近期参加一个课题,聊到路线规划问题,需要搜索两地点的最短线路距离以及最短用时等情况,然后就想着用借用百度API,做个参考
环境:
python 3.6
主要问题:
1. 分析百度官方路线规划API了解到路线规划需要提供经纬度信息,于是借用百度地理编码是指将地址或地名等位置描述转换为经纬度坐标的过程。得到的坐标信息,可以用于制图或空间分析操作。(出于国家安全考虑,公布出来的坐标信息一般是经过加偏的。)http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding
2. 根据经纬度信息,现有起点和终点坐标值(经纬度lng、lat),目的是通过百度地图开发者平台的路线规划功能获取起点终点路线规划距离和预估时长,百度地图开发者平台路线规划使用说明网址为:http://lbsyun.baidu.com/index.php?title=webapi/direction-api-abroad
3.爬取过程可能会由于服务器或者参数不满足要求导致爬虫中断,注意处理这个问题即可
4.一是注意源文件的数据格式要转utf-8;二是修改文件路径;三是AK需要自行去开发者平台申请。
代码如下(由于文件不方便上传,只需稍作修改,即可使用):
# -*- coding:utf-8 -*- # ------------------------------ # @Time :2019/5/9 13:32 # @Author :jonie # @Email : # @File :code_get.py # Description: # ------------------------------ import csv import json import time import requests from bs4 import BeautifulSoup from urllib.request import urlopen, quote import json import requests # [113.63095213159264, 34.74830559988335]# origin_path = 'data/赛点.csv' # 原始数据文件路径 new_path = 'data/地址对应坐标.txt' # 爬取数据文件保存路径 machine_data = csv.reader(open(origin_path, 'r', encoding='utf-8')) # 读取原始文件数据 for addr in machine_data: # 循环爬取每一条数据 # print(addr[2]) address = addr[1] ak = 'FA8atAaqd1wajikD56lPqtiaNCldeya' url = 'http://api.map.baidu.com/geocoder/v2/?address=' output = 'json' # ak = '你的ak'#需填入自己申请应用后生成的ak add = quote(address) # 本文城市变量为中文,为防止乱码,先用quote进行编码 url2 = url + add + '&output=' + output + "&ak=" + ak req = urlopen(url2) res = req.read().decode() temp = json.loads(res) lng = temp['result']['location']['lng'] # 获取经度 lat = temp['result']['location']['lat'] # 获取纬度 lng = ("%.5f" % lng) lat = ("%.5f" % lat) list1 = [lng, lat,addr[0]] print('百度坐标为:', list1) with open(new_path, 'a', encoding='utf-8') as f: f.write(str(list1)) f.write(' ') f.close() with open("data/赛点信息.csv", 'a', newline='',encoding='utf-8') as t: # numline是来控制空的行数的 writer = csv.writer(t) # 这一步是创建一个csv的写入器(个人理解) writer.writerow(list1) # 写入标签 # writer.writerows(n) # 写入样本数据 t.close()
调用百度地图api获取起点终点路线规划距离和预估时长代码
1 import csv 2 import re 3 import time 4 import json 5 from urllib.request import urlopen 6 import urllib 7 8 # 原数据文件格式csv: 起点纬度 + 起点经度 + 索引 + 终点纬度 + 终点经度 9 origin_path = 'data/b.csv' # 原始数据文件路径 10 result_path = 'data/result122901.txt' # 爬取数据文件保存路径 11 12 # 百度地图提供的api服务网址 13 url_drive = r"http://api.map.baidu.com/direction/v2/driving" # 驾车(routematrix 批量算路) 14 url_ride = r'http://api.map.baidu.com/routematrix/v2/riding?output=json' # 骑行 15 url_walk = r'http://api.map.baidu.com/routematrix/v2/walking?output=json' # 步行 16 url_bus = r'http://api.map.baidu.com/direction/v2/transit?output=json' # bus(direction路线规划) 17 cod = r"&coord_type=bd09ll" 18 # 声明坐标格式,bd09ll(百度经纬度坐标);bd09mc(百度摩卡托坐标);gcj02(国测局加密坐标),wgs84(gps设备获取的坐标) 19 # AK为从百度地图网站申请的秘钥,额度不够的时候直接在list后面新增AK就行 