器都可以启动namenode与datanode。
会发现三台机器都是active。
三:观察效果
证明,各个namenode互不影响
1.测试一
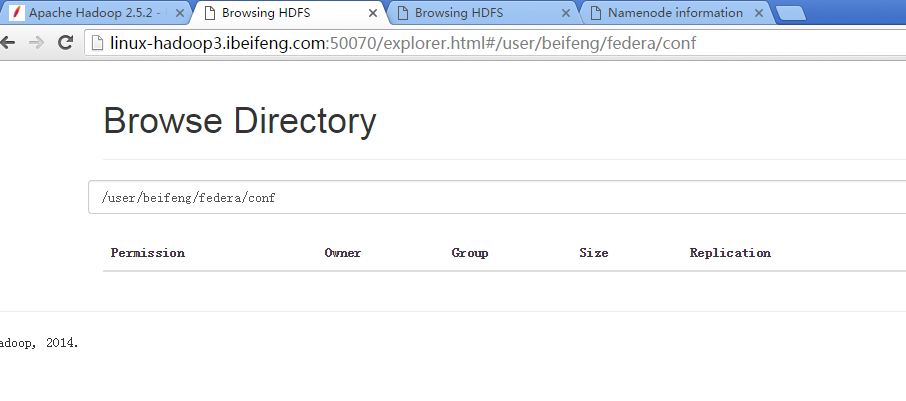
2.在第一台虚拟机上新建目录
会在第一台上看见这个目录,但是在第二台虚拟机上看不到这个目录。
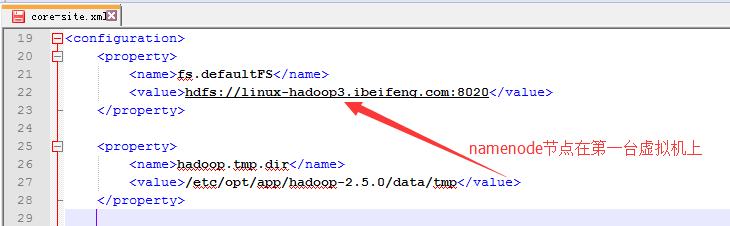
3.然后,修改core

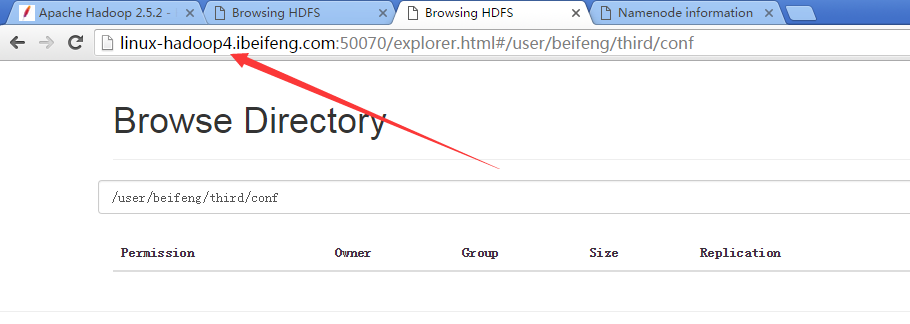
4.在第一台虚拟机上新建目录
但是因为配置文件改成第二台虚拟机,所以,第二台上可以看见被修改了。
5.结论
说名上面的操作结论。
现在只是修改第一台机器的core,以及操作第一台机器。
但是在页面上的结果变化需要到core文件中修改的对应的机器上观看datanode的文件变化情况。
说明,第一台机器可以随意操作集群中想要操作的那个datanode。
同理,第二台上可以通过配置core中的namenode所在主机,进行修改对应的datanode。
所以,这样就完成了想要的结果。
每个namenode都可以操作不同的datanode。
四:结论
不管操作的是哪台虚拟机,core中的namenode定义的哪台虚拟机,新建的HDFS就属于哪个namenode管理。