一:准备
1.集群的规划
new01 new02 new03
namenode resourcemanager secondarynamenode
datanode datanode datanode
nodemanager nodemanager nodemanager
historyserver
2.克隆虚拟机
二:修改克隆后的配置
1.修改虚拟机主机名

2.修改ip
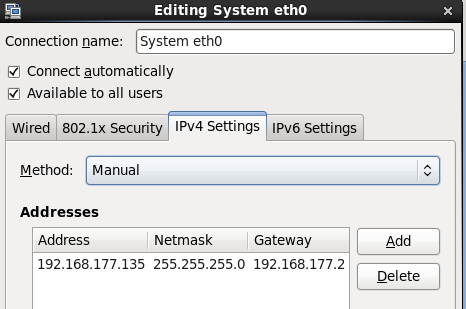
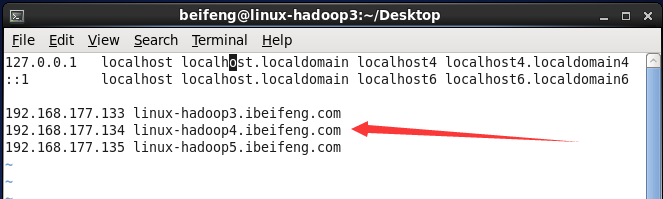
3.修改三台虚拟机的所有的 /etc/hosts和本地hosts

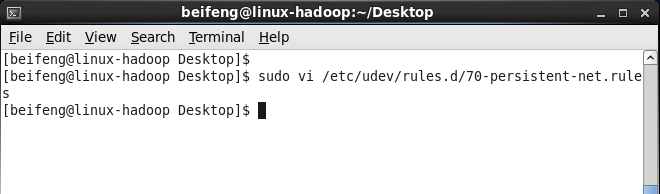
4.修改第二台以及第三台虚拟机的mac



5.重启网络

6.重启
reboot
7.删除tmp临时文件

三:部署集群
8.规划目录,修改所属
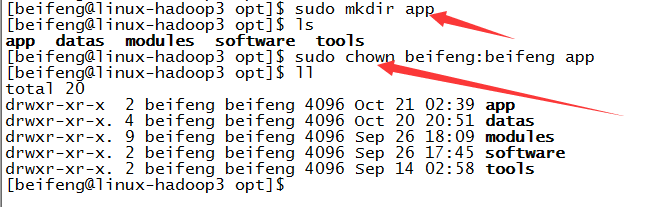
9.解压
10.删除doc

11.新建dfs的目录

12.安装jdk(这一步已经不需要安装)

13.配置env.sh的jdk环境
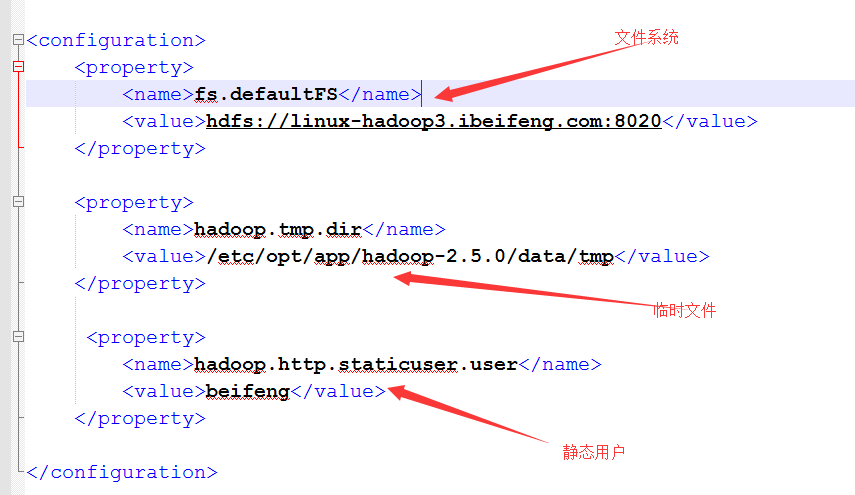
14.配置core-site.xml
15.修改hdfs-site.xml