20 AK = ['FA8atAaqd1wajikD56lPqtiasdfleCeyz'] 21 # 把变量名先写入文件 22 colnames = '设备序列号 起点 终点 状态码 步行路程(米) 步行耗时(秒)' 23 with open(result_path, 'a', encoding='utf-8') as f: 24 f.write(colnames) 25 f.write(' ') 26 f.close() 27 28 address = csv.reader(open(origin_path, 'r', encoding='utf-8')) # 读取原始文件数据 29 30 # for ad in address: 31 # # print(ad) 32 # print(ad[0]) 33 # print(ad[1]) 34 # print(ad[2]) 35 # print(ad[3]) 36 # print(ad[4]) 37 n = 0 38 akn1 = 0 39 akn2 = 0 40 a = 0 41 while True: 42 try: # 避开错误:文件编码问题、服务器响应超时、 43 for ad in address: 44 if (akn1 < len(AK)) and (akn2 < len(AK)): # 配额是否够 45 mac_code = str(ad[2]) # 设备序列号 46 try: 47 ori = str(ad[0]) + ',' + str(ad[1]) # 起点 48 des = str(ad[3]) + ',' + str(ad[4]) # 终点 49 ak_drive = AK[akn1] 50 ak_bus = AK[akn2] 51 ak_drive2 = r'&ak=' + ak_drive 52 ak_bus2 = r'&ak=' + ak_bus 53 ori1 = r"?origin=" + ori 54 des1 = r"&destination=" + des 55 # 以下是自驾车 56 tac_type = r'&tactics=11' # 驾车路径:常规路线 57 # 10不走高速;11常规路线;12距离较短;13距离较短(不考虑路况) 只对驾车有效 58 aurl_drive = url_drive + ori1 + des1 + cod + tac_type + ak_drive2 # 驾车规划网址 59 res_drive = urlopen(aurl_drive) # 打开网页 60 cet_drive = res_drive.read() # 解析内容 61 res_drive.close() # 关闭 62 result_drive = json.loads(cet_drive) # json转dict 63 status = result_drive['status'] 64 print('驾车码', status) 65 if status == 0: # 状态码为0:无异常 66 m_drive = result_drive['result']["routes"][0]['distance'] # 里程(米) 67 m_drive2 = float(m_drive) # str转float 68 timesec_drive = result_drive['result']["routes"][0]['duration'] # 耗时(秒) 69 diss_drive = '状态' + str(status) + ' ' + str(m_drive) + ' ' + str(timesec_drive) # 驾车总 70 elif status == 302 or status == 210 or status == 201: # 302:额度不足;210:IP验证未通过 71 m_drive2 = 10000 # 赋值(大于5km),即不爬取步行规划 72 akn1 += 1 73 diss_drive = '状态' + str(status) + ' break break' 74 else: 75 m_drive2 = 10000 # 赋值(大于5km),即不爬取步行规划 76 diss_drive = '状态' + str(status) + ' na na' 77 try: # 当驾车规划m_drive2为空的时候,if语句发生错误 78 if 0 < m_drive2 < 5000: # 里程低于5公里则爬取步行规划 79 aurl_walk = url_walk + ori1 + des1 + cod + ak_drive2 # 步行规划网址 80 res_walk = urlopen(aurl_walk) # 打开网页 81 cet_walk = res_walk.read() # 解析内容 82 result_walk = json.loads(cet_walk) # json转dict 83 res_walk.close() # 关闭网页 84 status_walk = result_walk['status'] # 状态码 85 if status_walk == 0: # 状态正常 86 m_walk = result_walk['result']["routes"][0]['distance'] # 步行距离 87 time_walk = result_walk['result']["routes"][0]['duration'] # 步行时间 88 diss_walk = str(m_walk) + ' ' + str(time_walk) # 步行总 89 else: # 状态异常 90 diss_walk = 'na na' 91 else: # 里程大于5km则不爬取步行规划 92 diss_walk = 'na na' 93 except: # 发生错误时步行数据也赋值为na 94 diss_walk = 'na na' 95 pass 96 # 以下是乘车规划 97 tac_bus = r'&tactics_incity=0' 98 # 市内公交换乘策略 可选,默认为0 0推荐;1少换乘;2少步行;3不坐地铁;4时间短;5地铁优先 99 city_bus = r'&tactics_intercity=0' 100 # 跨城公交换乘策略 可选,默认为0 0时间短;1出发早;2价格低; 101 city_type = r'&trans_type_intercity=2' 102 # 跨城交通方式策略 可选,默认为0 0火车优先;1飞机优先;2大巴优先; 103 ori2 = r"&origin=" + ori 104 des2 = r"&destination=" + des 105 aurl_bus = url_bus + ori2 + des2 + tac_bus + city_bus + city_type + ak_bus2 106 res_bus = urlopen(aurl_bus) 107 cet_bus = res_bus.read() 108 res_bus.close() 109 result_bus = json.loads(cet_bus) 110 status = result_bus['status'] 111 print('乘车码', status) 112 # -------------------------------------- 113 # if status == 0: 114 # rsls = result_bus['result']['routes'] 115 # if rsls == []: # 无方案时状态也为0,但只返回一个空list 116 # diss_bus = '状态' + str(status) + ' ' + '无公交方案' 117 # else: 118 # m_bus = result_bus['result']['routes'][0]['distance'] # 乘车路线距离总长(米) 119 # time_bus = result_bus['result']['routes'][0]['duration'] # 乘车时间(秒) 120 # cost_bus = result_bus['result']['routes'][0]['price'] # 乘车费用(元) 121 # diss_bus = '状态' + str(status) + ' ' + str(m_bus) + ' ' + str(time_bus) + ' ' + str(cost_bus) 122 # elif status == 302 or status == 210 or status == 201: 123 # akn2 = akn2 + 1 124 # diss_bus = '状态' + str(status) + ' ' + '更换AK断点' 125 # else: # 其他类型状态码(服务器错误) 126 # diss_bus = '状态' + str(status) + ' ' + '服务器错误' 127 # ----------------------------------------------- 128 # 汇总数据 129 diss = mac_code + ' ' + str(ori) + ' ' + str( 130 des) + ' ' + diss_drive + ' ' + diss_walk #+ ' ' + diss_bus 131 with open(result_path, 'a', encoding='utf-8') as f: 132 f.write(diss) 133 f.write(' ') 134 f.close() 135 n += 1 136 print('第' + str(n) + '条已完成') 137 except: 138 time.sleep(3) 139 diss_wrong = str(mac_code) + '未知错误' 140 with open(result_path, 'a', encoding='utf-8') as f: 141 f.write(diss_wrong) 142 f.write(' ') 143 f.close() 144 continue 145 else: 146 print('配额不足!') 147 break 148 except: 149 time.sleep(3) 150 print('未知错误') 151 with open(result_path, 'a', encoding='utf-8') as f: 152 f.write('未知错误') 153 f.write(' ') 154 f.close() 155 continue 156 print('程序已停止运行') 157 break # 跑完数时break打断while循环,for循环的话这里不好定义循环条件
最终根据生成的数据作图如下:
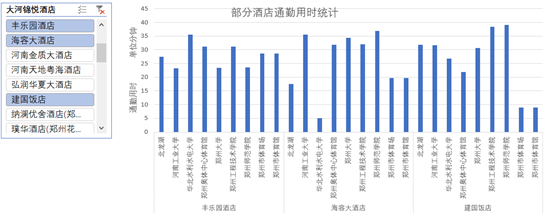
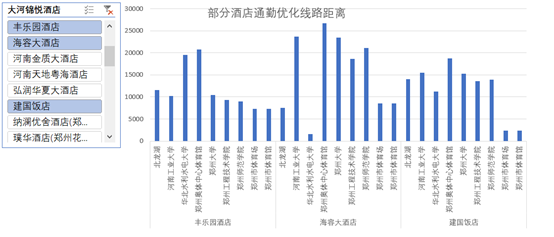
附录:
1.数据获取(借助携程网爬取郑州市以好评度优先的方式爬取所有星级酒店信息)
1 import requests 2 import random 3 from bs4 import BeautifulSoup 4 import time 5 import csv 6 import json 7 import re 8 import pandas as pd 9 import numpy as np 10 11 pd.set_option('display.max_columns', 10000) 12 pd.set_option('display.max_rows', 10000) 13 pd.set_option('display.max_colwidth', 10000) 14 pd.set_option('display.width',1000) 15 16 # Beijing 5 star hotel list url 17 five_star_url = "http://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx" 18 filename = "data/star hotel list.csv" 19 20 def Scrap_hotel_lists(): 21 """ 22 It aims to crawl the 5 star hotel