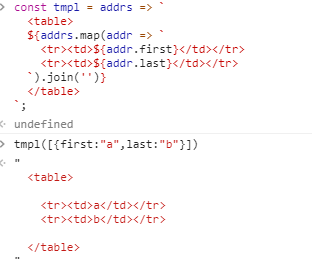
一、字符串
模版字符串:反引号(`)标识。
$('#result').append(`
There are <b>${basket.count}</b> items
in your basket, <em>${basket.onSale}</em>
are on sale!
`);
变量嵌入(定义变量,使用$ 获取):
// 字符串中嵌入变量
let name = "Bob", time = "today";
`Hello ${name}, how are you ${time}?`
使用任意表达式、调用函数
let x = 1;
let y = 2;
`${x} + ${y} = ${x + y}`
// "1 + 2 = 3"
`${x} + ${y * 2} = ${x + y * 2}`
// "1 + 4 = 5"
let obj = {x: 1, y: 2};
`${obj.x + obj.y}`
// "3"
标签模块:
在函数名后,该函数会处理此模块字符串
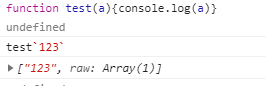
如果模版字符串含有变量,则会先执行模版字符串,在执行函数。
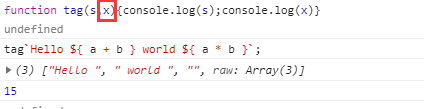
上面代码中,tag函数的第一个参数strings,有一个raw属性,也指向一个数组。该数组的成员与strings数组完全一致。比如,strings数组是["First line
Second line"],那么strings.raw数组就是["First line\nSecond line"]。两者唯一的区别,就是字符串里面的斜杠都被转义了。比如,strings.raw 数组会将
视为\和n两个字符,而不是换行符。这是为了方便取得转义之前的原始模板而设计的。
新增方法:
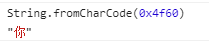
1.fromCodePoint:Unicode 码点返回对应字符

2.raw:该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
3.codePintAt:获取字符串的十进制码点
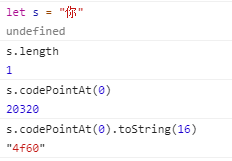
在获取码点的时候使用for..of,它会识别32位的UTF-16 字符。
4.normalize:语调
5.includes/startWith/endWith: 查找字符串

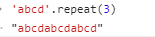
6.repeat:复制
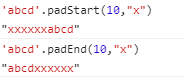
7.padStart/padEnd:补全(如果不设置补全字符,则默认补全空格)
8.trimStart/trimEnd:消除空格(另外还发现了trimLeft 与trimRight,它们是start和end 的别名)

二、正则
如果RegExp构造函数第一个参数是一个正则对象,那么可以使用第二个参数指定修饰符。而且,返回的正则表达式会忽略原有的正则表达式的修饰符,只使用新指定的修饰符。
1.字符串使用:match、matchAll、replace、search、split
2.u修饰符:针对utf-16编码的unicode字符会正确处理
3.点字符:“.” 字符代表除换行符以外的任意单个字符。
4.Unicode字符:大括号中的61为16进制表示
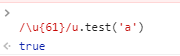
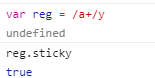
5.y修饰符:全局匹配(黏连)y修饰符会从上一个匹配的第一个位置开始匹配,而g修饰符只要保证剩余存在即可。
6.sticky:验证是否使用了y修饰符
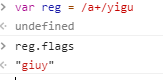
7.flags 属性:返回修饰符
8.dotAll:任意字符
2018新增s修饰符,表示“.”代表一切字符(包括换行符、回车符、分隔符)

