抓取智联招聘
一、 项目需求
1. 爬取智联招聘有关于“房地产销售”关键字的岗位信息,包括公司名称、招聘岗位、薪资和公司地址。(此处的关键字其实还可以更灵活的设置,如果直接是房地产销售就把程序写死了,这个程序只能抓取房地产销售岗位的信息,我们可以通过观察分析URL地址来推理设计出更灵活的程序,比如可以灵活的根据输入的关键字和工作地点来动态生成一个URL,具体的操作后面再详细阐述)
2. 使用请求库:requests
3. 使用解析库:pyquery
4. 使用CSV储存数据
二、 项目分析
用浏览器打开智联招聘官网,搜索关键字“房地产销售”,获取目标URL:
https://sou.zhaopin.com/jobs/searchresult.ashx?jl=广州&kw=房地产销售&sg=11dd585aae0f4afdbcf9150b215cc8ba&p=1
(注:如果图片看不清楚请右键点击图片通过新的标签打开)
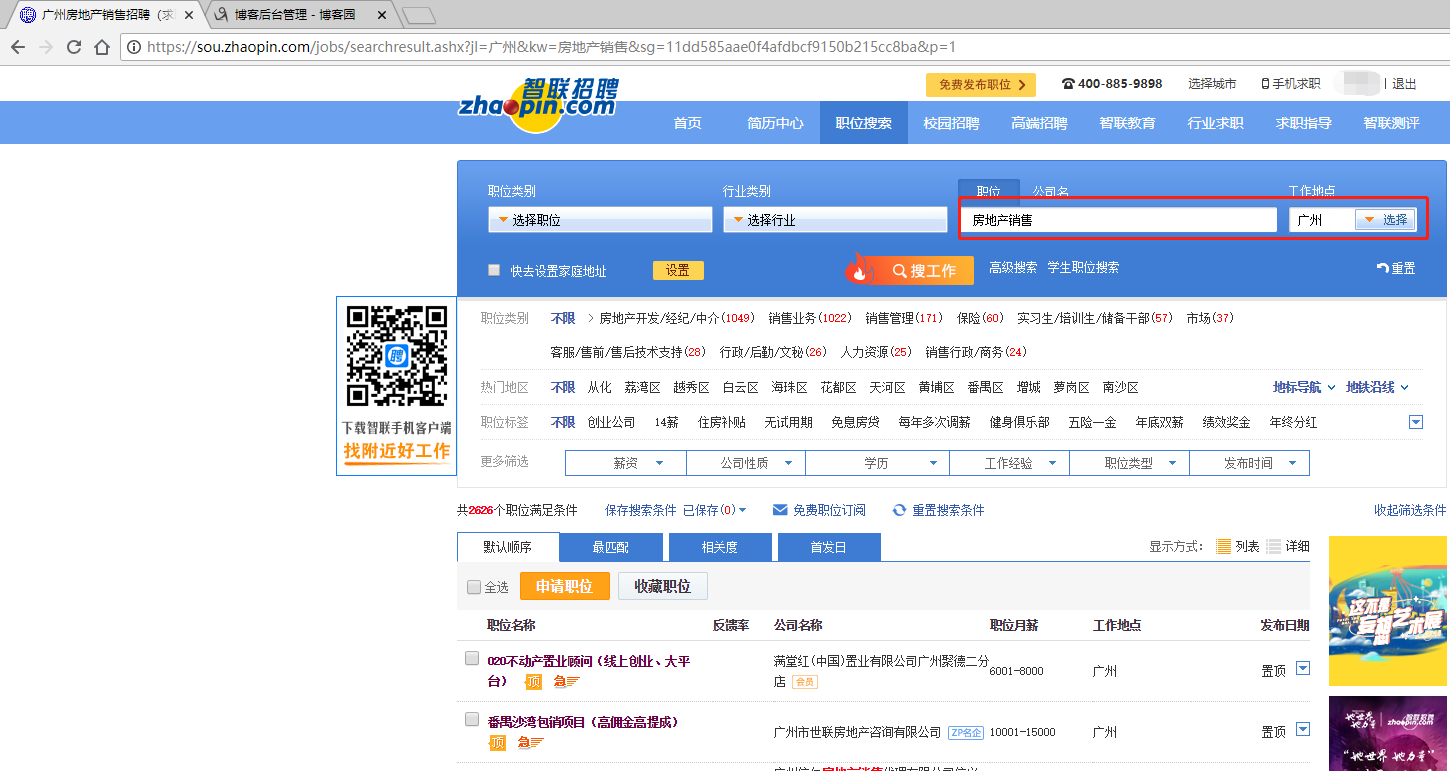
这里拿到了一个URL,其中里面包含了我们看不懂的参数,比如说sg参数,然而此时可以简单粗暴的将这个参数删除,即直接访问:
https://sou.zhaopin.com/jobs/searchresult.ashx?jl=广州&kw=房地产销售&p=1 这个URL,发现结果跟前面截图的一模一样,也就可以推测,sg参数应该是给机器看的,对我们的抓取没有影响,也就是可以忽略。
对于URL的其他参数估计不正常的人都能秒懂了,jl参数代表地址,kw参数就是keyword,而p参数就是当前所在的第几页。完了以后接下来就是构造请求URL了:
