1、带参数的宏
关于#define的具体用法:
#define命令是C语言中的一个宏定义命令,它用来将一个宏名替换为一个字符串,该标识符被称为宏名,被定义的字符串称为替换文本。宏定义只做字符替换,不分配内存空间。
该命令有两种格式:一种是简单的宏定义,另一种是带参数的宏定义。
(1)简单的宏定义:
- #define <宏名> <字符串>
- 例: #define PI 3.1415926
- #define <宏名> (<参数表>) <宏体>
- 例: #define swap(a,b)(int c;c=a;a=b;b=c;)
2、二重指针和指针引用
问题抛出:
在函数的使用过程中,我们都明白传值和传引用会使实参的值发生改变。那么能够通过传指针改变指针所指向的地址吗?
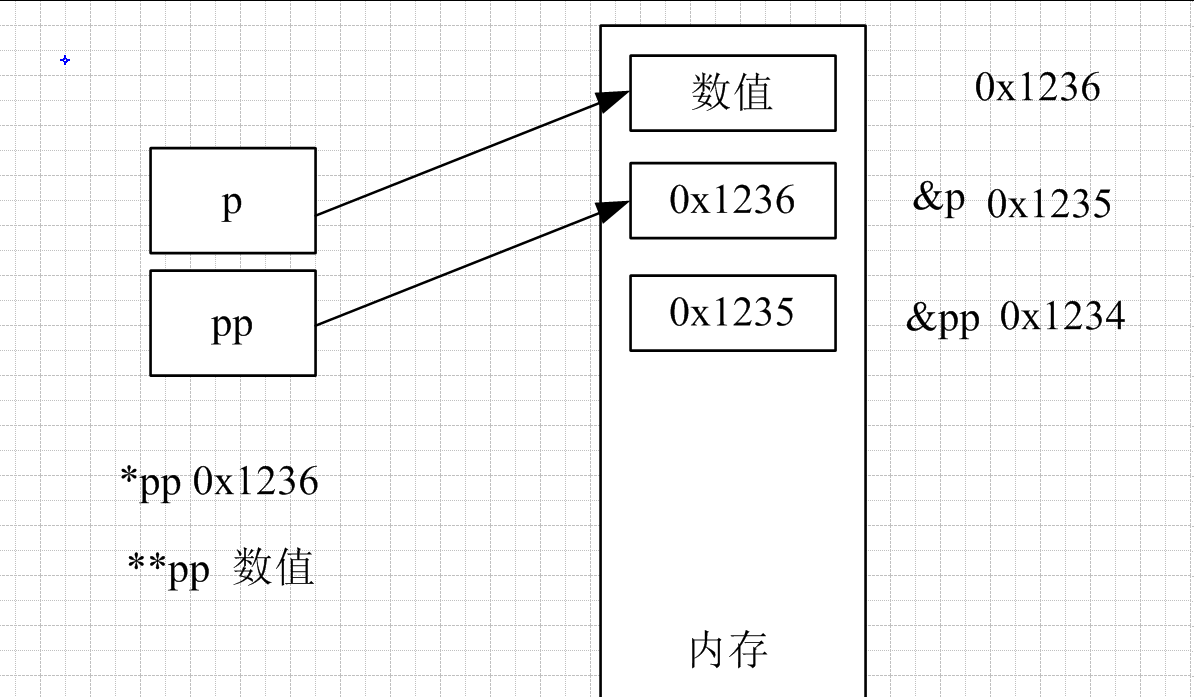
在解决这个问题之前,先了解指针非常容易混淆的属性:①.指针变量地址(&p)
②.指针变量指向的地址(p,存储数据的地址)
③.指针变量指向的地址的值(*p)
②.(pp):二级指针指向的地址,即&p,也是传入后用到的参数
③.(*pp):二级指针里保存的地址 ,*pp即*&p,也就是p,存储数据的地址
④.(**pp):二级指针的地址保存的地址,该地址里面保存的地址里面的数据,即*p,内存空间里的值
函数参数传递的只能是数值,所以当指针作为函数参数传递时,传递的是指针的值,而不是地址。
当指针作为函数参数传递时,在函数内部重新申请了一个新指针,与传入指针指向相同地址。在函数内部的操作只能针对指针指向的值。
#include <iostream> using namespace std; void pointer(int *p) { int a = 11, c = 33; printf(" Enter function"); printf(" the p is point to %p , p's addr is %X, *p is %d", p, &p, *p); *p = a; printf(" the p is point to %p , p's addr is %X, *p is %d", p, &p, *p); p = &c; printf(" the p is point to %p , p's addr is %X, *p is %d", p, &p, *p); printf(" function return "); } int main() { int b = 22; int *p = &b; printf("the b address %X ", &b); printf("the p is point to %p , p's addr is %X, *p is %d", p, &p, *p); pointer(p); printf(" the p is point to %p , p's addr is %X, *p is %d ", p, &p, *p); }
运行结果
the b address 003DFC98 the p is point to 003DFC98 , p's addr is 3DFC8C, *p is 22 Enter function the p is point to 003DFC98 , p's addr is 3DFBB8, *p is 22//说明函数内产生了一个新的指针,和p一样指向同样的地址 the p is point to 003DFC98 , p's addr is 3DFBB8, *p is 11 the p is point to 003DFB98 , p's addr is 3DFBB8, *p is 33//函数内修改的都是新指针的地址 function return the p is point to 003DFC98 , p's addr is 3DFC8C, *p is 11//此时原来的指针p,地址不变,只改变了p指向内存的数值 请按任意键继续. . .
虽然这个指针变量名字还是叫做p,但与main函数中的指针变量已经不一样了。
这意味着,你可以改变main函数中b的值,但是不能改变p的值。
又比如:
#include <iostream>
using namespace std;
void GetMemory(char *p, int num)
{
p = (char*)malloc(sizeof(char)*num);