9.具名组匹配(对组设置别名,使用group获取)
const RE_DATE = /(?<year>d{4})-(?<month>d{2})-(?<day>d{2})/; const matchObj = RE_DATE.exec('1999-12-31'); const year = matchObj.groups.year; // 1999 const month = matchObj.groups.month; // 12 const day = matchObj.groups.day; // 31
10.引用:使用K<组名>重复使用组
const RE_TWICE = /^(?<word>[a-z]+)!k<word>$/;
RE_TWICE.test('abc!abc') // true
RE_TWICE.test('abc!ab') // false
11.matchAll:返回匹配到的数组
const string = 'test1test2test3';
// g 修饰符加不加都可以
const regex = /t(e)(st(d?))/g;
for (const match of string.matchAll(regex)) {
console.log(match);
}
// ["test1", "e", "st1", "1", index: 0, input: "test1test2test3"]
// ["test2", "e", "st2", "2", index: 5, input: "test1test2test3"]
// ["test3", "e", "st3", "3", index: 10, input: "test1test2test3"]
三、数值
1.二进制/八进制表示法:0b/0o
如果要将0b和0o前缀的字符串数值转为十进制,要使用Number方法。
Number('0b111') // 7
Number('0o10') // 8
2.isFinite/isNaN:检查数字是否是无限或者是无效NaN,传统方法先调用Number()将非数值的值转为数值,再进行判断,而这两个新方法只对数值有效。
3.isInteger:判断是否为整数
4.EPSLION:根据规格,它表示 1 与大于 1 的最小浮点数之间的差。
Math扩展:
1.trunc:除去一个数的小数部分,返回整数
2.sign:判断数为正数、负数、0
它会返回五种值。
- 参数为正数,返回
+1; - 参数为负数,返回
-1; - 参数为 0,返回
0; - 参数为-0,返回
-0; - 其他值,返回
NaN。
3.cbrt:计算一个数的立方根

4.clz32:转换为32位整数,返回前导0的个数。
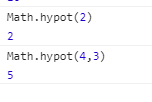
5.hypot:返回所有参数的平方和的平方根
6.指数运算符:** (多个指数运算从右开始计算)

**= 赋值运算符
let a = 1.5; a **= 2; // 等同于 a = a * a; let b = 4; b **= 3; // 等同于 b = b * b * b;
四、函数
1.函数参数默认值
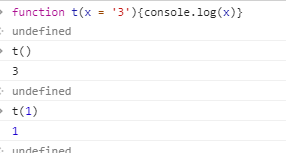
与解构赋值结合
function foo({x, y = 5}) {
console.log(x, y);
}
foo({}) // undefined 5
foo({x: 1}) // 1 5
foo({x: 1, y: 2}) // 1 2
foo() // TypeError: Cannot read property 'x' of undefined
在解构赋值的基础上追加默认值
function foo({x, y = 5} = {}) {
console.log(x, y);
}
作用域:不多表,对于默认值,看准其内部解构,另外默认值的参数会形成单独的作用域,如果默认值是函数的话,需看清是否是声明变量还是向上提升,亦或是let声明的。在此推荐使用let 声明(如果默认参数是函数的话)
2.rest参数:可变参数(真正的数组而argument是一个类似数组的对象),在其后不能再有其他参数
function add(...values) {
let sum = 0;
for (var val of values) {
sum += val;
}
return sum;
}
add(2, 5, 3) // 10
3.name属性:返回函数的name(如果使用表达式的方式声明一个函数,那么在es6中返回的是这个变量的名称,如果具名函数,则返回具名函数的名称)
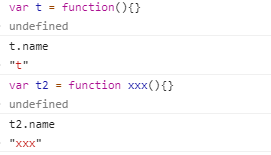
使用构造函数声明的function,那么为anonymous
使用bind 硬绑定的函数name属性会加上bound前缀~
function foo() {};
foo.bind({}).name // "bound foo"
(function(){}).bind({}).name // "bound "
4.箭头函数:=>
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分,
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号,否则会报错。
如果箭头函数只有一行语句,且不需要返回值:
let fn = () => void doesNotReturn();
简化回调(当只有一行代码的时候最明显):
// 正常函数写法
[1,2,3].map(function (x) {
return x * x;
});
// 箭头函数写法
[1,2,3].map(x => x * x);
箭头函数有几个使用注意点。
(1)函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。(内部作用域,个人理解与let相似,关于this之前文章中有提到)
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
关于this:具体涉及到作用域的问题,这里提到的是普通对象是没有内在作用域,但是函数有,所以在看阮一峰大神讲到这里的时候需要注意下。
关于嵌套(这里地方搞了我1个多小时),阮大神的一个例子:
const pipeline = (...funcs) => val => funcs.reduce((a, b) => b(a), val); const plus1 = a => a + 1; const mult2 = a => a * 2; const addThenMult = pipeline(plus1, mult2); addThenMult(5)
看的时候就懵逼了,翻译后如下:
var s = function(...funcs){function redu(a,b){return b(a)}; return function(val){ return funcs.reduce(redu,val) }}
var tt = s(function(a){return a+1},function(b){return b*2})
tt(3); // 8
回调函数套多了,容易懵。。 所以要记住 如果只有一行代码的箭头函数默认是return的。
5.尾调用:函数的最后一步调用另一个函数(需要return的,并且只是调用,没有其他操作才叫尾调用)
下面是引用:
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
尾递归:大家都知道如果操作不好很容易发生栈溢出。
阮大神的例子:
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120 首先上面有其他操作,也就是需要n相乘,所以不是尾调用
//改为尾递归:
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120 把操作丢到参数里,实现尾调用
柯里化:将多参数的函数转换成单参数的形式。(采用 ES6 的函数默认值)
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5) // 120
另外:ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
非严格模式:蹦床模式(名字不孬)
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
上面没有循环调用,而是执行一个新的函数。另外阮大神写了另一种方法通过状态,有兴趣的去翻翻。
!尾逗号:函数中的参数最后一个允许存在逗号!~ 不必每次修改代码的时候再在最后先加上,然后再写了~
function clownsEverywhere(
param1,
param2,
) { /* ... */ }
clownsEverywhere(
'foo',
'bar',
);
五、数组
1.扩展运算符 (可变) "..."(将一个数组变为参数序列)
个人认为需要注意的是,如果作为形参,在传入实参的时候,是可变参数,这点需要注意。
...[1,2,3] 和 ...[arr] ,面对arr 应该是可变长度参数,而不是一个数组。
适用例子:
push:arr1.push(...arr2);
Date:new Date(...[2015, 1, 1]);
复制数组:
// 写法一 const a2 = [...a1]; // 写法二 const [...a2] = a1;
合并数组:
[...arr1, ...arr2, ...arr3]
注意:虽然复制和合并数组(es5中通过concat)都是拷贝,但是也都是浅拷贝,如果数组中存储的是简单类型的数值(或者说基本类似),改变复制后的数组中的值不会对原数值产生影响,但是如果存储的是对象的话,会影响原来的数组中的值。(因为后面的拷贝是拷贝的对象引用,这点在使用扩展修饰符的时候同样适用)
对象数值:(修改后影响其他数组)
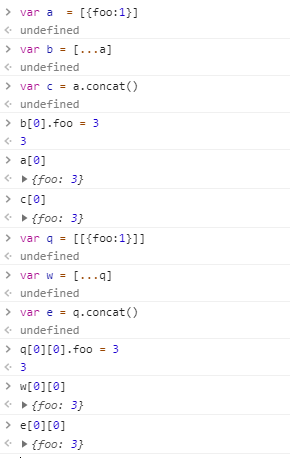
简单类型:(修改后不影响其他数组)

