目录
5 函数
如果输入参数作为null,则Cypher中的函数返回null
将字符串作为输入的函数都在Unicode字符上操作,而不是在标准char[]上操作。例如,size(s),其中s是中文字符,也会返回1。
5.1 谓词函数
这些函数官网原文叫predicate function,翻译过来就是谓词函数,对于为什么要这么叫我也觉得不是很能理解,在上世纪5 60年代,知识图谱前身的RDF,进行的推理中,就包含了本体推理和规则推理。规则推理中,最基础的就是所谓的一阶谓词逻辑,个人认为所谓的谓词大概就是简单的逻辑关系的判断吧。
all()、any()、exists()、none()、single()
这些预测函数都是bool类型,对于给定的非空输入返回true or false。它们最常用于过滤掉查询的where部分中的子图。
all():对所有元素都满足条件返回true,否则返回false。
建表语句见Neo4j Cypher语法(一)3.2.2case表达式。

MATCH p =(a)-[*1..3]->(b)
WHERE a.name = 'Alice' AND b.name = 'Daniel' AND ALL (x IN nodes(p) WHERE x.age > 30)
RETURN p
该语句的意思是找到一条从Alice可以走到Daniel的路径,要求路径上的每一个节点的age都大于30,包括起始和终止的Alice和Daniel节点,但是回顾建表语句可知,Daniel节点时不具备age属性的,所以这条查询语句不会返回结果。

any():在给定列表中有一个元素满足对应子句即可。
none():如果在给定的元素列表中没有元素满足对应条件,返回真值。
MATCH p =(n)-[*1..3]->(b)
WHERE n.name = 'Alice' AND NONE (x IN nodes(p) WHERE x.age = 25)
RETURN p
该查询语句的作用是找到一条或多条路径,这条路径的起始节点和终止节点经过1条、2条或者3条边的距离,这条路径上的所有节点,对于x.age=25(这里的=符号和其余编程语言中的逻辑等==是一样的,不是我们理解的赋值)这个条件都会返回false。根据下方的列表和连通图来看,从Alice出发,要求年龄不等于25,那么和Bob相连的所有边都会被切断。这里还有一点要稍微注意的是,由于Daniel节点没有设置age属性,即Daniel.age会返回null值,这里的null值既不是true也不是false,所以Daniel节点也不会在返回结果中。
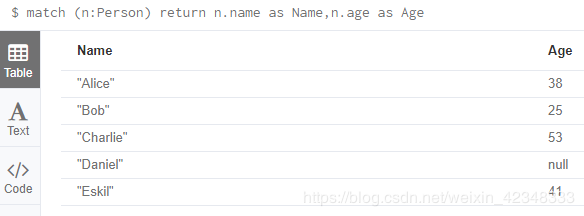

返回结果:

为验证我们刚才的判断,手动给Daniel设置一个不等于25的age属性。
match (n:Person{name:'Daniel'}) set n.age=37
再执行刚才的match语句,结果发生了变化,现在Daniel节点肯定是包含于路径的,如后续想删除属性可使用remove语句:

single() :如果在给定列表中,仅仅一个元素满足预测条件/筛选条件,则返回真。
5.2 标量函数
length():对路径使用length()
id():返回某个节点或者关系的id,即下图中使用尖括号括起来的内置属性,在创建节点或者关系时会自动创建。
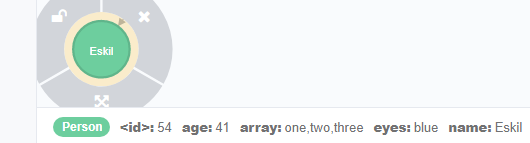
match(n:Person{name:'Eskil'}) return id(n)
size():对字符串、列表和模式表达式使用size()
coalesce():返回表达式列表的第一个非空值
:param {a:[null,1]}
return coalesce($a[0],$a[1]) as res