}
void main()
{
char *s = NULL;
GetMemory(s, 100);
strcpy(s, "hello");
printf(s);
}
GetMemory这个函数是调用malloc申请一块内存。乍一看好像没什么问题,编译也不会报错。但是运行起来,程序直接奔溃。 其实有了上面的分析就可以知道,GetMemeory中的p是不能改变s的指向的,也就是说s还是指向NULL。GetMemory中的P是临时申请的一个指针变量,当s传值进来(NULL),时,p指向NULL,除此之外,没做任何改变。当运行malloc函数后,也只是将malloc返回的的指针地址赋给了p,并不能传递给s。所以这里就需要指针的指针(双重指针)了。
#include <iostream>
using namespace std;
void GetMemory(char **p, int num)
{
*p = (char*)malloc(sizeof(char)*num);
}
void main()
{
char *s = NULL;
GetMemory(&s, 100);
strcpy(s, "hello
");
printf(s);
}
这个时候就是将指针变量s的地址传递了过去,而不是将指针变量的值(NULL)传递了过去,因此就可以改变s的指向了。
其次,还可以用指针引用来修改指针的地址。
类似于普通变量传入变量引用,我们也传入一个指针引用,此时我们操作pp的值就是更改了p的值。
void make(int *&pp)
{
pp=new int(66); //试图改变p指向的地址
}
int main()
{
int a=5;
int *p=&a; //指针变量指向一个int类型的地址
cout<<"address:"<<&a<<" value:"<<a<<endl;
cout<<"address:"<<p<<" value:"<<*p<<endl;
make(p);
cout<<"address:"<<p<<" value:"<<*p<<endl;
}
类似的可以用二级指针修改p的内存
void make(int **pp)
{
int * p=new int(66);
*pp=p; //二级指针的解引用被赋值需要得到一个一级指针变量,上图中二级指针的示意图中 *pp=p
}
int main()
{
int a=5;
int *q=&a;
int **pp=&q;
cout<<"address:"<<&pp<<" "<<pp<<" "<<&q<<" "<<q<<" value:" <<*q<<endl;
make(pp);
cout<<"address:"<<&pp<<" "<<pp<<" "<<&q<<" "<<q<<" value:"<<*q<<endl;
}
3、重载、重写和重定义
重定义 (redefining)也叫做隐藏:
子类重新定义父类中有相同名称的非虚函数 ( 参数列表可以不同 ) 。
4、vector和list的区别
1.vector数据结构
vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。
因此能高效的进行随机存取,时间复杂度为o(1);
但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。
另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。
2.list数据结构
list是由双向链表实现的,因此内存空间是不连续的。
只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);
但由于链表的特点,能高效地进行插入和删除。
小结:
vector拥有一段连续的内存空间,能很好的支持随机存取,
因此vector<int>::iterator支持“+”,“+=”,“<”等操作符。
list的内存空间可以是不连续,它不支持随机访问,
因此list<int>::iterator则不支持“+”、“+=”、“<”等
vector<int>::iterator和list<int>::iterator都重载了“++”运算符。
总之,如果需要高效的随机存取,而不在乎插入和删除的效率,使用vector;
如果需要大量的插入和删除,而不关心随机存取,则应使用list。
5、C++中begin、end、front、back函数的用法