与解构赋值结合:
[a, ...rest] = list
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错
const [...butLast, last] = [1, 2, 3, 4, 5]; // 报错 const [first, ...middle, last] = [1, 2, 3, 4, 5]; // 报错
字符串(使用扩展运算符会正确失败unicode字符):
[...'hello'] // [ "h", "e", "l", "l", "o" ]
实现了 Iterator 接口的对象:任何定义了遍历器(Iterator)接口的对象(参阅 Iterator 一章),都可以用扩展运算符转为真正的数组。
let nodeList = document.querySelectorAll('div');
let array = [...nodeList];
Array.from:方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
};
// ES6的写法
let arr2 = Array.from(arrayLike); // ['a', 'b', 'c']
Array.from方法还支持类似数组的对象。所谓类似数组的对象,本质特征只有一点,即必须有length属性。因此,任何有length属性的对象,都可以通过Array.from方法转为数组,而此时扩展运算符就无法转换。
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
Array.from(arrayLike, x => x * x); // 等同于 Array.from(arrayLike).map(x => x * x);
如果map函数里面用到了this关键字,还可以传入Array.from的第三个参数,用来绑定this。
Array.of:Array.of方法用于将一组值,转换为数组。(跟from 区别:array.from 是类似数组的对象,而of中的参数是可变值)
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。

对比Array.of:
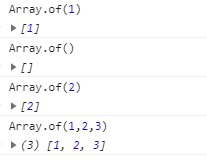
没有了歧义,参数是什么,数组就是什么,不会因为是一个数字而把它当成数组长度。
模拟:
function ArrayOf(){
return [].slice.call(arguments);
}
copyWithin: 在当前数组内部,将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组。
- target(必需):从该位置开始替换数据。如果为负值,表示倒数。
- start(可选):从该位置开始读取数据,默认为 0。如果为负值,表示倒数。
- end(可选):到该位置前停止读取数据,默认等于数组长度。如果为负值,表示倒数。

find/findIndex:找出复合条件的数据并返回,如果没有符合条件的成员,则返回undefined。/ findIndex 是返回下标,如果所有成员都不符合条件,则返回-1。

