前面已经知道了如何判断对象会被回收。那么现在来分析一下这些垃圾对象是如何被收集的,通过什么算法收集的。
GC 常用算法有:
标记-清除算法
复制算法
标记-整理算法
分代收集算法
目前主流的jvm(HotSot)采用的是分代收集算法。
标记-清除(Mark-Sweep)算法
算法分为“标记”和“清除”两个阶段,首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。
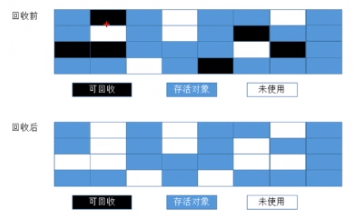
该算法的缺点:
效率问题:整个内存区域一个一个标记是否为垃圾对象,再一个一个清除掉,效率低
空间问题(标记清除后会产生大量不连续的碎片)
复制(Copying)算法(适用于年轻代survivor区使用)
复制算法是将内存分为大小相同的两块,每次只用其中一块,当这一块内存用完了,就将存活着的对象复制到另外一块上面,然后再把已经使用过的内存空间一次性清理掉。
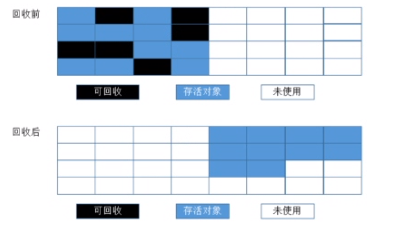
复制算法优点:
效率较高
剩余空间的利用率较高
从上图可以看出,复制算法效率是比标记-清除算法高的,复制算法只需要在其中一块的内存中标记出哪些是存活对象,再挨个连续放在另外一半内存块中,之后再一次性清除原来那一半内存块的所有对象。并且,可以看到存活对象是连续存放的,也就是说剩余内存也是连续的内存空间,可以用来存放一些较大的对象。剩余空间利用率高。
复制算法缺点:
整体内存空间使用率低:将内存一分为二使用,每次只使用一半内存,整体的内存使用率低。
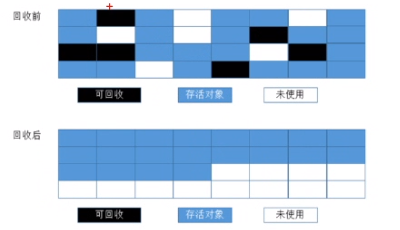
标记-整理算法
根据老年代的特点,有人提出了另外一种标记-整理算法。过程与标记-清除算法一样,不过不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉边界以外的内存。
分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象(近99%)死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分噢诶担保,所以我们必须选择“标记-清除”或者“标记-整理”算法进行垃圾收集。