一、begin函数
函数原型:
iterator begin();
const_iterator begin();
功能:
返回一个当前vector容器中起始元素的迭代器。
二、end函数
函数原型:
iterator end();
const_iterator end();
功能:
返回一个当前vector容器中末尾元素的迭代器。
三、front函数
函数原型:
reference front();
const_reference front();
功能:
返回当前vector容器中起始元素的引用。
四、back函数
函数原型:
reference back();
const_reference back();
功能:
返回当前vector容器中末尾元素的引用。
此外,back()还可以用于字符串类型,
返回字符串的最后一个字符的引用。
6、std::find()
find函数主要实现的是在容器内查找指定的元素,并且这个元素必须是基本数据类型的。
查找成功返回一个指向指定元素的迭代器,查找失败返回end迭代器。
#include <iostream> #include <vector> #include <algorithm> using namespace std; int main(){ vector<int> v; int num_to_find=25;//要查找的元素,类型要与vector<>类型一致 for(int i=0;i<10;i++) v.push_back(i*i); vector<int>::iterator iter=std::find(v.begin(),v.end(),num_to_find);//返回的是一个迭代器指针 if(iter==v.end()) cout<<"ERROR!"<<endl; else //注意迭代器指针输出元素的方式和distance用法 cout<<"the index of value "<<(*iter)<<" is " << std::distance(v.begin(), iter)<<std::endl; return 0; }
6、类型别名、别名声明、auto类型说明符、decltype类型指示符
某种类型的同义词,有两种方法可用于定义类型别名:typedef int zhengxing;
zhengxing i=0;
using SI = Sales_item;
3、auto类型说明符
让编译器去分析表达式所属的类型。
auto 定义变量必须有初始值。
4、decltype类型指示符
选择并返回操作符的数据类型;
基本用法:
int getSize(); int main(void) { int tempA = 2; /*1.dclTempA为int*/ decltype(tempA) dclTempA; /*2.dclTempB为int,对于getSize根本没有定义,但是程序依旧正常,因为decltype只做分析,并不调用getSize,*/ decltype(getSize()) dclTempB; return 0; }
7、随机数的产生
C++中没有自带的random函数,要实现随机数的生成就需要使用rand()和srand()。需要加头文件#include <cstdlib>
不过,由于rand()的内部实现是用线性同余法做的,所以生成的并不是真正的随机数,而是在一定范围内可看为随机的伪随机数。
rand()
rand()会返回一随机数值, 范围在0至RAND_MAX 间。RAND_MAX定义在stdlib.h, 其值为2147483647。如果没有随机数种子,两次循环调用rand()所产生的随机数序列是一样的。
若要求0-n的随机数
rand()%(n-1)
srand()
srand()可用来设置rand()产生随机数时的随机数种子。通过设置不同的种子,我们可以获取不同的随机数序列。
可以利用srand((int)(time(NULL))的方法,利用系统时钟,产生不同的随机数种子。不过要调用time(),需要加入头文件< ctime >。
公式
要取得[0,n) 就是rand()%n 表示 从0到n-1的数
要取得[a,b)的随机整数,使用(rand() % (b-a))+ a;
要取得[a,b]的随机整数,使用(rand() % (b-a+1))+ a;
要取得(a,b]的随机整数,使用(rand() % (b-a))+ a + 1;