[1, 5, 10, 15].find(function(value, index, arr) {
return value > 9;
}) // 10
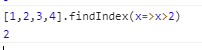
[1, 5, 10, 15].findIndex(function(value, index, arr) {
return value > 9;
}) // 2
这两个方法都可以接受第二个参数,用来绑定回调函数的this对象。(另外记住如果要绑定this对象,不能用箭头函数哦,之前说到了,这里再说一次)
function f(v){
return v > this.age;
}
let person = {name: 'John', age: 20};
[10, 12, 26, 15].find(f, person); // 26
fill:使用给定的值,填充数组

fill方法还可以接受第二个和第三个参数,用于指定填充的起始位置和结束位置。

注意,如果填充的类型为对象,那么被赋值的是同一个内存地址的对象,而不是深拷贝对象。(对象是引用)
let arr = new Array(3).fill({name: "Mike"});
arr[0].name = "Ben";
arr
// [{name: "Ben"}, {name: "Ben"}, {name: "Ben"}]
let arr = new Array(3).fill([]);
arr[0].push(5);
arr
// [[5], [5], [5]]
entries、keys、values:遍历数组(map 会很有用处)
for (let index of ['a', 'b'].keys()) {
console.log(index);
}
// 0
// 1
for (let elem of ['a', 'b'].values()) {
console.log(elem);
}
// 'a'
// 'b'
for (let [index, elem] of ['a', 'b'].entries()) {
console.log(index, elem);
}
// 0 "a"
// 1 "b"
上面是引用自阮大神的,如果是简单类型的值,那么keys 是下标、values是值、entries是以键值对(简单类型就是下标+值)
如果不使用for...of循环,可以手动调用遍历器对象的next方法,进行遍历。(因为数组实现了遍历器iterator)
let letter = ['a', 'b', 'c']; let entries = letter.entries(); console.log(entries.next().value); // [0, 'a'] console.log(entries.next().value); // [1, 'b'] console.log(entries.next().value); // [2, 'c']
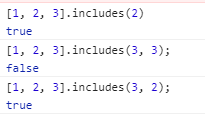
includes:(之前的string扩展也有includes 方法哦,返回布尔型)返回布尔型,表示某个数组是否包含给定的值。
该方法的第二个参数表示搜索的起始位置,默认为0。如果第二个参数为负数,则表示倒数的位置,如果这时它大于数组长度(比如第二个参数为-4,但数组长度为3),则会重置为从0开始。
另外,Map 和 Set 数据结构有一个has方法,需要注意与includes区分。
- Map 结构的
has方法,是用来查找键名的,比如Map.prototype.has(key)、WeakMap.prototype.has(key)、Reflect.has(target, propertyKey)。 - Set 结构的
has方法,是用来查找值的,比如Set.prototype.has(value)、WeakSet.prototype.has(value)。
flat/flatMap:这个方法非常好用,个人觉得~ 如果有嵌套数组,那么会把数组“拉平”(阮大神文采),变成一堆数组。(记得升级浏览器哦)
[1, 2, [3, 4]].flat() // [1, 2, 3, 4]
flat()默认只会“拉平”一层,如果想要“拉平”多层的嵌套数组,可以将flat()方法的参数写成一个整数,表示想要拉平的层数,默认为1。
[1, 2, [3, [4, 5]]].flat() // [1, 2, 3, [4, 5]] [1, 2, [3, [4, 5]]].flat(2) // [1, 2, 3, 4, 5]
如果不管有多少层嵌套,都要转成一维数组,可以用Infinity(终于看到它发挥作用的一天了)关键字作为参数。
[1, [2, [3]]].flat(Infinity) // [1, 2, 3]
flatMap()方法对原数组的每个成员执行一个函数(相当于执行Array.prototype.map()),然后对返回值组成的数组执行flat()方法。该方法返回一个新数组,不改变原数组。
// 相当于 [[2, 4], [3, 6], [4, 8]].flat() [2, 3, 4].flatMap((x) => [x, x * 2]) // [2, 4, 3, 6, 4, 8]
上面代码中,遍历函数返回的是一个双层的数组,但是默认只能展开一层,因此flatMap()返回的还是一个嵌套数组(但是可以多执行一次flat~)。

