http://www.cnblogs.com/denny402/p/5032839.html
OCR (Optical Character Recognition,光学字符识别),我们这个练习就是对OCR英文字母进行识别。得到一张OCR图片后,提取出字符相关的ROI图像,并且大小归一化,整个图像的像素值序列可以直接作为特征。但直接将整个图像作为特征数据维度太高,计算量太大,所以也可以进行一些降维处理,减少输入的数据量。
处理过程一般这样:先对原图像进行裁剪,得到字符的ROI图像,二值化。然后将图像分块,统计每个小块中非0像素的个数,这样就形成了一个较小的矩阵,这矩阵就是新的特征了。opencv为我们提供了一些这样的数据,放在
opencvsourcessamplesdataletter-recognition.data
这个文件里,打开看看:

每一行代表一个样本。第一列大写的字母,就是标注,随后的16列就是该字母的特征向量。这个文件中总共有20000行样本,共分类26类(26个字母)。
我们将这些数据读取出来后,分成两部分,第一部分16000个样本作为训练样本,训练出分类器后,对这16000个训练数据和余下的4000个数据分别进行测试,得到训练精度和测试精度。其中adaboost比较特殊一点,训练和测试样本各为10000.
完整代码为:
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
由于adaboost分类和 ann分类速度非常慢,因此我在main函数里把这两个分类注释掉了,大家有兴趣和时间可以测试一下。
结果:
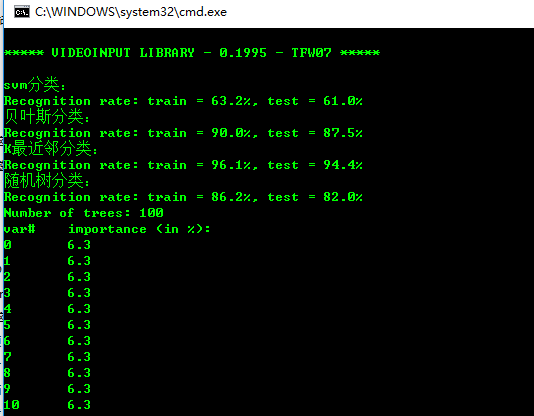
从结果显示来看,测试的四种分类算法中,KNN(最近邻)分类精度是最高的。所以说,对ocr进行识别,还是用knn最好。