一直到今天,才打算写这篇文章。我使用的es服务器,是使用docker进行安装的,不像传统的那种安装,分词器要添加到docker里,一直有些头疼。
es整体都整理好了,进行补充没有实现的一些es知识点。
1.参考地址
github:https://github.com/medcl/elasticsearch-analysis-ik/
码云:https://gitee.com/sky_flying/elasticsearch-analysis-ik?_from=gitee_search
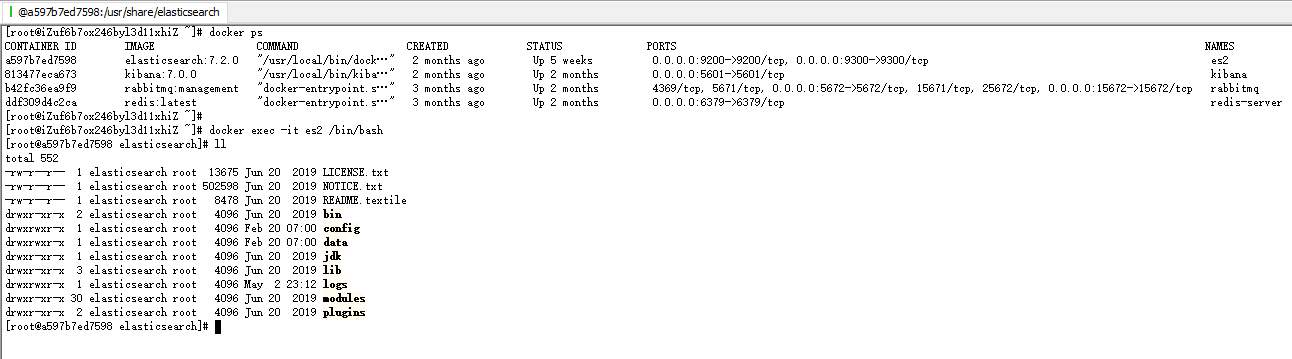
2.首先看自己的es版本

3.进入docker
4.在线安装
版本和es一致
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip
但是,在线就是有些慢,这里有一个可以先下载下来,然后使用的做法:https://blog.csdn.net/u012211603/article/details/90757253
本文终止在线安装,从第5开始线下安装。
5.先进行下载
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip,输入谷歌浏览器中
自动进行下载
下载效果:

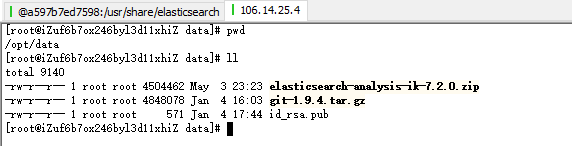
6.从本地上传到服务器
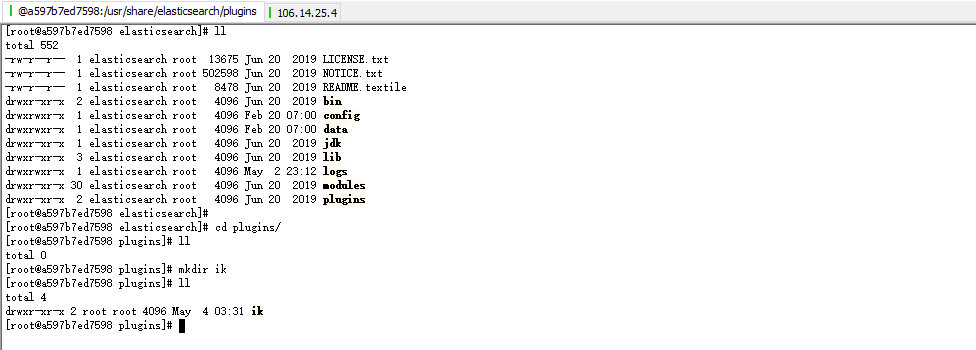
7.新建文件夹
8.退出docker
exit
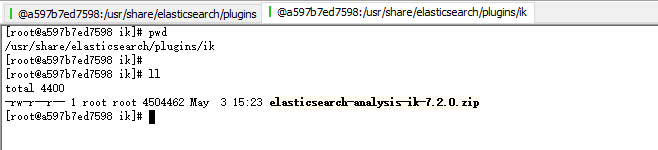
9.将ik拷贝进来
docker cp /opt/data/elasticsearch-analysis-ik-7.2.0 es2:/usr/share/elasticsearch/plugins/ik

效果:
10.解压
如果不存在unzip,则进入容器中执行yum install unzip,就存在了

11.删除zip包

12.退出重新启动
二:验证
1.执行
POST /_analyze
{
"analyzer": "ik_smart",
"text": "我是一个程序员"
}
效果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "一个",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "程序员",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
}
]
}