EndNode():返回关系中的结束节点 startNode()
Head():返回列表中的第一个元素。
Last():返回列表中的最后一个元素。
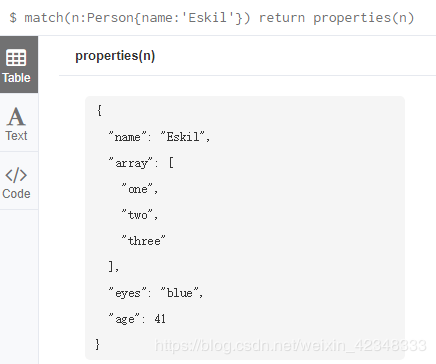
properties():以映射形式返回对应的属性
match(n:Person{name:'Eskil'}) return properties(n)
Type():返回关系的类型
timestamp():返回毫秒级时间戳
toBoolean():将字符串类型转换为Bool类型
RETURN toBoolean('TRUE'), toBoolean('not a boolean')

toFloat():将整型或者字符串转换为浮点类型。除非有特定的需求,个人不建议在存属性时使用这两个函数。因为一旦使用这两个函数入库,后续如果要进行属性判断,也要写成这种形式:match (n) where n.age =toInteger(25),这样一是复杂。而是属性多了之后记不住自己最初转换了什么类型
toInteger():将字符串或者浮点类型转换为整型
5.3 聚合函数
聚合函数采用一组值并计算它们的聚合值。示例是avg(),用于计算多个数值的平均值,或min(),用于查找一组值中的最小数值或字符串值。当我们在下面说聚合函数对一组值进行操作时,我们的意思是这些是将内部表达式(例如n.age)应用于同一聚合组中的所有记录的结果。
可以在所有匹配的子图上计算聚合,或者可以通过引入分组键来进一步划分聚合。这些是非聚合表达式,用于对进入聚合函数的值进行分组。
举例:
Return n,count(*)
我们有两个返回表达式:n和count(*)。第一个,n,不是聚合函数,因此它将是分组键。后者count(*)是一个聚合表达式。匹配的子图将根据分组键分为不同的桶。然后,聚合函数将在这些桶上运行,计算每个桶的聚合值。
要使用聚合对结果集进行排序,聚合必须包含在要在ORDER BY中使用的RETURN中。
DISTINCT运算符与聚合一起使用。它用于在通过聚合函数运行它们之前使所有值唯一。
avg() - Numeric values
MATCH (n:Person)
RETURN avg(n.age)

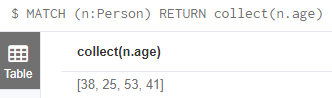
collect() 返回列表
MATCH (n:Person)
RETURN collect(n.age)
count() count(*)返回计数
max()
MATCH (n:Person)
RETURN max(n.age)
min() UNWIND [1, 'a', NULL , 0.2, 'b', '1', '99'] AS val //返回的是1的字符类型,判断的是ascii码值?
RETURN min(val)
UNWIND ['d',[1, 2],['a', 'c', 23]] AS val
RETURN min(val)//返回的是['a','c',23]
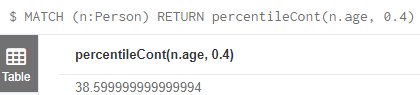
percentileCont() //这两个方法没太看懂,还是先记录一下吧
MATCH (n:Person)
RETURN percentileCont(n.age, 0.4)
//返回属性年龄值的第40个百分位数,使用加权平均值计算。 在这种情况下,0.4是中位数,或40%。
percentileDisc()
MATCH (n:Person)
RETURN percentileDisc(n.age, 0.5)

