1、编码
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。解决思路:数字与符号建立一对一映射,用不同数字表示不同符号。
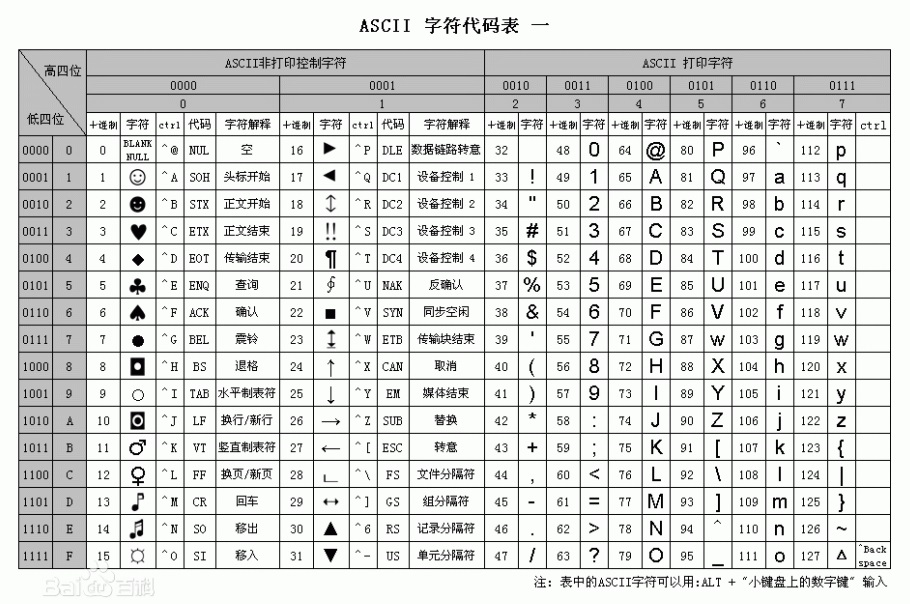
ASCII(American Standard Code for Information Interchange, 美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用指定的7位或8位二进制数组合来表示128 或256种可能的字符
大小规则
1) 数字0-9比字母要小, 如"7" < "F";
2) 数字0比数字9要小,并按0到9顺序递增, 如"3" <"8";
3) 字母A比字母Z要小,并按A到Z顺序递增, 如"A" < "Z";
4) 同个字母的大写字母比小写字母要小,如 "A" <" a";
常用ASCII 十进制 "0" = 48、"A"= 65、"a"= 97
中文编码
8为的ASCII能表示的最大整数255,也就是大小写英文字母、数字和一些符号。如果要表示更大的整数,就必须用更多的字节,如两个字节。
为了处理汉字,中国设计了用于简体中文的GB2312和用于繁体中文的big5
发展过程 GB2312(7445个字符) -- GBK(21886个字符) -- GB18030(27484个字符),属于双字节字符集
Windows缺省内码GBK
万国码
Unicode(统一码、万国码、单一码)为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定最少由16位(2个字节)。Python3支持Unicode编码
UTF-8
如果文本全是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
Unicode编码优化压缩为UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,
ASCII码中的内容用1个字节保存
欧洲的字符用2个字节保存
东亚的字符用3个字节保存
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | -- | 01001110 00101101 | 11100100 10111000 10101101 |
在UTF-8编码中,ASCII编码实际上可以被看成是UTF-8编码的一部分。所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
2、注释
Python中单行注释以 # 开头,多行注释置于'''......'''之间
|
#! /usr/bin/env python3 ''' 我是多行注释 我是多行注释 ''' print("Hello word!") # 我是单行注释 |
3、行与缩进
Python最具特色的就是使用缩进来表示代码块,不需要使用大括号{}
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数
|
if True: print ("True") else: print ("False") |