文字检测可以使用的方法:形态学、MSER、CTPN、SegLink、EAST等。
可以使用的深度学习文本行定位:CTPN、YOLO、EAST、PSE、DB等。
文字检测的目的是为了文字识别。文字检测是文字识别的必经之路。文字检测的场景分为两种,一种是简单场景,另一种是复杂场景。其中,简单场景的文字检测较为简单,例如像书本扫描、屏幕截图、或者清晰度高、规整的照片等;而复杂场景,主要是指自然场景,情况比较复杂,例如像街边的广告牌、产品包装盒、设备上的说明、商标等等,存在着背景复杂、光线忽明忽暗、角度倾斜、扭曲变形、清晰度不足等各种情况,文字检测的难度更大。
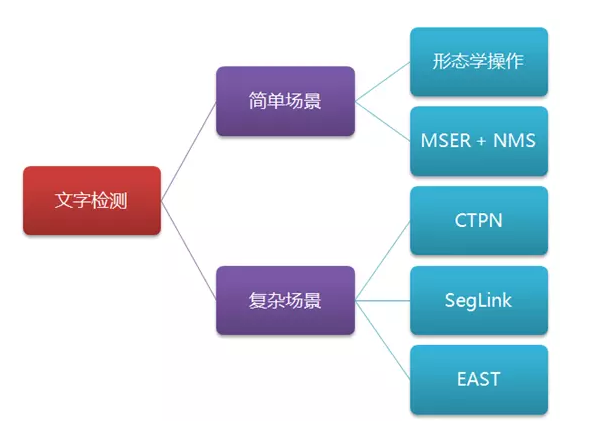
1、形态学操作
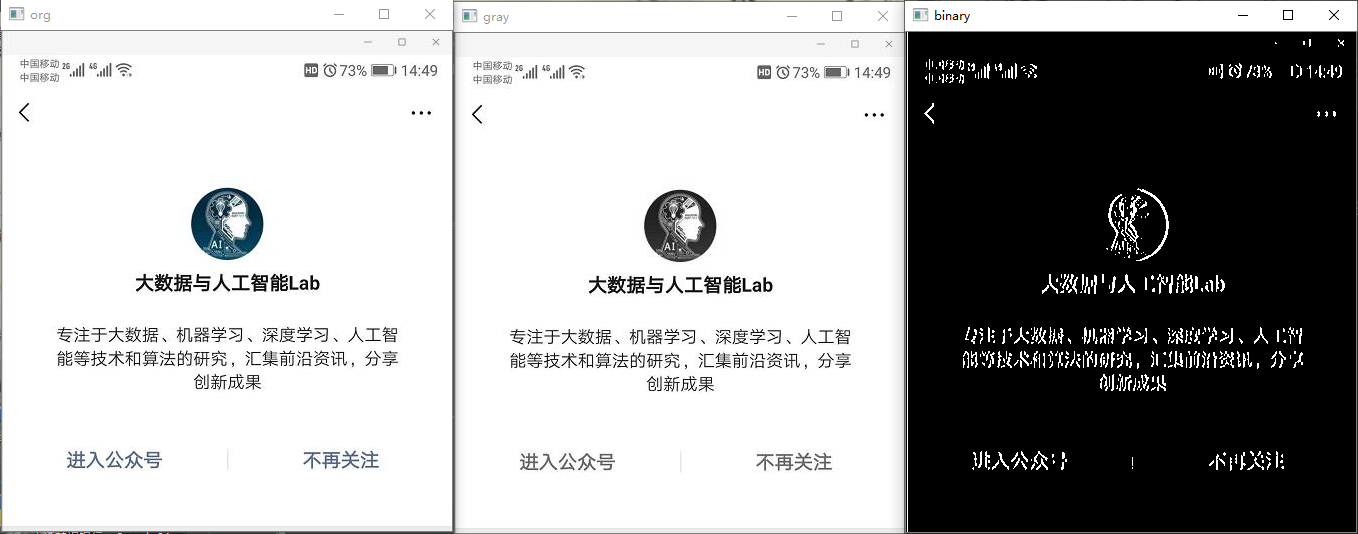
1 # -*- coding: utf-8 -*- 2 3 import cv2 4 import numpy as np 5 6 # 读取图片 7 imagePath = 'D:/documents/pycharm/text_line_detect/test.jpg' 8 img = cv2.imread(imagePath) 9 cv2.imshow('org', img) 10 # 转化成灰度图 11 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) 12 13 cv2.imshow('gray', gray) 14 # cv2.waitKey(0) 15 # 利用Sobel边缘检测生成二值图 16 sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize=3) 17 # 二值化 18 ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY) 19 cv2.imshow('binary', binary) 20 # 膨胀、腐蚀 21 element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 9)) 22 element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (24, 6)) 23 24 # 膨胀一次,让轮廓突出 25 dilation = cv2.dilate(binary, element2, iterations=1) 26 cv2.imshow('dilation', dilation) 27 # 腐蚀一次,去掉细节 28 erosion = cv2.erode(dilation, element1, iterations=1) 29 cv2.imshow('erosion', erosion) 30 # 再次膨胀,让轮廓明显一些 31 # dilation2 = cv2.dilate(erosion, element2, iterations=2) 32 # cv2.imshow('dilation2', dilation2) 33 # 查找轮廓和筛选文字区域 34 region = [] 35 contours, hierarchy = cv2.findContours(erosion, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) 36 for i in range(len(contours)): 37 cnt = contours[i] 38 39 # 计算轮廓面积,并筛选掉面积小的 40 area = cv2.contourArea(cnt) 41 if (area < 600): 42 