https://blog.csdn.net/u011511601/article/details/72843247
MeanShift图像分割算法:大概是将复杂的背景,通过粗化提取整体信息,进而将图像分割。
接下来我想,将会抽出一部分时间,研究一下这个算法,以最终实现手势形状提取。
《Mean Shift: A Robust Approach Toward Feature Space Aalysis》一文中,利用Meanshift算法分割图像,大体类似于这样的效果:

mean shift 图像分割(三),讲的比较详细。
先转发内容如下:
Reference:
[1] Mean shift: A robust approach toward feature space analysis, PAMI, 2002
[2] mean shift,非常好的ppt ,百度文库链接
[3] Pattern Recognition and Machine Learning, Bishop, 2006,Sec 2.5
[4] Computer Vision Algorithms and Applications, Richard Szeliski, 2010, Sec 5.3
[5] Kernel smoothing,MP Wand, MC Jones ,1994, Chapter 4
写在前头的话:这篇笔记看起来公式巨多,实际上只是符号表示,没啥公式推导,不过,多了就难免有差错,欢迎指正。
Mean shitf的故事说来挺励的,早在1975年就诞生了,接着就是漫长的黑暗岁月,黑暗到几乎淡出了人们的视野,不过,命运总是善良的,95年又重新焕发生机,各种应用喷薄而出,包括目标跟踪,边缘检测,非极大值抑制等。这次就只介绍在图像分割中的应用吧,其它的我也没看。Mean shitf过程也充满正能量,描绘的是如何通过自己的努力,一步一步爬上顶峰的故事。
1 总体思想
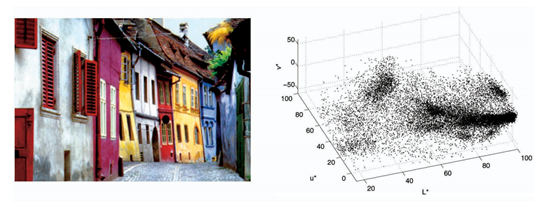
图 1 特征空间映射:RGB图片 -> L-u特征空间
首先meanshift是一种特征空间分析方法,要利用此方法来解决特定问题,需要将该问题映射到特征空间。对于图像分割,我们可以映射到颜色特征空间,比如将RGB图片,映射到Luv特征空间,图1是L-u二维可视化的效果。
图像分割就是求每一个像素点的类标号。类标号取决于它在特征空间所属的cluster。对于每一个cluster,首先得有个类中心,它深深地吸引着一些点,就形成了一个类,即类中心对类中的点构成一个basin of attraction ,好比咱们的太阳系。如此,图像分割问题,就可以看成对每个像素点,找它的类中心问题,因为找到类中心就知道它是属于那一类啦,即类中心一样的点就是一类。

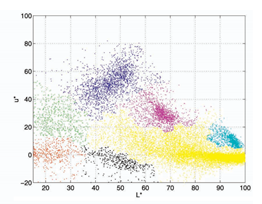
图2标准化后的概率密度可视化效果 -> 聚类分割结果
密度估计的思路需要解决两个问题,what:中心是什么?how:怎么找?mean shift认为中心是概率密度(probalility density function )的极大值点,如图2中的红色点,原文称之为mode,我这暂且用模点吧(某篇论文是如此称呼)。对于每个点怎样找到它的类中心呢?只要沿着梯度方向一步一步慢慢爬,就总能爬到极值点,图2中黑色的线,就是爬坡的轨迹。这种迭代搜索的策略在最优化中称之为 multiple restart gradient descent。不过,一般的gradient descent并不能保证收敛到局部极值,但mean shift 可以做到,因为它的步长是自适应调整的,越靠近极值点步长越小。
也就是说meanshift的核心就两点,密度估计(Density Estimation) 和mode 搜索。对于图像数据,其分布无固定模式可循,所以密度估计必须用非参数估计,选用的是具有平滑效果的核密度估计(Kernel density estimation,KDE)。
2 算法步骤