flatMap()方法还可以有第二个参数,用来绑定遍历函数里面的this。
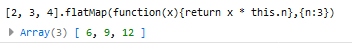
空位:数组的空位不是undefined,注意,空位不是undefined,一个位置的值等于undefined,依然是有值的。空位是没有任何值,in运算符可以说明这一点。
0 in [undefined, undefined, undefined] // true 0 in [, , ,] // false
ES6 则是明确将空位转为undefined。
Array.from方法会将数组的空位,转为undefined,也就是说,这个方法不会忽略空位。
Array.from(['a',,'b']) // [ "a", undefined, "b" ]
扩展运算符(...)也会将空位转为undefined。
[...['a',,'b']] // [ "a", undefined, "b" ]
copyWithin()会连空位一起拷贝。
[,'a','b',,].copyWithin(2,0) // [,"a",,"a"]
fill()会将空位视为正常的数组位置
new Array(3).fill('a') // ["a","a","a"]
for...of循环也会遍历空位。
let arr = [, ,];
for (let i of arr) {
console.log(1);
}
// 1
// 1
最后是阮大神的话:由于空位的处理规则非常不统一,所以建议避免出现空位(避免通过new Array(N)这种方式创建数组改由Array.of或者new Array().fill(1) 也可以~)
六、对象(JavaScript处处皆对象~)
简洁表示:ES6 允许在对象之中,直接写变量。这时,属性名为变量名, 属性值为变量的值。
const foo = 'bar';
const baz = {foo};
baz // {foo: "bar"}
// 等同于
const baz = {foo: foo};

对方方法简写:
const o = {
method() {
return "Hello!";
}
};
// 等同于
const o = {
method: function() {
return "Hello!";
}
};
属性的赋值器:
const cart = {
_wheels: 4,
get wheels () {
return this._wheels;
},
set wheels (value) {
if (value < this._wheels) {
throw new Error('数值太小了!');
}
this._wheels = value;
}
}
如果某个方法的值是一个 Generator 函数,前面需要加上星号:
const obj = {
* m() {
yield 'hello world';
}
};
属性名表达式:
// 方法一 obj.foo = true; // 方法二 obj['a' + 'bc'] = 123;
允许字面量定义对象:
let propKey = 'foo';
let obj = {
[propKey]: true,
['a' + 'bc']: 123
};
获取属性值的时候,也可以直接通过变量名获取(不带引号)
let lastWord = 'last word';
const a = {
'first word': 'hello',
[lastWord]: 'world'
};
a['first word'] // "hello"
a[lastWord] // "world"
a['last word'] // "world"
属性名表达式与简洁表示法,不能同时使用,会报错
属性名表达式如果是一个对象,默认情况下会自动将对象转为字符串[object Object]。
方法name属性:对象中的函数同时具有name属性。
关于可枚举与遍历:操作中引入继承的属性会让问题复杂化,大多数时候,我们只关心对象自身的属性。所以,尽量不要用for...in循环,而用Object.keys()代替。
关于Object.assign(): 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象(会改变目标对象)。
深拷贝:
// Deep Clone
obj1 = { a: 0 , b: { c: 0}};
let obj3 = JSON.parse(JSON.stringify(obj1));
obj1.a = 4;
obj1.b.c = 4;
console.log(JSON.stringify(obj3)); // { a: 0, b: { c: 0}}
原始类型会被包装为对象(继承属性和不可枚举属性是不能拷贝的):
const v1 = "abc";
const v2 = true;
const v3 = 10;
const v4 = Symbol("foo")
const obj = Object.assign({}, v1, null, v2, undefined, v3, v4);
// 原始类型会被包装,null 和 undefined 会被忽略。
// 注意,只有字符串的包装对象才可能有自身可枚举属性。
console.log(obj); // { "0": "a", "1": "b", "2": "c" }
属性的遍历:
1)for...in
for...in循环遍历对象自身的和继承的可枚举属性(不含 Symbol 属性)。
(2)Object.keys(obj)
Object.keys返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含 Symbol 属性)的键名。
(3)Object.getOwnPropertyNames(obj)
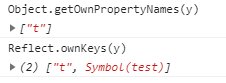
Object.getOwnPropertyNames返回一个数组,包含对象自身的所有属性(不含 Symbol 属性,但是包括不可枚举属性)的键名。
Object.getOwnPropertyNames(y) ["t"]
(4)Object.getOwnPropertySymbols(obj)
Object.getOwnPropertySymbols返回一个数组,包含对象自身的所有 Symbol 属性的键名。
let y = {[Symbol("test")]:123,t:456}
Object.getOwnPropertySymbols(y)
//[Symbol(test)]
(5)Reflect.ownKeys(obj)
Reflect.ownKeys返回一个数组,包含对象自身的所有键名,不管键名是 Symbol 或字符串,也不管是否可枚举。
super 关键字:指向当前对象的原型对象
对象的解构赋值:
let { x, y, ...z } = { x: 1, y: 2, a: 3, b: 4 };
x // 1
y // 2
z // { a: 3, b: 4 }
扩展运算符的解构赋值,不能复制继承自原型对象的属性:
let o1 = { a: 1 };
let o2 = { b: 2 };
o2.__proto__ = o1;
let { ...o3 } = o2;
o3 // { b: 2 }
o3.a // undefined