lists in Beijing and save in a csv file. 23 """ 24 headers = { 25 "Connection": "keep-alive", 26 "origin": "http://hotels.ctrip.com", 27 "Host": "hotels.ctrip.com", 28 "referer": "https://hotels.ctrip.com/hotel/zhengzhou559", 29 "user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36", 30 "Content-Type":"application/x-www-form-urlencoded; charset=utf-8" 31 } 32 33 34 35 id = [] 36 name = [] 37 hotel_url = [] 38 address = [] 39 score = [] 40 41 # 8 pages 42 for page in range(1,8): 43 44 data = { 45 "StartTime": "2019-09-08", # The value depends on the date you want to scrap. 46 "DepTime": "2019-09-18", 47 "RoomGuestCount": "0,1,2", 48 "cityId": 559, 49 "cityPY": " zhengzhou", 50 "cityCode": "0371", 51 "cityLat": 34.758044, 52 "cityLng": 113.673121, 53 "page": page, 54 "star": "3", 55 "orderby": 3 56 } 57 html = requests.post(five_star_url, headers=headers, data=data) 58 59 # print(html.text) 60 j= json.loads(html.text.replace("洛阳","洛阳")) 61 #hotel_list = html.json()["totalMsg"] 62 hotel_list = j["hotelPositionJSON"] 63 64 for item in hotel_list: 65 id.append(item['id']) 66 name.append(item['name']) 67 hotel_url.append(item['url']) 68 address.append(item['address']) 69 score.append(item['score']) 70 71 time.sleep(random.randint(3,5)) 72 hotel_array = np.array((id, name, score, hotel_url, address)).T 73 list_header = ['id', 'name', 'score', 'url', 'address'] 74 array_header = np.array((list_header)) 75 hotellists = np.vstack((array_header, hotel_array)) 76 with open(filename, 'a', encoding="utf-8-sig", newline="") as f: 77 csvwriter = csv.writer(f, dialect='excel') 78 csvwriter.writerows(hotellists) 79 80 81 def hotel_detail(hotel_id): 82 """ 83 It aims to scrap the detailed information of a specific hotel. 84 """ 85 headers = {"Connection": "keep-alive", 86 "Accept-Language": "zh-CN,zh;q=0.9", 87 "Cache-Control": "max-age=0", 88 "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", 89 "Host": "hotels.ctrip.com", 90 "If-Modified-Since": "Thu, 01 Jan 1970 00:00:00 GMT", 91 "Referer": "http://hotels.ctrip.com/hotel/2231618.html", 92 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " 93 "Chrome/69.0.3497.92 Safari/537.36" 94 } 95 96 basic_url = "http://hotels.ctrip.com/Domestic/tool/AjaxHote1RoomListForDetai1.aspx?hotel=" 97 url = basic_url + str(hotel_id) 98 99 r = requests.get(url, headers=headers) 100 # Response is a json object. 