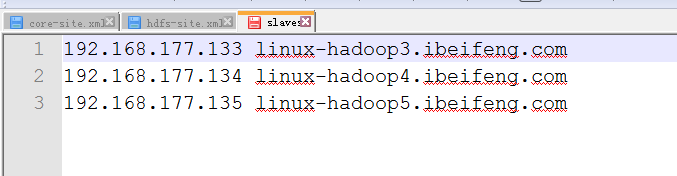
16.配置slaves
17.配置yarn-site.xml

18.配置mapreduce.site.xml
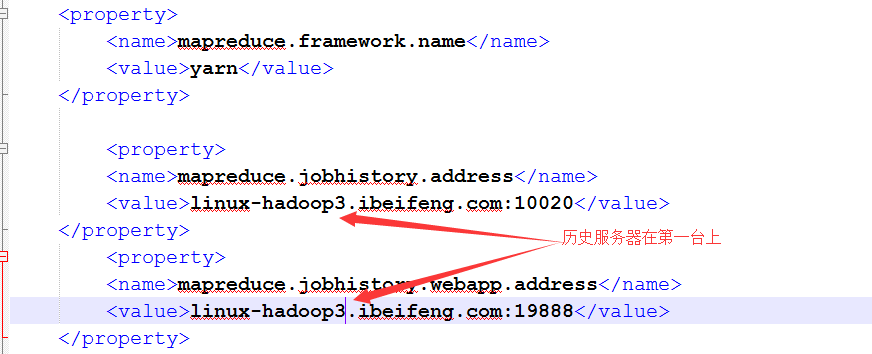
19.在第二台和第三台上规划目录
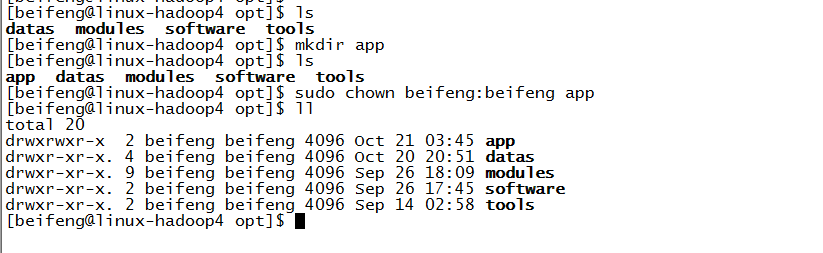
20.将安装包分发到各个节点上

21.格式化
只需要对namenode进行格式化,所以就只需要对第一台虚拟机进行格式化
![]()
22.启动namenode以及datanode

-------------注意点:权限

-------------注意点:权限

23.结果
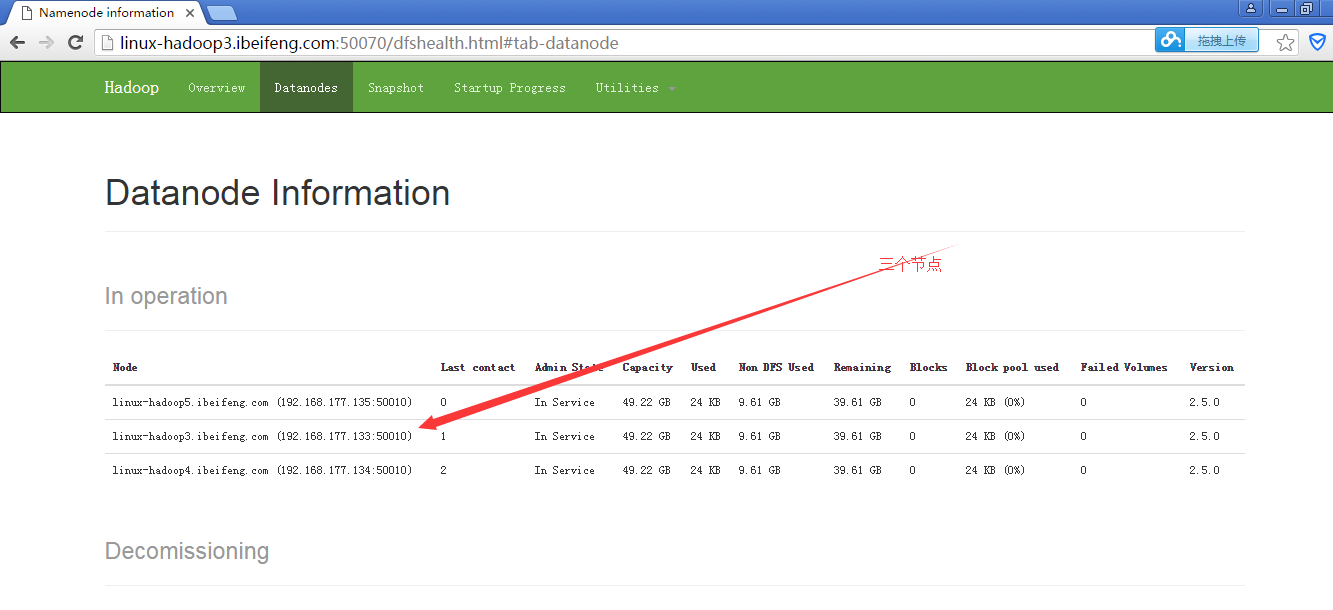
24.启动yarn
下面的出现了错误,暂时不再截图修改了。、
因为,resourcemanager这个服务被部署在第二台虚拟机上,但是这是在第一台虚拟机上也可以启动,但是,很快,jps时,应该不会再看到,
因为,这个时候,resourcemanager会自动闭合。