截取这一块可视化
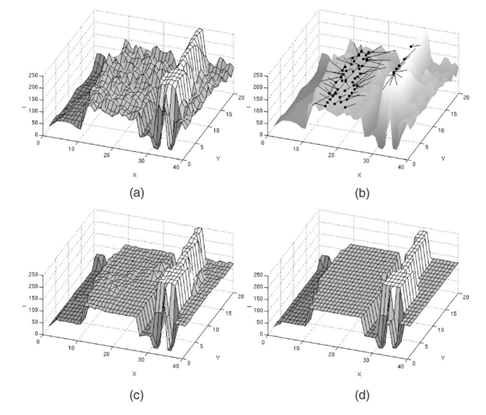
(a)灰度图可视化à(b)mean shift模点路径à(c)滤波后效果à(d)分割结果
分三步走:模点搜索/图像平滑、模点聚类/合并相似区域、兼并小区域(可选)。模点搜索是为了找到每个数据点的到类中心,以中心的颜色代替自己的颜色,从而平滑图像。但模点搜索得到的模点太多,并且很多模点挨得很近,若果将每个模点都作为一类的话,类别太多,容易产生过分割,即分割太细,所以要合并掉一些模点,也就是合并相似区域。模点聚类后所得到的分割区域中,有些区域所包含的像素点太少,这些小区域也不是我们想要的,需要再次合并。
2.1 模点搜索/图像平滑
建议先看[2]中的演示(P4-12)
图像中的点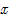 包括两类信息:坐标空间(spatial,
包括两类信息:坐标空间(spatial,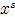 ,
,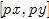 ),颜色空间(range ,
),颜色空间(range ,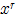 ,
,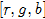 )。这些就构成了特征空间。
)。这些就构成了特征空间。
模点搜索(OpenCV):某一个点 ,它在联合特征空间
,它在联合特征空间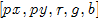 中迭代搜索它的mode/模点
中迭代搜索它的mode/模点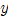 ;
;
图像平滑: 将模点的颜色值赋给它自己,即 .对应原文中的图像平滑,实质上是通过模点搜索,达到图像平滑的效果, 所以我合并为以一步。
.对应原文中的图像平滑,实质上是通过模点搜索,达到图像平滑的效果, 所以我合并为以一步。
设点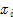 依次爬过的脚印为:
依次爬过的脚印为:
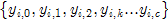
出发时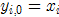 ,它所收敛到的模点为
,它所收敛到的模点为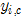 ,c代表convergence。
,c代表convergence。
第一步:如果迭代次数超过最大值(默认最多爬5次),结束搜索跳到第四步,否则,在坐标空间,筛选靠近 的数据点进入下一步计算。
的数据点进入下一步计算。
OpenCV是以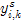 的坐标
的坐标 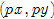 为中心,边长为
为中心,边长为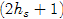 的方形区域
的方形区域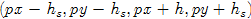 内的数据点。
内的数据点。
其实,本应用 为中心,
为中心,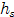 为半径的圆形区域,那样效果更好,但是循环计算时并不方便,所以用方形区域近似。
为半径的圆形区域,那样效果更好,但是循环计算时并不方便,所以用方形区域近似。
第二步:使用第一步幸存下来的点计算重心,并向重心移动。
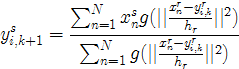
写得有点复杂了,下面解释下。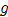 是某种核函数,比如高斯分布,
是某种核函数,比如高斯分布,  是颜色空间的核平滑尺度。OpenCV使用的是最简单的均匀分布:
是颜色空间的核平滑尺度。OpenCV使用的是最简单的均匀分布:

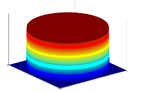
二维可视化效果
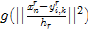 是一个以
是一个以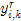 (第
(第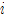 步位置的颜色值)为球心,半径为
步位置的颜色值)为球心,半径为 的球体,球体内部值为1,球体外部值为0。对于经过上一步筛选后幸存的数据点
的球体,球体内部值为1,球体外部值为0。对于经过上一步筛选后幸存的数据点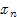 ,如果其颜色值
,如果其颜色值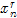 满足
满足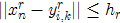 ,也就是颜色值落也在球内,那么求重心
,也就是颜色值落也在球内,那么求重心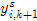 时,就要算上
时,就要算上 ,否则落在球外,算重心时,就不带上它。实际上,上一步是依据坐标空间距离筛选数据点,
,否则落在球外,算重心时,就不带上它。实际上,上一步是依据坐标空间距离筛选数据点,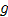 是依据颜色距离进一步筛选数据点,上一步的筛子是矩形,这一步是球体。
是依据颜色距离进一步筛选数据点,上一步的筛子是矩形,这一步是球体。
简而言之,设满足 的点依次为
的点依次为 ,那么重心计算公式可以进一步化简为:
,那么重心计算公式可以进一步化简为:
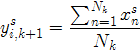
是不是很简单呢,初中知识吧。
注意:上文中的两个参数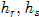 ,是Mean shift最核心的两个参数(还有一个可选的M),具有直观的意义,分别代表坐标空间和颜色空间的核函数带宽。
,是Mean shift最核心的两个参数(还有一个可选的M),具有直观的意义,分别代表坐标空间和颜色空间的核函数带宽。
第三步:判断是否到模点了,到了就停止。
如果,移动后颜色或者位置变化很小,则结束搜索,跳到第四步,否则重返第一步,从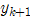 继续爬。
继续爬。
OpenCV停止搜索的条件:
(1)坐标距离不变
(2)颜色变化值很小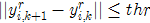 。
。
满足一条就可以功成身退,否则继续努力。
第四步:将模点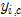 的颜色
的颜色 赋给出发点
赋给出发点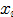 /
/ ,即
,即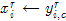 。
。
注意:原文这一步,不仅将模点的颜色值赋给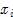 ,顺带把坐标值也赋给了
,顺带把坐标值也赋给了 ,也就是说
,也就是说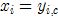 。
。
2.2 合并相似区域/模点聚类
合并上一步平滑后的图像。OpenCV采用flood fill函数实现,原理很简单,看下wiki的动画就知道了,模拟洪水浸满峡谷的效果。基本上就是区域生长,从某一点出发,如果和它附近的点(4/8邻域)的颜色值相似就合并,同时再从新合并的点出发继续合并下去,直到碰到不相似的点或者该点已经属于另一类了,此时,就退回来,直到退无可退(所有的4/8邻域搜索空间都已经搜索完毕)。
虽然很简单,但是不同的方法还是有很多需要注意的细节问题。这里假设滤波后的图像用 表示。
表示。
滤波后的两个像素点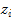 和
和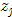 ,是否合并,可以使用颜色相似度和空间位置相似性判定。
,是否合并,可以使用颜色相似度和空间位置相似性判定。
OpenCV只考虑颜色相似性,而忽略模点的坐标是否相似。而原算法综合了二者的信息。如果像素点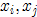 ,满足
,满足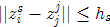 或者
或者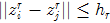 , 则这两个像素点就合并。不过OpenCV也是有考虑坐标位置的,它是只考虑原空间的4/8邻域,而原文是考虑特征空间模点的
, 则这两个像素点就合并。不过OpenCV也是有考虑坐标位置的,它是只考虑原空间的4/8邻域,而原文是考虑特征空间模点的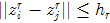 ,相当于说OpenCV的
,相当于说OpenCV的 (原空间)。
(原空间)。
此外,floodfill有一个特点,它不能越过已经被分类的区域,再加上没有第三步,使得OpenCV的结果,真的是惨不忍睹。原文的合并算法,具体怎么合并的还得看源代码。不过,应该不是用flood fill。
《Computer Vision A Modern Approach》中是使用类平均距离判定是否合并。比如, ,
,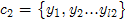 能否合并成
能否合并成 ,取决于类平均距离:
,取决于类平均距离:
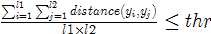
这样做我觉得效果会更好,因为它不是单独依据边界上的两个点来判定是否合并,它是依据两个区域内部所有的点的信息综合判断。所以,它能合并两个区域,而原算法和OpenCV只能是两个点合并成一个区域,该区域又不断地合并点,一旦一个区域已经完成生长,那么它就不会和别的区域合并了。可以反证。假设先形成 ,区域
,区域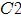 生长的时候把
生长的时候把 给合并了,那么必定有两个点满足相似关系,连接了二者,假设这两个点为
给合并了,那么必定有两个点满足相似关系,连接了二者,假设这两个点为 ,
,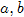 相似,那么
相似,那么 生长的时候就肯定已经把
生长的时候就肯定已经把 点合并进来了,接着把
点合并进来了,接着把 所拥有的区域全盘接收,根本不会让
所拥有的区域全盘接收,根本不会让 区域自成一类。
区域自成一类。
当然考虑Outlier,使用中值更好。
假设合并之后得到m类 。对于原文的算法,每个像素点
。对于原文的算法,每个像素点 的标号
的标号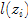 就是其模点
就是其模点 所属的模点集合的类标号,比如
所属的模点集合的类标号,比如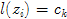 。不过,OpenCV是
。不过,OpenCV是 所属集合的类标号。
所属集合的类标号。
不过,从原文结果来看,得到的结果并不是类标号,因为类标号一般都是序号,比如1,2,……,然后显示分割结果的时候,就给每一类随机分配一种独有的颜色。但原文的分割结果貌似是这一类的总体颜色值,我猜测原算法可能是用(加权)求平均的方式得到类的颜色值,然后属于这一类的像素点就用这个颜色代替。
注意:这一步实现的是合并相似区域,但本质上还是而是合并模点,或者说模点聚类,因为每个像素点的值,就是它所属模点的颜色值 /模点的联合信息
/模点的联合信息 。
。
2.3 兼并小区域