101 html = r.json()['html'] 102 soup = BeautifulSoup(html, "lxml") 103 rooms = soup.findAll('td', attrs={"class": "child_name J_Col_RoomName"}) 104 105 RoomID = [] 106 RoomName = [] 107 LowPrice = [] 108 RoomSize = [] 109 RoomLevel = [] 110 IsAddBed = [] 111 BedSize = [] 112 CustomerNum = [] 113 114 # Regex Pattern 115 baseroom_pattern = re.compile(r'<[^>]+>') # r'<[^>]+>' 116 117 for idx in range(len(rooms)): 118 if rooms[idx].has_attr(key='data-baseroominfo'): 119 room_info_str = rooms[idx]['data-baseroominfo'] 120 room_info_json = json.loads(room_info_str) 121 RoomID.append(str(room_info_json["RoomID"])) 122 RoomName.append(room_info_json["RoomName"]) 123 LowPrice.append(room_info_json["LowPrice"]) 124 125 baseroom_info = room_info_json["BaseRoomInfo"] 126 # print(type(baseroom_info)) 127 # <class 'str'> 128 remove_tag = baseroom_pattern.sub("", baseroom_info) 129 RoomDetailInfo = remove_tag.split("|") 130 if len(RoomDetailInfo) == 4: 131 RoomDetailInfo.insert(3, None) 132 133 RoomSize.append(RoomDetailInfo[0]) 134 RoomLevel.append(RoomDetailInfo[1]) 135 BedSize.append(RoomDetailInfo[2]) 136 IsAddBed.append(RoomDetailInfo[3]) 137 CustomerNum.append(RoomDetailInfo[4]) 138 else: 139 continue 140 141 RoomInfo = np.array((RoomID, RoomName, LowPrice, RoomSize, RoomLevel, BedSize, IsAddBed, CustomerNum)).T 142 # Create a DataFrame object 143 # print(RoomInfo) 144 column_name = ['RoomID', 'RoomName', 'LowPrice', 'RoomSize', 'RoomLevel', 'BedSize', 'IsAddBed', 'CustomerNum'] 145 df = pd.DataFrame(data=RoomInfo, columns=column_name) 146 print(df) 147 148 149 if __name__ == "__main__": 150 151 # # 1. Scrap 5 star hotel list in Beijing 152 Scrap_hotel_lists() 153 154 # 2. Scrap the detailed hotel information 155 df = pd.read_csv(filename, encoding='utf8') 156 print("1. Beijing 5 Star Hotel Lists") 157 print(df) 158 hotelID = df["id"] 159 print(' ') 160 161 while True: 162 print("2.1 If you find to search the detail hotel information, please input the hotel index in the DataFrame.") 163 print("2.2 If you want to quit, input 'q'.") 164 165 print("Please input the Parameter: ") 166 input_param = input() 167 if input_param.isnumeric(): 168 hotel_index = int(input_param) 169 if 0 <= hotel_index <= 170: 170 print("3. The detail information of the Hotel:") 171 hotel_detail(hotelID[hotel_index]) 172 else: 173 print('Hotel Index out of range! ') 174 print('Remember: 0 <= Hotel Index <= 170') 175 print('Please input again.') 176 continue 177 elif input_param == 'q': 178 print('See you later!') 179 break 180 else: 181 print('Invalid Input!') 182 print(' ') 183 continue
2.根据生成数据绘制酒店信息云图
from pyecharts import WordCloud import random name1 =hotel_list2 random_list =[296, 630, 。。。] # 也可以通过一下三行生成随机整数列表 # for i in range(len(name1)): # #随机产生len(name1)个300-10000整数 # random_list.append(random.randint(300,800)) # print('生成的随机整数列表为: ',random_list) value =random_list wordcloud =WordCloud(width=1300, height=800) wordcloud.add("酒店信息", name1, value, word_size_range=[10,20], shape='pentagon') wordcloud.show_config() wordcloud.render()

Note:以上纯属娱乐学习之用。