continue 43 44 # 找到最小的矩形 45 rect = cv2.minAreaRect(cnt) 46 print ("rect is: ") 47 print (rect) 48 49 # box是四个点的坐标 50 box = cv2.boxPoints(rect) 51 box = np.int0(box) 52 53 # 计算高和宽 54 height = abs(box[0][1] - box[2][1]) 55 width = abs(box[0][0] - box[2][0]) 56 57 # 根据文字特征,筛选那些太细的矩形,留下扁的 58 if (height > width * 1.3): 59 continue 60 61 region.append(box) 62 63 # 绘制轮廓 64 for box in region: 65 cv2.drawContours(img, [box], 0, (0, 255, 0), 2) 66 67 cv2.imshow('img', img) 68 cv2.waitKey(0) 69 cv2.destroyAllWindows()
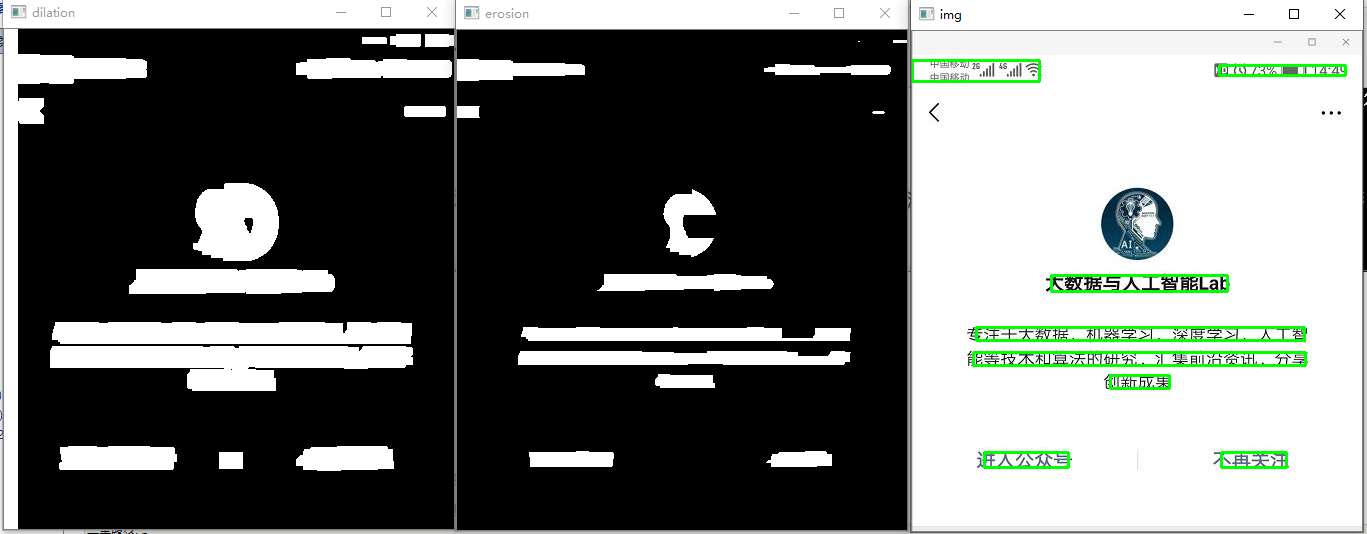
文本框坐标:
rect is: ((341.5, 428.5), (65.0, 15.0), 0.0) rect is: ((114.0, 428.5), (84.0, 15.0), -0.0) rect is: ((227.5, 350.5), (59.0, 13.0), -0.0) rect is: ((227.0, 327.5), (332.0, 13.0), -0.0) rect is: ((228.49996948242188, 303.4999694824219), (328.99993896484375, 12.999998092651367), 0.0) rect is: ((227.99996948242188, 252.0), (175.99996948242188, 15.999998092651367), 0.0) rect is: ((231.27243041992188, 192.2310333251953), (66.85161590576172, 51.90342712402344), -85.2363510131836) rect is: ((370.0, 39.0), (126.0, 10.0), -0.0) rect is: ((63.5, 39.5), (21.0, 127.0), -90.0)
优缺点:这种方法的特点是计算简单、处理起来非常快,但在文字检测中的应用场景非常有限,例如如果图片是拍照的,光线有明有暗或者角度有倾斜、纸张变形等,则该方法需要不断重新调整才能检测,而且效果也不会很好。
2、简单场景:MSER+NMS检测法
MSER(Maximally Stable Extremal Regions,最大稳定极值区域)是一个较为流行的文字检测传统方法(相对于基于深度学习的AI文字检测而言),在传统OCR中应用较广,在某些场景下,又快又准。
MSER算法是在2002提出来的,主要是基于分水岭的思想进行检测。分水岭算法思想来源于地形学,将图像当作自然地貌,图像中每一个像素的灰度值表示该点的海拔高度,每一个局部极小值及区域称为集水盆地,两个集水盆地之间的边界则为分水岭。
MSER的处理过程是这样的,对一幅灰度图像取不同的阈值进行二值化处理,阈值从0至255递增,这个递增的过程就好比是一片土地上的水面不断上升,随着水位的不断上升,一些较低的区域就会逐渐被淹没,从天空鸟瞰,大地变为陆地、水域两部分,并且水域部分在不断扩大。在这个“漫水”的过程中,图像中的某些连通区域变化很小,甚至没有变化,则该区域就被称为最大稳定极值区域。在一幅有文字的图像上,文字区域由于颜色(灰度值)是一致的,因此在水平面(阈值)持续增长的过程中,一开始不会被“淹没”,直到阈值增加到文字本身的灰度值时才会被“淹没”。该算法可以用来粗略地定位出图像中的文字区域位置。
