WebMagic
WebMagic是一款爬虫框架,其底层用到之前学习到的HttpClient 和 Jsoup ,可以让我们更方便的开发爬虫。
WebMagic 项目代码分为核心和扩展两部分
- 核心部分是一个精简的、模块化的爬虫实现;
- 扩展部分则包括一些便利的、实用性强的功能。
WebMagic 的设计目标是尽量的模块化,并体现爬虫的功能特点。这部分提供了非常简单、灵活的API,在基本不改变开发模式的情况下,编写爬虫。
扩展部分提供一些便捷的功能,例如注解模式编写爬虫等。同事内置一些常用的组件,便于爬虫开发。
WebMagic架构
WebMagic 的结构分为 Downloader、PageProcessor、Scheduler、Pipeline四大组件,并有 Spider 将它们彼此组织起来。这四大组件分别对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic 的设计参考了 Scrapy(Python中的),但是实现方式更Java化一些。
结构执行流程如下:
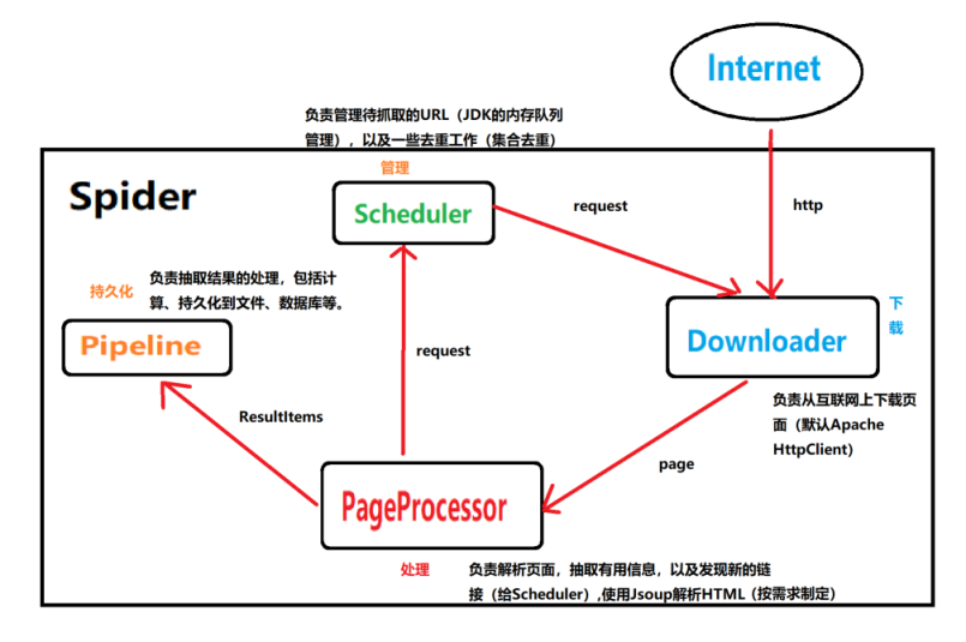
用于数据流转的对象
1.Request
Request(请求)跟我们web中学习的一样,Request是对 URL 地址的一层封装,一个Request对应一个URL地址。
它是 PageProcessor 与 Downloader 交互的载体,也是 PageProcessor 控制 Downloader 唯一方式。
2.Page
Page 代表了从 Downloader 下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page 是 WebMagic 抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
3.ResultItems
ResultItems 相当于一个Map,它保存 PageProcessor 处理的结果,供 Pipeline 使用。
它的API与Map很类似,其中它有一个字段 skip,为true时,则不应该被 Pipeline处理。
入门案例
1.导入依赖
创建Maven工程,并加入以下依赖 :
<dependencies>
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-core -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-extension -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
</dependencies>
ps: 0.7.3版本对SSL的并不完全,如果是直接从 Maven 中央仓库下载的依赖,在爬取只支持 SSL v1.2 的网站会有SSL的异常抛出。
解决方案:
1.等0.7.4版本的发布(放弃吧,有的人已经等三年了)
2.直接从 github 上下载最新的代码,安装到本地仓库(https://github.com/code4craft/webmagic)
-
-
- 下载解压(照顾一下 git用的不溜的小伙伴,就不使用 git了)
-
-
跳过测试方法
-
-
安装到本地仓库
-
-
2.加入配置文件
WebMagic 已使用slf4j-log4j12作为 slf4j 的实现,无需导包。
加配置文件
log4j.rootLogger=INFO,A1 log4j.appender.A1=org.apache.log4j.ConsoleAppender log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] %m%n
3.1编写代码
public class JobProcessor implements PageProcessor { public static void main(String[] args) { Spider.create(new JobProcessor()) // new一个自己所写的JobProcessor对象 .addUrl("http://112.124.1.187/index.html") .run(); } // 负责解析页面 @Override public void process(Page page) { // 解析返回的数据page,并且把解析的结果放到 ResultItems 中 page.putField("首页通知",page.getHtml().css("div.content h2").all()); } // 这个,将就写着,入门案例嘛,后面讲到 private Site site = Site.me(); @Override public Site getSite() { return site; } }
ps: 这里解析页面数据:" page.putField("首页通知",page.getHtml().css("div.content h2").all()); ” 使用到的是 css抽取元素,另外还有 XPath、正则表达式 的方法来抽取元素,他们还可以拼接使用,这个可以自己去了解。
