一、Redis简介
redis是一个key-value的nosql产品,和Memcached类似,但它储存的value类型相对更加丰富,包括string(字符串)、list(链表)、set(集合)、zset(sorted set有序集合)和hash,与memcached一样,为保证效率,数据都是缓存在内存库中,区别的是redis会周期性的把内存中的数据写入到硬盘中(被称为数据持久化),同时由于redis支持的是value类型众多,也被称为结构化的nosql数据库
NoSQL泛指非关系型的数据库
- 性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高
- 可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展
- 关系型数据库的优势:复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询;事务支持使得对于安全性能很高的数据访问要求得以实现
- 对于这两类数据库,对方的优势就是自己的弱势,所以如何利用好这两种数据库的强项,使其相互补充,是一个很重要的需要好好设计的问题
二、连接方式
Redis有三种连接方式:普通连接、 连接池、管道连接。
使用连接池的优点:connection pool连接池来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。
管道连接:当频繁的存储获取Redis数据库中的数据时,可以使用Redis的pipeline(管道)功能,将多个相互没有依赖关系的读写操作,如:下一步执行的Redis操作的开启需要获取上一步操作执行结束的数据。放到队列中,使用pipeline对象一次性执行,可以很大程度上减少与数据库建立TCP连接的性能损耗。(使用场景:用户浏览历史, 注册登录短信验证码,图片验证码)
三、在Python中Redis的基本使用
1、普通连接
import redis # 普通连接Redis conn = redis.Redis(host='192.168.10.22', port=6379, password='dai123') conn.set('Myjob', 'Tester1', ex=60) # set中前两个参数为key-value的键值对, ex为过期时间,单位为秒 job = conn.get('Myjob') print(job)
运行结果:
python中:

Redis服务器中:
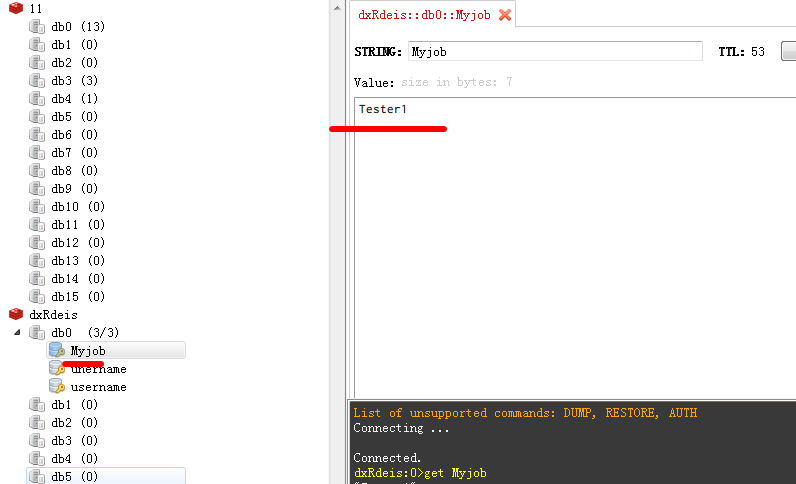
2、连接池
import redis # 连接池 pool = redis.ConnectionPool(host='192.168.10.22', port=6379, password='dai123') conn = redis.Redis(connection_pool=pool) conn.set('area', 'shenzhen') area = conn.get('area') print(area)
3、管道连接
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应
使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作 (可以跳转了解原子操作)。必须执行execute()函数后才执行该操作
import redis # 管道连接 pool = redis.ConnectionPool(host='192.168.10.22', port=6379, password='dai123') conn = redis.Redis(connection_pool=pool) pipe = conn.pipeline(transaction=True) # 原子操作 pipe.get('Myjob') pipe.get('area') pipe.execute()