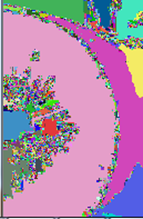
OpenCV的分割结果
上一步合并了一些模点,但是,对于一些小区域,如果它和周围的颜色差异特别大,那么它们也会自成一类,这些小家伙让需要进一步合并。不过,OpenCV的实现中,并没有包含这一步,所以分割出的结果中包含了太多芝麻大点的区域,本人很不满意,有时间再加进去,还得优化下代码,这个实现实在是太慢了。怎么兼并小的区域呢?原文没说,我也没看他的源代码,我们可以直接将包含像素点少于 的区域与它最相似的区域合并,实际中,小区域往往是被大区域兼并了。
的区域与它最相似的区域合并,实际中,小区域往往是被大区域兼并了。
3 算法原理
3.1 密度估计
关于密度估计,这里直接使用结论,具体原理,参见第5部分:非参数密度估计。
某一点的密度估计值:

 为核函数,一般我们会使用径向对称(radially symmetric)核函数。即:
为核函数,一般我们会使用径向对称(radially symmetric)核函数。即:

其中 为标准化常数,使得
为标准化常数,使得

 称为
称为 的profile,原文介绍了两种
的profile,原文介绍了两种 ,对应两种核,这里再补充一种。
,对应两种核,这里再补充一种。
(1)Epanechnikov Kernel
它的profile如下:



可视化效果
(2)Normal Kernel
它的profile如下:



可视化效果
(3)Uniform Kernel
它的profile如下:



可视化效果
3.2密度梯度估计
3.2.1 梯度方向
 处的密度估计:
处的密度估计:

则密度梯度估计:

令 ,即这一部分又可以看成是一个核密度估计。
,即这一部分又可以看成是一个核密度估计。
物理意义:梯度方向是各个数据点的方向向量的加权求平均,即上式可以看成


蓝色圈圈—>到黄色圈圈
例如,我们使用的是Normal Kernel,则


想象一下几十匹马同时拉一辆车的恢宏场面,每匹马 都往自己的方向
都往自己的方向 拉,不过,距离越
拉,不过,距离越 近的马,其力量
近的马,其力量 越大,初中物理告诉我们,结果是合力的方向,如上图的黄色箭头。
越大,初中物理告诉我们,结果是合力的方向,如上图的黄色箭头。
注意:Epanechnikov Kernel求导后实质上就是Uniform Kernel。
3.2.2 漫漫爬坡路
虽然,往哪个方向移动知道了,但是移动的步长并不好确定,下面转化一下形式,可以得到自适应步长:

看起来有点复杂,实际上只是简单的替换。其中 类比
类比 ,
,  类比
类比

中间项的物理意义: 处的核
处的核 的密度估计,
的密度估计, 是
是 求导所得,如果
求导所得,如果 用Normal Kernel,则
用Normal Kernel,则 的形式和
的形式和 相同。
相同。
中间项只是一个数,而最后一项 就是所谓的mean shift向量,是一个方向向量,对应的就是我们的梯度方向。
就是所谓的mean shift向量,是一个方向向量,对应的就是我们的梯度方向。
对于某一点 往梯度方向移动到
往梯度方向移动到 ,则新坐标:
,则新坐标:

物理意义:很直观,以 为权值计算重心。
为权值计算重心。
当 时,我们就到达了模点,由于
时,我们就到达了模点,由于 ,所以只能是
,所以只能是 。不过想要一步登天,很难,除非你出生很好,就落在模点,大多数数据点,还是得老老实实,一步一个脚印爬上去。还是设
。不过想要一步登天,很难,除非你出生很好,就落在模点,大多数数据点,还是得老老实实,一步一个脚印爬上去。还是设 爬过的脚印依次
爬过的脚印依次 ,
, ,则脚印公式:
,则脚印公式:

3.3.3 自适应步长

可以看出步长 与
与 成反比,还是以Normal Kernel为例,越靠近模点,步长越小,反之越大。
成反比,还是以Normal Kernel为例,越靠近模点,步长越小,反之越大。
原文证明了,只要 是凸函数,
是凸函数, 单调递减(
单调递减( 可以不是哦),那么就能保证它总能收敛到模点,并且
可以不是哦),那么就能保证它总能收敛到模点,并且 是单调递增的(我没看……)。只要步履不停,我们总会遇见,多么美好的世界啊,求遇见。
是单调递增的(我没看……)。只要步履不停,我们总会遇见,多么美好的世界啊,求遇见。
3.3 图像分割领域的具体化
本质上,mean shift解决任何问题,都是转化成密度估计问题。但具体问题还得具体分析。对于图像它有两种信息,坐标和颜色,前者为spatial 空间 后者为range空间,对于单通道图片即灰度值,对于彩色图片即
后者为range空间,对于单通道图片即灰度值,对于彩色图片即 或者效果更好的
或者效果更好的 等。二者是截然不同的属性,决定了不能等同视之。因此,我们使用多元核密度估计(multivariate kernel)。设spatial有2维,range空间,设为
等。二者是截然不同的属性,决定了不能等同视之。因此,我们使用多元核密度估计(multivariate kernel)。设spatial有2维,range空间,设为 维。
维。
一元核:


即
图像分割中使用的多元核:




滤波的结果
物理意义: 分别为坐标空间核和颜色空间核的带宽(bandwidth)/尺度,我说不清,看结果吧。
分别为坐标空间核和颜色空间核的带宽(bandwidth)/尺度,我说不清,看结果吧。
3.4回首OpenCV实现
第二步,重心计算公式

我们是对以 为中心
为中心 为边长的区域求重心,其实本应该是:
为边长的区域求重心,其实本应该是:

 用的是Uniform Kernel,也就是说
用的是Uniform Kernel,也就是说 用的是Epanechnikov Kernel
用的是Epanechnikov Kernel

此时,距离筛选是由核函数实现的,因此我们是对图像中所有的数据点 计算重心,而不是落在
计算重心,而不是落在 为中心,
为中心, 为边长的区域内的点求重心。
为边长的区域内的点求重心。
OpenCV的实现中,  并不是圆形的,为了循环时程序实现的方便,就用方形近似,但
并不是圆形的,为了循环时程序实现的方便,就用方形近似,但 是严格的球体。
是严格的球体。
不过方形的也可以写成核函数形式:


此外,Normal Kernel 的平滑效果固然好,但是计算量大,所以主要还是用Uniform Kernel。原文说大部分场合,Uniform Kernel和Normal Kernel就能取得很好的效果。
4延伸
不写了,已经写得太多了……这次就只挖个坑,日后再跳
Camshift
能够自动调整窗口的大小,能适应目标尺度变化的情况,比如人脸跟踪时,人与摄像头的距离动态变化的情况。
带宽选择
图像分割的带宽一般是自己调整看效果,最优带宽也能也求出来?不过,我倒想看看自适应带宽。最优带宽值看原文吧。
Mode prune

对于鞍点等会产生一些虚假的模点,如上图,红色线上的点可能就跑到鞍点去了,去除办法:将模点的坐标稍作移动,再从移动后的位置继续爬,如果还能爬到原来模点的位置,那就保留,否则踢掉。恩,是你的跑不了,不是你的撒手就跑。
与双边滤波的关联
可以看做死板的mean shift 参见[4]的5.2.1
与分水岭分割
逆过程,从山峰开始找山谷,参见[4]的Sec5.2.1
补充阅读
图像分割加速:原文提到了一种加速方法,先随机选取一部分点作为先头部队,让它们去找模点,找的过程中就会开辟出很多到模点的道路,然后呢,让其余的点插到离它最近的路走过去就好了。此外,还有层级分割的方法,OpenCV的实现应该就是其中一种实现。
A topological approach to hierarchical segmentation using mean shift. CVPR 2007
目标跟踪:Kernel-Based Object Tracking, PAMI 03