# -*- coding: utf-8 -*- import cv2 # 读取图片 imagePath = 'D:/documents/pycharm/text_line_detect/test111.jpg' img = cv2.imread(imagePath) cv2.imshow('org', img) # 灰度化 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) vis = img.copy() orig = img.copy() cv2.imshow('gray', gray) # 调用 MSER 算法 mser = cv2.MSER_create() regions, _ = mser.detectRegions(gray) # 获取文本区域 hulls = [cv2.convexHull(p.reshape(-1, 1, 2)) for p in regions] # 绘制文本区域 cv2.polylines(img, hulls, 1, (0, 255, 0)) cv2.imshow('img', img) # cv2.waitKey(0) # 将不规则检测框处理成矩形框 keep = [] for c in hulls: x, y, w, h = cv2.boundingRect(c) keep.append([x, y, x + w, y + h]) cv2.rectangle(vis, (x, y), (x + w, y + h), (255, 255, 0), 1) cv2.imshow("hulls", vis) cv2.waitKey(0)
检测效果如下图:

检测后的结果是存在各种不规则的检测框形状,通过对这些框的坐标作重新处理,变成一个个的矩形框。如下图:

从上图可以看出,检测框有很多是重叠的,大框里面有小框,框与框之间有交叉,有些框只是圈出了汉字的偏旁或者某些笔划,而我们期望是能圈出文字的外边框,这样便于后续的文字识别。为了处理这些很多重叠的大小框,一般会采用NMS方法(Non Maximum Suppression,非极大值抑制),也就是抑制非极大值的元素,即抑制不是最大尺寸的框,相当于去除大框中包含的小框,达到去除重复区域,找到最佳检测位置的目的。
NMS算法的主要流程如下:
- 将所有框按置信度得分进行排序(如果边框没有置信度得分,也可以按坐标进行排序)
- 取其中得分最高的框出来
- 遍历该框与其余框的重叠面积(IoU)
- 删除IoU大于某个阈值的框(阈值可按需设定,例如0.3、0.5、0.8等)
- 取下一个得分最高的框出来,重复以上过程
经过以上步骤,最后剩下的就是不包含重叠部分的文本检测框了。核心代码如下:
接下来要介绍的方法,就主要是基于深度学习的AI文字检测法,可应用于复杂的自然场景中。
3、复杂场景:CTPN检测法
CTPN(Detecting Text in Natural Image with Connectionist Text Proposal Network,基于连接预选框网络的文本检测)是基于卷积神经网络和循环神经网络的文本检测方法,其基本做法是生成一系列适当尺寸的文本proposals(预选框)进行文本行的检测,示意图如下,具体的技术原理请见之前的文章(文章:大话文本检测经典模型:CTPN)
参考博客:https://www.csdn.net/gather_25/MtTaggxsNjU4OS1ibG9n.html