阮大神的引用:
const o = Object.create({ x: 1, y: 2 });
o.z = 3;
let { x, ...newObj } = o;
let { y, z } = newObj;
x // 1
y // undefined
z // 3
结果不一样,阮大神这样说上面一段代码:
上面代码中,变量x是单纯的解构赋值,所以可以读取对象o继承的属性;变量y和z是扩展运算符的解构赋值,只能读取对象o自身的属性,所以变量z可以赋值成功,变量y取不到值。ES6 规定,变量声明语句之中,如果使用解构赋值,扩展运算符后面必须是一个变量名,而不能是一个解构赋值表达式,所以上面代码引入了中间变量newObj,如果写成下面这样会报错

不同之处在哪呢? 在于Object.create 方法,之前说到扩展运算符的解构赋值,不能复制继承自原型对象的属性,
所以,...w 只能查找到对象本身的属性。

对象o原型链

Objcet.create()方法:创建一个新对象(使用现有的对象来提供新创建的对象的__proto__)
创建一个空对象:所以Object.create(null) 是创建一个真正意义上的空对象。

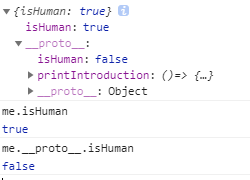
const person = {
isHuman: false,
printIntroduction: function () {
console.log(`My name is ${this.name}. Am I human? ${this.isHuman}`);
}
};
const me = Object.create(person);
me.name = "Matthew"; // "name" is a property set on "me", but not on "person"(那么属性只属性me对象而不属于person)
me.isHuman = true; // inherited properties can be overwritten (继承的属性可以被重写)
me.printIntroduction();
isHuman 等于是在自身,也就是顶层,但是继承的属性依然存在。
包涵函数:
function baseFunction({ a, b }) {
// ...
}
function wrapperFunction({ x, y, ...restConfig }) {
// 使用 x 和 y 参数进行操作
// 其余参数传给原始函数
return baseFunction(restConfig);
}
对象的扩展运算符:
let z = { a: 3, b: 4 };
let n = { ...z };
n // { a: 3, b: 4 }
// 数组转对象
let foo = { ...['a', 'b', 'c'] };
foo
// {0: "a", 1: "b", 2: "c"}如果扩展运算符后面是字符串,它会自动转成一个类似数组的对象,因此返回的不是空对象
{...'hello'}
// {0: "h", 1: "e", 2: "l", 3: "l", 4: "o"}
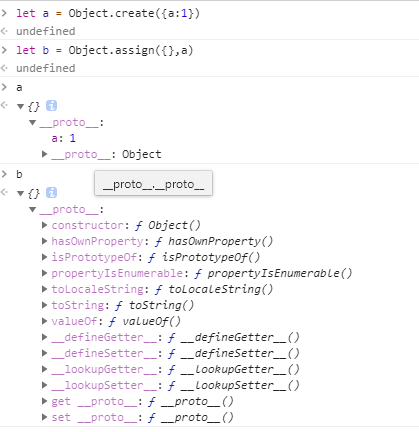
(有时候)对象的扩展运算符类似assign方法:
let aClone = { ...a };
// 等同于
let aClone = Object.assign({}, a);
上面的例子不会赋值继承的属性,完整克隆一个对象,还需要拷贝对象原型的属性:
下面是阮大神提供的方法:
// 写法一
const clone1 = {
__proto__: Object.getPrototypeOf(obj),
...obj
};
// 写法二
const clone2 = Object.assign(
Object.create(Object.getPrototypeOf(obj)), // 创建一个obj作为原型的对象,然后给这个对象作为目标对象,把obj再作为源对象,把其实例属性复制到这个对象上~
obj
);
// 写法三
const clone3 = Object.create(
Object.getPrototypeOf(obj),
Object.getOwnPropertyDescriptors(obj)
)
推荐使用写法二、三(__proto__属性在非浏览器的环境不一定部署)
合并两个对象:
let ab = { ...a, ...b };
// 等同于
let ab = Object.assign({}, a, b);
修改现有对象部分的属性:
let newVersion = {
...previousVersion,
name: 'New Name' // Override the name property
};
扩展运算符后面可以跟表达式:
const obj = {
...(x > 1 ? {a: 1} : {}),
b: 2,
};
对象新增方法:
相等运算符(==)和严格相等运算符(===)。它们都有缺点,前者会自动转换数据类型,后者的NaN不等于自身,以及+0等于-0。
Object.is:它用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致。
Object.is('foo', 'foo')
// true
Object.is({}, {})
// false
+0 === -0 //true NaN === NaN // false Object.is(+0, -0) // false Object.is(NaN, NaN) // true
pollfill:
Object.defineProperty(Object, 'is', {
value: function(x, y) {
if (x === y) {
// 针对+0 不等于 -0的情况
return x !== 0 || 1 / x === 1 / y;
}
// 针对NaN的情况
return x !== x && y !== y;
},
configurable: true,
enumerable: false,
writable: true
});
Object.assign:上面提到过,用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target)
拷贝的属性是有限制的,只拷贝源对象的自身属性(不拷贝继承属性),也不拷贝不可枚举的属性(enumerable: false)。
Object.assign可以用来处理数组,但是会把数组视为对象(数组转换为对象)下面的例子就类似于Object.assign({0:1,1:2,2:3},{0:4,1:5}):