5 非参数密度估计
这一部分说明为什么 处的密度估计
处的密度估计 :
:

其实,我觉得看bishop的那本书[2]就可以了,行云流水,精彩绝伦,其实,这本书的大部分内容都是如此精彩。我是按自己的理解写的,有些地方有改动,也会有错误,望各位看官指正。
如果产生数据的分布形式已知,参数也已知,那么概率密度函数PDF已知,可以直接计算每一点的概率密度,比如高斯分布。如果参数不知道,那么也可以用数据估计参数,比如最小二乘估计,最大似然估计,贝叶斯参数估计等,如果连产生数据的分布形式都不知道,怎么办求概率密度呢?这就是一个非参数问题了,方法:让数据说话。
5.1 猜一下

对于上图中2维的情况,要估计蓝色圆域的概率密度,我相信大多数人都能凭直觉想到一种方法,那就用蓝色圈圈内的数据点个数 ,除以总的数据点个数
,除以总的数据点个数 ,即
,即 。如果圆圈足够小,那么蓝色圈圈内部的概率密度就可以看成近似相等,那么蓝色点的概率密度应该是
。如果圆圈足够小,那么蓝色圈圈内部的概率密度就可以看成近似相等,那么蓝色点的概率密度应该是 ,
, 是蓝色圈圈的面积。当然,也可以推广到
是蓝色圈圈的面积。当然,也可以推广到 维空间。这种算法,虽然直观,但缺乏理论支撑,下面证明,大伙的确猜对了。
维空间。这种算法,虽然直观,但缺乏理论支撑,下面证明,大伙的确猜对了。
5.2理论推导
首先说下,为什么 可以用
可以用 估计。
估计。
设 是一个
是一个 维的数据,密度函数为
维的数据,密度函数为 ,则
,则 空间中的一个区域
空间中的一个区域 的概率密度
的概率密度 ,即数据点落在区域
,即数据点落在区域 的概率:
的概率:

现在假设,依据某种未知概率分布得到了N个数据点(非参数并不是无法参数化,理论上任何分布都可以参数化,毕达哥拉斯说"万物皆数",只是参数无限维,只能当做非参数处理),则落在 中的点的个数可能是
中的点的个数可能是 ,是否落在区域
,是否落在区域 中就是一个二项分布:
中就是一个二项分布:

二项分布的期望:


二项分布的方差:


当 时,
时, ,从参数估计角度说,前者说明
,从参数估计角度说,前者说明 是
是 的无偏估计,后者说明
的无偏估计,后者说明 是
是 的一致估计。总之,说明
的一致估计。总之,说明 ,是一个很好的估计量。
,是一个很好的估计量。
因此,

进一步假设, 比较小,那么
比较小,那么 内的
内的 可近似相等,于是:
可近似相等,于是:

 为
为 的体积
的体积

注意: 是有偏估计,下面再说。
是有偏估计,下面再说。
由此推出,估计 ,有两种方法,第一种是固定
,有两种方法,第一种是固定 看
看 的数目,这就是kernel估计的本质(个人认为,直方图估计,Parzen windows 也是)。另外一种方法是固定
的数目,这就是kernel估计的本质(个人认为,直方图估计,Parzen windows 也是)。另外一种方法是固定 看包含
看包含 个数据点所需要的体积,这就是K最近邻估计。
个数据点所需要的体积,这就是K最近邻估计。
5.3直方图密度估计

将数据范围划分为若干个宽度为 的小栅格(bin)(也可以不等长哦),然后统计落在每个区间内的数据点个数
的小栅格(bin)(也可以不等长哦),然后统计落在每个区间内的数据点个数 ,那么,每个区间的密度
,那么,每个区间的密度 ,
, 为整个数据范围内的数据点个数。
为整个数据范围内的数据点个数。
这个方法有很多缺陷:
(1)第一个bin起始位置的选择会影响到结果(与bin的个数无关)
(2)估计出来的概率密度有好多毛刺,不是连续光滑的曲线。
(3)适合一两维的情况。 维是需要的bin个数为
维是需要的bin个数为 (假设每一维都需要划分成
(假设每一维都需要划分成 个bin),而且大多数bin的值为0,造成维度灾难(Curse of dimensionality)
个bin),而且大多数bin的值为0,造成维度灾难(Curse of dimensionality)