stDev() MATCH (n)
WHERE n.name IN ['A', 'B', 'C']
RETURN stDev(n.age)//返回标准差,除的是n-1
stDevP() 返回除n的标准差
5.4 列表函数
keys() //keys返回一个列表,其中包含节点,关系或映射的所有属性名称的字符串表示形式。这对于json数据也可以直接使用
MATCH (a)
WHERE a.name = 'Alice'
RETURN keys(a)
labels()
MATCH (a)
WHERE a.name = 'Alice'
RETURN labels(a)
nodes()
MATCH p =(a)-->(b)-->(c)
WHERE a.name = 'Alice' AND c.name = 'Eskil'
RETURN nodes(p)//返回在路径上的所有节点
range()
与Python的range不同,是左闭右闭的
reduce() MATCH p =(a)-->(b)-->(c)
WHERE a.name = 'Alice' AND b.name = 'Bob' AND c.name = 'Daniel'
RETURN reduce(totalAge = 0, n IN nodes(p)| totalAge + n.age) AS reduction//对列表中的所有元素代入表达式 |管道符右侧为表达式
relationships() //返回路径中包含的所有关系的列表 [:KNOWS[0]{},:MARRIED[4]{}] 这里的0和4代表了什么,暂时还不清楚
MATCH p =(a)-->(b)-->(c)
WHERE a.name = 'Alice' AND c.name = 'Eskil'
RETURN relationships(p)
reverse() 返回逆序列表
tail() //返回去除掉第一个元素的列表
5.5 数学函数
abs() ceil() floor() 绝对值、向上取整、向下取整
rand() 返回[0,1)的随机数
round() 四舍五入
sign() 将正数、负数和0映射为1、-1、0
e() 返回2.71828
exp() log() e的n次方 自然对数:以e为底的对数
log10() sqrt() 其余三角函数自行查询手册
5.6 字符串函数
left() RETURN left('hello', 3)//自左边起的3个字符
lTrim() 去除掉字符串左边的空格
replace() RETURN replace("hello", "l", "w")//返回hewwo
reverse() 字符串逆序
right() 与left相对
rTrim() 去除掉字符串右边的空格
split() RETURN split('one,two', ',')
substring() RETURN substring('hello', 1, 3), substring('hello', 2)//ell llo
toLower()、toString()、toUpper()
trim() 删除字符串首尾的空格
5.7 Udf与用户自定义函数
用户定义的函数用Java编写,需要查看apoc的具体用法,部署jar包到数据库中,并以与任何其他Cypher函数相同的方式调用。
此示例显示如何从Cypher调用名为join的用户定义函数。
MATCH (n:Member)
RETURN org.neo4j.function.example.join(collect(n.name)) AS members
用户定义的聚合函数使用Java编写,部署到数据库中,并以与任何其他Cypher函数相同的方式调用。
此示例显示如何从Cypher调用名为longestString的用户定义聚合函数。
MATCH (n:Member)
RETURN org.neo4j.function.example.longestString(n.name) AS member
6 模式
6.1 索引
6.1.1 创建单一索引
CREATE INDEX ON :Label(property)
CREATE INDEX ON :Person(firstname)
6.1.2 创建复合索引
CREATE INDEX ON :Person(age, country)
6.1.3 删除索引
CALL db.indexes //查看对应索引
DROP INDEX ON :Person(firstname)
DROP INDEX ON :Person(age, country) //删除复合索引
MATCH (p:Person)
WHERE exists(p.firstname)
RETURN p
6.1.4 全文模式索引
索引和全文模式索引的区别在哪里,如何区分?
例如,solr的分词,就是全文索引的一种?倒排?
之前的常规模式索引只能对字符串进行精确匹配或者前后缀索引(startswith,endswith,contains),全文索引将标记化索引字符串值,因此它可以匹配字符串中任何位置的术语。索引字符串如何被标记化并分解为术语,取决于配置全文模式索引的分析器。
索引是通过属性来创建,便于快速查找节点或者关系。
创建和配置全文模式索引
使用db.index.fulltext.createNodeIndex和db.index.fulltext.createRelationshipIndex创建全文模式索引。在创建索引时,每个索引必须为每个索引指定一个唯一的名称,用于在查询或删除索引时引用相关的特定索引。然后,全文模式索引分别应用于标签列表或关系类型列表,分别用于节点和关系索引,然后应用于属性名称列表。
应用于多个标签或多个关系类型的索引称为多标记索引/多令牌索引。
db.index.fulltext.createNodeIndex and db.index.fulltext.createRelationshipIndex用于创建全文模式索引。
6.1.5 创建、配置与查询全文模式索引
CREATE (m:Movie { title: "The Matrix" })
RETURN m.title
CALL db.index.fulltext.createNodeIndex("titlesAndDescriptions",["Movie", "Book"],["title", "description"])
//创建了一个复合类型的全文索引之后,对其进行查询
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "matrix") YIELD node, score
RETURN node.title, node.description, score
//对关系创建对应的索引
CALL db.index.fulltext.createRelationshipIndex("taggedByRelationshipIndex",["TAGGED_AS"],["taggedByUser"], { analyzer: "url_or_email", eventually_consistent: "true" })
//对全文模式索引进行查询
除了完全匹配的结果之外,全文索引还会返回给定查询的近似匹配,lucence的查询,类似于搜索引擎的查询方式
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", "Full Metal Jacket") YIELD node, score
RETURN node.title, score
//返回值并不完全是精确匹配,将按照相关度降序排列。
完全精确匹配采用如下方式:
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", ""Full Metal Jacket"") YIELD node, score
RETURN node.title, score
使用与或的逻辑操作符
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", 'full AND metal') YIELD node, score
RETURN node.title, score
和对应的属性值进行匹配
CALL db.index.fulltext.queryNodes("titlesAndDescriptions", 'description:"surreal adventure"') YIELD node, score
RETURN node.title, node.description, score
6.2 限制
6.2.1 唯一性约束/主键约束
Create unique表示在创建时避免重复创建
Unique约束类似于数据库的第一范式,即主键约束的记录唯一性。
应该使用一些数据库约束来创建节点或关系的一个或多个属性的规则。
创建唯一性约束的语法:
CREATE CONSTRAINT ON (<label_name>)
ASSERT <property_name> IS UNIQUE
具体实例:
CREATE CONSTRAINT ON (cc:CreditCard)
ASSERT cc.number IS UNIQUE
6.2.2 删除唯一性约束
DROP CONSTRAINT ON (cc:CreditCard)
ASSERT cc.number IS UNIQUE
查看库中的限制:
CALL db.constraints
7 查询调优
7.1 Cypher查询选项
Cypher查询计划程序将每个查询转换为执行计划。 执行计划告诉Neo4j在执行查询时要执行哪些操作。
Neo4j使用基于成本的执行计划策略(称为“成本”计划程序):Neo4j中的统计服务用于为替代计划分配成本并选择最成本最低的计划。
Explain:仅查看执行计划但是并不运行该语句
PROFILE:概要。如果要运行语句并查看哪些运算符正在执行大部分工作,请使用PROFILE。这将运行您的语句并跟踪每个运算符传递的行数,以及每个运算符需要与存储层交互以检索必要数据的程度
7.2 基础查询调优示例
//导入电影的csv并且在导入时创建属性,且避免创建重复节点,实现幂等效果
LOAD CSV WITH HEADERS FROM 'file:///movies.csv' AS line
MERGE (m:Movie { title: line.title })
ON CREATE SET m.released = toInteger(line.released), m.tagline = line.tagline
LOAD CSV WITH HEADERS FROM 'file:///actors.csv' AS line
MATCH (m:Movie { title: line.title })
MERGE (p:Person { name: line.name })
ON CREATE SET p.born = toInteger(line.born)
MERGE (p)-[:ACTED_IN { roles:split(line.roles, ';')}]->(m)
LOAD CSV WITH HEADERS FROM 'file:///directors.csv' AS line
MATCH (m:Movie { title: line.title })
MERGE (p:Person { name: line.name })
ON CREATE SET p.born = toInteger(line.born)
MERGE (p)-[:DIRECTED]->(m)
此时需要寻找叫做Tom hanks的演员,
7.2.1 最初始的做法
MATCH (p { name: 'Tom Hanks' })
RETURN p
在之前加上profile来进行查询,可以查看查询计划