Object.assign([1, 2, 3], [4, 5]) // [4, 5, 3]
取值函数的处理:
Object.assign只能进行值的复制,如果要复制的值是一个取值函数,那么将求值后再复制。
const source = {
get foo() { return 1 }
};
const target = {};
Object.assign(target, source)
// { foo: 1 }
添加方法(好用):
Object.assign(SomeClass.prototype, {
someMethod(arg1, arg2) {
···
},
anotherMethod() {
···
}
});
// 等同于下面的写法
SomeClass.prototype.someMethod = function (arg1, arg2) {
···
};
SomeClass.prototype.anotherMethod = function () {
···
};
克隆对象:
function clone(origin) {
return Object.assign({}, origin);
}
保持继承链:
function clone(origin) {
let originProto = Object.getPrototypeOf(origin);
return Object.assign(Object.create(originProto), origin);
}
合并多个对象:
const merge = (target, ...sources) => Object.assign(target, ...sources);
指定默认值:
const DEFAULTS = {
logLevel: 0,
outputFormat: 'html'
};
function processContent(options) {
options = Object.assign({}, DEFAULTS, options);
console.log(options);
// ...
}
Object.getOwnPropertyDescriptors:返回指定对象所有自身属性(非继承属性)的描述对象.
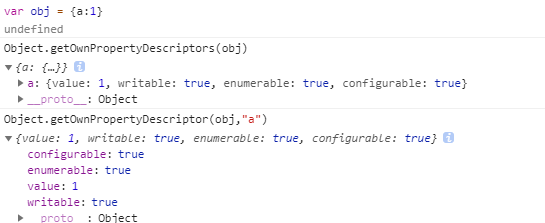
Object.assign方法总是拷贝一个属性的值,而不会拷贝它背后的赋值方法或取值方法。
Object.getOwnPropertyDescriptor():方法会返回某个对象属性的描述对象(是个对象哦)。
配合Object.create()方法,将对象属性克隆到一个新对象。这属于浅拷贝。
const clone = Object.create(Object.getPrototypeOf(obj), Object.getOwnPropertyDescriptors(obj)); // 或者 const shallowClone = (obj) => Object.create( Object.getPrototypeOf(obj), Object.getOwnPropertyDescriptors(obj) );
实现一个对象继承另一个对象:
const obj = Object.create(
prot,
Object.getOwnPropertyDescriptors({
foo: 123,
})
);
实现 Mixin(混入)模式:
let mix = (object) => ({
with: (...mixins) => mixins.reduce(
(c, mixin) => Object.create(
c, Object.getOwnPropertyDescriptors(mixin)
), object)
});
// multiple mixins example
let a = {a: 'a'};
let b = {b: 'b'};
let c = {c: 'c'};
let d = mix(c).with(a, b);
d.c // "c"
d.b // "b"
d.a // "a"
上面的代码流程是这样:首先获取混入对象mixobj ,然后调用对象的方法with,with 传入一组对象参数,返回通过reduce计算后的值(其中复合对象每次循环执行会把新对象的属性描述对象记入目标对象中),这样最后获取一个新对象并且拥有所有对象参数的属性。
__proto__ 属性、Object.setPrototypeOf()、Object.setPrototypeOf():
对象继承是通过原型链实现的。ES6 提供了更多原型对象的操作方法。
__proto__属性(前后各两个下划线),用来读取或设置当前对象的prototype对象。
// es6 的写法
var obj = Object.create(someOtherObj);
obj.method = function() { ... };
该属性没有写入 ES6 的正文,而是写入了附录,原因是__proto__前后的双下划线,说明它本质上是一个内部属性,而不是一个正式的对外的 API,只是由于浏览器广泛支持,才被加入了 ES6。标准明确规定,只有浏览器必须部署这个属性,其他运行环境不一定需要部署,而且新的代码最好认为这个属性是不存在的。因此,无论从语义的角度,还是从兼容性的角度,都不要使用这个属性,而是使用下面的Object.setPrototypeOf()(写操作)、Object.getPrototypeOf()(读操作)、Object.create()(生成操作)代替。(实现上,__proto__调用的是Object.prototype.__proto__)
Object.setPrototypeOf : Object.setPrototypeOf方法的作用与__proto__相同,用来设置一个对象的prototype对象,返回参数对象本身。它是 ES6 正式推荐的设置原型对象的方法。
// 格式
Object.setPrototypeOf(object, prototype)
// 用法
const o = Object.setPrototypeOf({}, null);
function setPrototypeOf(obj, proto) {
obj.__proto__ = proto;
return obj;
}
下面:
let proto = {};
let obj = { x: 10 };
Object.setPrototypeOf(obj, proto);
proto.y = 20;
proto.z = 40;
obj.x // 10
obj.y // 20
obj.z // 40
打印出来看一下:所以,继承性由此能够看出来,y/z 属性。