此外,对 的大小特别敏感,小了,过拟合,不光滑,大了,太光滑,不过这是参数估计的普遍现象,前面提到的
的大小特别敏感,小了,过拟合,不光滑,大了,太光滑,不过这是参数估计的普遍现象,前面提到的 也是如此。
也是如此。
5.4 K近邻密度估计(K-nearest neighbours,KNN)
上面已经提过, ,固定
,固定 ,看需要多大的
,看需要多大的 。
。

这里我们用KNN密度估计+贝叶斯 推导下KNN分类器的原理。至于怎么分类的,很简单,如果不知道的话,哈哈,看我以前写的KNN (Related部分)。

样本 属于哪一类就看它属于哪一类的可能性最大,即:
属于哪一类就看它属于哪一类的可能性最大,即:

 很简单,基本的先验概率转后验概率:
很简单,基本的先验概率转后验概率:

利用上面的结论,则 ,
, ,
,

所以,比较属于哪一类时,很公正,先在训练集中找K个最近的数据点,哪一类人多势众,测试样本就属于哪一类。

3类的情况
5.5 核密度估计(kernel density estimation, KDE)
5.5.1 Parzen windows

 点处的密度估计值
点处的密度估计值 ,
, 为落在以
为落在以 为中心的超球体的数据点个数。这与我们最开始猜测时的思想一致,只不过将超球体,换成超立方体。下面用数学符号形式化表示一下:
为中心的超球体的数据点个数。这与我们最开始猜测时的思想一致,只不过将超球体,换成超立方体。下面用数学符号形式化表示一下:


好了,我们用核函数的形式表示了 ,这里
,这里 ,
, ,
, 为总的样本数。这种方法本质上和直方图方法没有太大的区别,Parzen windows方法是以数据点为中心,而直方图是我们自己固定好的点为中心。因此,它也会有直方图的一些缺点。比如估计的概率密度不是连续,维度灾难。
为总的样本数。这种方法本质上和直方图方法没有太大的区别,Parzen windows方法是以数据点为中心,而直方图是我们自己固定好的点为中心。因此,它也会有直方图的一些缺点。比如估计的概率密度不是连续,维度灾难。
5.5.2 Kernel smoothing
很自然的,如果利用的数据量越大,估计出来的值就会越好,因为,我们综合的信息越多,于是我们使用所有数据点估计。采用所有样本估计的话,自然得要用加权的方法,越靠近估计点的数据点权重越大,反之,越是远离数据点,权重越小。
前面已经介绍过具有这样属性的两种核函数。Epanechnikov Kernel和 Normal Kernel。我们可以直接替换掉,则:

由于这两个核函数都是径向对称(radially symmetric),所以稍作了变化。
一开始,我并不理解为什么可以这么做,因为这样就已经不是窗口内的数据点个数,而是所有数据点都参合进来了,意义已经不一样了。后面我们可以通过求它的期望来进一步说明。
此外,bishop说,这个式子既可以看成,只有一个以 为中心的窗口,也可以看成
为中心的窗口,也可以看成 个以
个以 为中心的窗口,后一种介绍,我一直理解不了,但是,原文都是
为中心的窗口,后一种介绍,我一直理解不了,但是,原文都是 而不是
而不是 ,所以应该是第二种解释,才会这样写,我觉得第一种解释挺好,所以我都换过来了。
,所以应该是第二种解释,才会这样写,我觉得第一种解释挺好,所以我都换过来了。
比如,我们使用高斯核,就有:


注意:在靠近左边/右边的估计值有很大偏差,这是因为数据不对称,所以主要以右边/左边的数据为主,如果是回归就不会参数这种现象了。

下面啰嗦一下上式中的

而 ,所以
,所以 。至于为什么要保证
。至于为什么要保证 ,下面就会知道了。
,下面就会知道了。
现在看看估计值 的期望
的期望

我们先做一次变量替换, 。
。
假设 足够光滑,各阶导数都存在,我们在对
足够光滑,各阶导数都存在,我们在对 在
在 处泰勒展开一下:
处泰勒展开一下:
这里只推导1维的情况, 维太复杂了……
维太复杂了……