![]()
可见全表扫描,很低效的方法
7.2.2 加标签
PROFILE MATCH (p:Person { name: 'Tom Hanks' }) RETURN p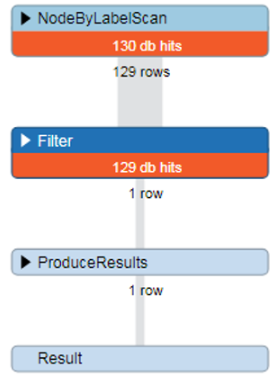
![]()
效率提高不少,整体的数据库命中数也减少了一半
NodeByLabelScan运算符指示我们通过首先对数据库中的所有Person节点进行线性扫描来实现此目的。
完成后我们再次使用Filter运算符扫描所有节点,比较每个节点的name属性。
在某些情况下这可能是可以接受的,但如果我们要经常按名称查找人员,那么如果我们在Person标签的name属性上创建索引,我们会看到更好的性能:
7.2.3 加索引

7.3 索引值与顺序
7.3.1 高级查询调优示例
CALL db.awaitIndexes
CALL db.indexes
//寻找Tom开头的演员出演的电影
//拥有索引支持的属性查找
PROFILE
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name STARTS WITH 'Tom'
RETURN p.name, count(m)
在neo4j3.5中,我们可以利用索引存储属性值的事实。在这种情况下,意味着可以直接从索引中查找名称,允许Cypher避免第二次扫库来查找属性。

