- 时间:2018-11-15 记录:byzqy
正则表达式与通配符:
正则表达式,用来在文件中匹配符合条件的字符串,正则是包含匹配。
grep、awk、sed 等命令可以支持正则表达式。
通配符,用来匹配符合条件的文件名,是完全匹配。
ls、find、cp 这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
通配符:
*(星号),代表任意字符重复任意多次;
?(问号),代表任意字符重复一次;
[](中括号),代表一个字符即中括号中写的字符;
示例:在anaconda-ks.cfg这个文件当中搜索size这个字符串
$ grep "size" anaconda-ks.cfg
注意:正则表达式中有一些符号和通配符一样,但是含义完全不同。
基础正则表达式:
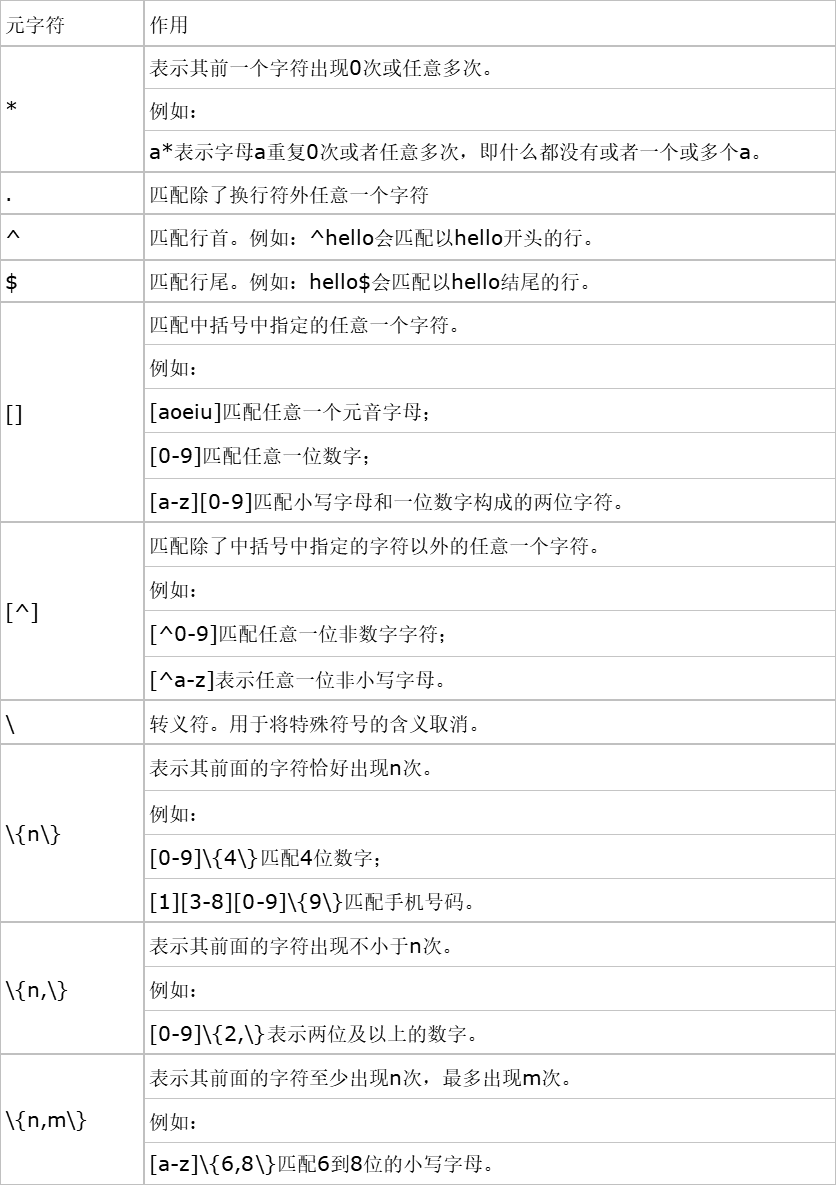
示例:星号(*)前面一个字符匹配0次,或任意多次
$ grep "a*" test_rule.txt
# 匹配所有内容,包括空白行;
$ grep "aa*" test_rule.txt
# 匹配至少包含有一个a的行;
$ prep "aaa*" test_rule.txt
# 匹配最少包含两个连续a的字符串;
$ grep "aaaaa*" test_rule.txt
# 匹配最少包含4个连续a的字符串。
示例:点号(.)匹配除了换行符外的任意一个字符
$ grep "s..d" test_rule.txt
# “s..d”会匹配在s和d这两个字母之间一定有两个字母的单词;
$ grep "s.*d" test_rule.txt
# 匹配在s和d字母之间有任意字符;
$ grep ".*" test_rule.txt
# 匹配所有内容。
示例:尖号(^)匹配行首,美元符($)匹配行尾
$ grep "^M" test_rule.txt
# 匹配以大写“M”开头的行;
$ grep “n$” test_rule.txt
# 匹配以小写“n”结尾的行;
$ grep -n "^$" test_rule.txt
# 会匹配空白行。(-n是grep的参数,表示匹配结果中显示行号)
示例:中括号([])匹配中括号中指定的任意一个字符,只匹配一个人字符
$ grep "s[ao]id" test_rule.txt
# 匹配s和i字母中间,要么是a,要么是o;
$ grep "[0-9]" test_rule.txt
# 匹配任意一个数字;
$ grep "^[a-z]" test_rule.txt
#匹配用小写字母开头的行。
示例:中括号中加尖号([^])匹配除中括号指定的字符以外的任意一个字符
$ grep "^[^a-z]" test_rule.txt
# 匹配不用小写字母开头的行;
$ grep "^[^a-zA-Z]" test_rule.txt
# 匹配不用字母开头的行。
示例:转义符()让特殊符号丧失它的特殊含义,回归到普通字符本身
$ grep ".$" test_rule.txt
# 匹配使用 “.”结尾的行。
示例:“{n}”表示其前面的字符恰好出现n次
$ grep "a{3}" test_rule.txt
# 匹配a字母连续出现三次的字符串;
$ grep "[0-9]{3}" test_rule.txt
# 匹配包含连续的三个数字的字符串。
示例:“{n,}”表示其前面的字符出现不小于n次
$ grep "^[0-9]{3,}[a-z]" test_rule.txt
# 匹配最少用连续三个数字开头的行。
示例:“{n,m}”表示匹配其前面的字符至少出现n次,最多出现m次。
$ grep "sa{1,3}i" test_rule.txt
# 匹配在字母s和字母i之间最少有一个a,最多有3个a。
--the end--