注意:无穷小项 直接被我忽略了。
直接被我忽略了。
第一项当然希望等于 ,于是我们就希望
,于是我们就希望 ,得到
,得到 第一个条件。不过,对于模式搜索来说,
第一个条件。不过,对于模式搜索来说, 都可以,只要不影响到我们比较大小就好。
都可以,只要不影响到我们比较大小就好。
第二项,等于0最好,所以我们希望
第三项,不能发散,所以 还得满足第三个条件:
还得满足第三个条件: ,原文还提到一个条件:
,原文还提到一个条件: ,这个条件怎么来的,还没想清楚,很多论文也不提这个条件。
,这个条件怎么来的,还没想清楚,很多论文也不提这个条件。
显然这是一个有偏估计,偏差为 。
。
方差:

因此,要使得期望很小,则 要很小,要使方差很小则
要很小,要使方差很小则 要很大。
要很大。
书上的多维推导过程,复杂,矩阵知识严重不够用。
其中: ,为了简便,我上面都是
,为了简便,我上面都是 (图像分割中,一般也是如此),
(图像分割中,一般也是如此), 用来控制核函数的形状和方向,比如我们可以将高斯核改成椭圆形状。
用来控制核函数的形状和方向,比如我们可以将高斯核改成椭圆形状。
这里岔开一下,扯一扯目标检测。比如我们要检测图像中的椭圆形物体,用两高斯核作差,得到一个DoG(类似于墨西哥草帽),让它和图像卷积。控制它的形状和方向就能使得特定形状和方向的目标的响应值最大(和卷积核越像的区域其滤波响应值越大),从而能得到一张该目标在任何一点出现的概率图。接下来用mean shift 作模点搜索,这应该就是mean shift用于目标检测的基本原理吧,待验证。


记录几个公式:
 ,
, 是方阵
是方阵
 ,是缩写……
,是缩写……

5.5.3直方图估计的kernel 平滑版
参见:《Density Estimation》 Simon J. Sheather, Statistical Science 2004
木有仔细看……
如果假设数据服从正态分布,那么就有最优带宽,还有好多种……
normal reference bandwidth:

oversmoothed bandwidth

 数据的标准差,
数据的标准差,
 :数据的个数,但是我以前看《Fast Object Detection with Entropy-Driven Evaluation》源码,用的是
:数据的个数,但是我以前看《Fast Object Detection with Entropy-Driven Evaluation》源码,用的是 , 它的
, 它的 并不是指实际的数据,它是去掉重复后的数据,但是它论文上还是说
并不是指实际的数据,它是去掉重复后的数据,但是它论文上还是说 就是样本的数目,为什么呢?
就是样本的数目,为什么呢?
这个用得比较多,我截取了这篇论文的部分代码,做了个小实验,……
matlab代码
- <span style="font-size:12px;">close all
- ri=round (randn(500,1)*100+50);
- nb_UniQueD=numel(unique(ri));
- minScore = min(ri(:))-1;
- maxScore = max(ri(:))+1;
- scoreStd = std(ri);
- sigma = 1.44 * scoreStd * nb_UniQueD^(-1/5); % not the number of sample
- sigma = 1.06 * scoreStd * numel(ri)^(-1/5); % not the number of sample
- numBins = min(256,10*nb_UniQueD/2);
- Sp = linspace(minScore, maxScore, numBins+1);% need to add one
- H = histc(ri, Sp);
- % normalize by number of samples
- Hraw = H / sum(H);
- figure, subplot(211);
- bar(Hraw);title('histogram estimation')
- % discretization factor
- discrFactor = (maxScore - minScore) / numBins;
- kerSize = round(5 * sigma / discrFactor);
- if kerSize(1) < 3
- kerSize(1) = 3.0;
- end
- kerSize = double(kerSize);
- % apply parzen window, kernel size such that it gets to 2 sigma
- K = fspecial('gaussian', [kerSize 1], double(sigma/discrFactor) );
- H = conv( Hraw, K, 'same' );
- H = H + 1e-10;
- H = H ./sum(H);
- subplot(212),bar(H);title('after smooth') </span>