在抽取的过程中,总有可能抽取到多条元素,可使用不同的API获取一个或多个元素:
page.putField("首页通知",page.getHtml().css("div.content h2").get() // 一个元素(默认第一个)
page.putField("首页通知",page.getHtml().css("div.content h2").toString() // 一个元素(默认第一个)
page.putField("首页通知",page.getHtml().css("div.content h2").all() // 所有元素
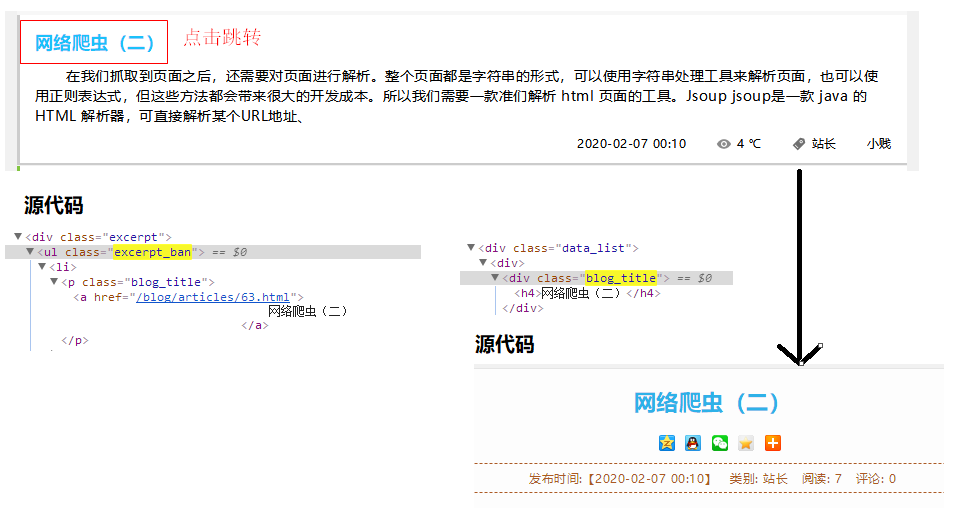
3.2 获取链接
// 放在上面的 process 方法中执行。
// 获取链接 // 这一行代码,获取,当前页面中抽取出来的带有其他 URL 地址的元素 page.addTargetRequests(page.getHtml().css(".excerpt_ban p").links().all()); // 这之间,做了一个跳转。下面的代码针对目标url地址的页面 // 这一行代码,获取,目标 url 的HTML页面中,你要抽取的元素 page.putField("链接抓取,博客标题",page.getHtml().css(".blog_title h4").all());
图解:
3.3 使用 Pipeline 保存数据
WebMagic 用于保存结果的组件叫 Pipeline,默认向控制台输出结果,由内置的Pipeline(ConsolePipeline)完成。
将结果保存到文件中,将 Pipeline 的实现换成 FilePipeline.
public static void main(String[] args) { Spider.create(new JobProcessor()) // new一个自己所写的JobProcessor对象 .addUrl("http://112.124.1.187/index.html") // 设置爬取数据的页面地址 .addPipeline(new FilePipeline("E:\Crawler File")) // 结果保存到文件中 .thread(5) // 多线程:设置有5个线程处理(太草率了....) .run(); }
爬虫的配置、启动和终止
Spider 是爬虫启动的入口。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用run()启动。
同时,Spider 的其他组件(Downloder、Scheduler、Pipeline) 都可以配置。
-
- create(PageProcessor) 创建Spider
- addUrl(String .. urls) 添加初始的URL
- thread(int n) 开启n个线程
- run() 启动,会阻塞当前线程执行
- start()/runAsync() 异步启动,当前线程继续执行
- stop 停止爬虫
- addPipeline(Pipeline p) 添加一个 Pipeline ,一个Spider可以有多个Pipeline
- setScheduler(Scheduler s) 设置 Scheduler,一个Spider可以有多个 Scheduler
- setDownloader(Downloader d) 设置 Downloader,一个Spider只能有一个 Downloader
- get(String str) 同步调用,并直接取得结果
- getAll(String ...str) 同步调用,并直接取得一堆结果
- 站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略、代理等,都可以通过 Site 对象进行配置。
// 这个,将就写着,入门案例嘛,后面讲到 private Site site = Site.me() .setCharset("utf-8") // 设置编码 .setTimeOut(10 * 1000) // 设置超时时间,单位:毫秒 .setSleepTime(10) // 抓取间隔时间 .setCycleRetryTimes(10 * 1000) // 重试的时间 .setRetryTimes(3) // 重试次数 ;
-
- setCharset(String charSet) 设置编码
- setUserAgent(String str) 设置 UserAgent
- setTimeOut(int ms) 设置超时时间,单位:毫秒
- setRetryTimes(int num) 设置重试次数
- setCycleRetryTimes(int num) 设置循环重试次数
- addCookie(String key,String val) 添加一条 cookie
- setDomain(String str) 设置域名,需设置域名后,addCookie才可生效
- addHeader(String s1,String s2) 添加一条 请求头部
- setHttpProxy(HttpHost host) 设置 Http 代理