根据上图可知neo4j缓存了对应的索引值。
改变查询语句,不再使用where的过滤语句。
PROFILE
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name, count(m)
此时不再使用索引缓存而是扫库机制
可以用于优化的过滤语句如下:
Existance (WHERE exists(n.name))
Equality (e.g. WHERE n.name = 'Tom Hanks')
Range (eg. WHERE n.uid > 1000 AND n.uid < 2000)
Prefix (eg. WHERE n.name STARTS WITH 'Tom')
Suffix (eg. WHERE n.name ENDS WITH 'Hanks')
Substring (eg. WHERE n.name CONTAINS 'a')
//索引支持的order by(优化语句)
//可见下左,在一开始的节点索引阶段就具备了
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name STARTS WITH 'Tom'
RETURN p.name, count(m)
ORDER BY p.name
//改变查询,换一种方式来使用索引
//可见下右,直到sort阶段才有order by的操作。
PROFILE
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
USING INDEX p:Person(name)
WHERE exists(p.name)
RETURN p.name, count(m)
ORDER BY p.name
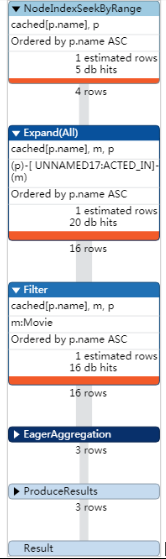
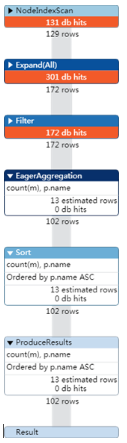
总结:对于排序order by而言,不能够使用exists来做优化
排序可使用的过滤语句如下:
Equality (e.g. WHERE n.name = 'Tom Hanks')
Range (eg. WHERE n.uid > 1000 AND n.uid < 2000)
Prefix (eg. WHERE n.name STARTS WITH 'Tom')
Suffix (eg. WHERE n.name ENDS WITH 'Hanks')
Substring (eg. WHERE n.name CONTAINS 'a')
7.4 计划程序提示与USING关键字
在为查询构建执行计划时,计划程序提示用于影响计划程序的决策,使用using关键字在查询中指定计划程序提示。
强制规划器行为是一项高级功能,会导致性能下降,应该谨慎使用。
8 执行计划
8.1 执行计划的操作符
8.2 最短路径规划
规划Cypher的最短路径可能会导致不同的查询计划,具体取决于需要评估的过滤条件。Neo4j默认使用快速双向广度优先搜索算法。
如果广搜未获得结果,neo4j可能不得不求助于较慢的穷举深度优先搜索算法来查找路径,
8.2.1 最短路径的快速算法
MATCH (ms:Person { name: 'Martin Sheen' }),(cs:Person { name: 'Charlie Sheen' }), p = shortestPath((ms)-[:ACTED_IN*]-(cs))
WHERE ALL (r IN relationships(p) WHERE exists(r.role))
RETURN p
8.2.2 较慢的深搜作为后续算法
MATCH (cs:Person { name: 'Charlie Sheen' }),(ms:Person { name: 'Martin Sheen' }), p = shortestPath((cs)-[*]-(ms))
WHERE length(p)> 1
RETURN p
更详尽的详尽查询计划的工作方式是使用Apply / Optional来确保当快速算法找不到任何结果时,生成空结果而不是简单地停止结果流。 除此之外,规划器将发出一个AntiConditionalApply,如果路径变量指向null而不是路径,它将运行穷举搜索。
在(i)cypher.forbid_exhaustive_shortestpath设置为true,以及(ii)快速算法无法找到最短路径的情况下,ErrorPlan运算符将出现在执行计划中。
8.2.3 阻止慢深搜作为后备
MATCH (cs:Person { name: 'Charlie Sheen' }),(ms:Person { name: 'Martin Sheen' }), p = shortestPath((cs)-[*]-(ms))
WITH p//with子句即意味着不包含深搜算法
WHERE length(p)> 1
RETURN p
原文地址:https://blog.csdn.net/weixin_42348333/article/details/89816699