如果第一个参数不是对象,会自动转为对象。但是由于返回的还是第一个参数,所以这个操作不会产生任何效果:
Object.setPrototypeOf(1, {}) === 1 // true
Object.setPrototypeOf('foo', {}) === 'foo' // true
Object.setPrototypeOf(true, {}) === true // true
Object.getPrototypeOf(): 与setPrototypeOf 配套~

Object.keys()、Object.values()、Object.entries():
Object.keys配套的Object.values和Object.entries,作为遍历一个对象的补充手段,供for...of循环使用。
// 神来之笔哦,方便多了不用加Object了不是么~
let {keys, values, entries} = Object; let obj = { a: 1, b: 2, c: 3 }; for (let key of keys(obj)) { console.log(key); // 'a', 'b', 'c' } for (let value of values(obj)) { console.log(value); // 1, 2, 3 } for (let [key, value] of entries(obj)) { console.log([key, value]); // ['a', 1], ['b', 2], ['c', 3] }
Object.values方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值。

过滤属性名为 Symbol 值的属性:
Object.values({ [Symbol()]: 123, foo: 'abc' });
如果参数不是对象,Object.values会先将其转为对象。由于数值和布尔值的包装对象,都不会为实例添加非继承的属性。所以,Object.values会返回空数组。
Object.entries()方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值对数组(有点类似map,但是又不是map哦)。
Object.entries的基本用途是遍历对象的属性:
let obj = { one: 1, two: 2 };
for (let [k, v] of Object.entries(obj)) {
console.log(
`${JSON.stringify(k)}: ${JSON.stringify(v)}`
);
}
// "one": 1
// "two": 2
转换为MAP:将对象转为真正的Map结构。
const obj = { foo: 'bar', baz: 42 };
const map = new Map(Object.entries(obj));
map // Map { foo: "bar", baz: 42 }
Object.fromEntries():Object.entries()的逆操作,用于将一个键值对数组转为对象。
Object.fromEntries([
['foo', 'bar'],
['baz', 42]
])
// { foo: "bar", baz: 42 }
Map还原为对象:
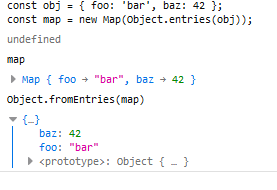
// 例二
const map = new Map().set('foo', true).set('bar', false);
Object.fromEntries(map)
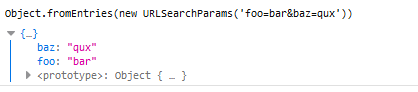
配合URLSearchParams对象,将查询字符串转为对象(实用):