from urllib import parse url_params = { 'jl':'广州', 'kw':'房地产销售', 'p':1 } url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + parse.urlencode(url_params)
接下来就该设置请求头了,请求头最重要的信息其实就是 User-Agent 了,因为有些网站有反爬机制,如果我们直接通过 requests 库向一个URL发起请求时,此时默认的User-Agent为python-requests/2.10.0,这样就很容易被识别为爬虫因而被拒绝访问。
from requests headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36' } requests.get(url=url,headers=headers)
然而这里就可以抓取到上面截图的页面源码了,接下来要做的就是从源码里面提取我们需要的信息,包括公司名称、招聘岗位、薪资和公司地址。
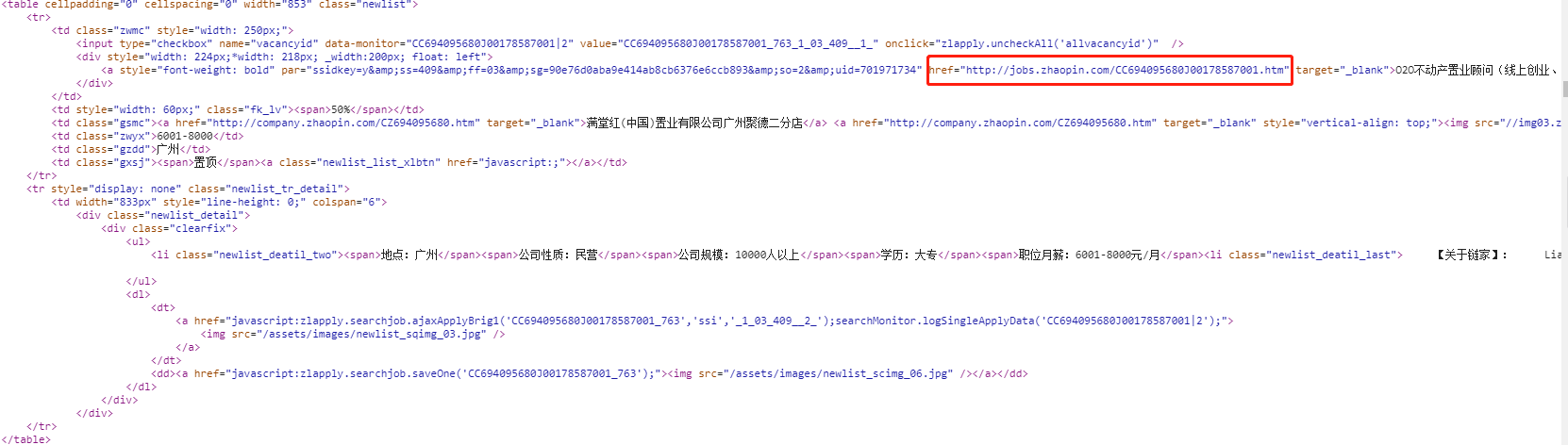
分析发现,每条记录都被以一个class属性为newlist的table标签包裹着,但是我们需要的信息在这里并没有完全包含,缺少了公司的详细地址和工作岗位,所以抓取到这个页面还不足以完成需求,然而再分析发现,每个table下都有一个a元素,它的href属性就是这条记录链接,点开这个链接就可以看到这个公司详细的招聘信息了:

分析发现,我们需要的公司名称就在class属性为inner-left和fl的div元素下的第一个h2元素下的a元素的文本内容;月薪在class属性为terminalpage-left的div元素下的第一个li元素里面的strong元素的文本;招聘岗位信息在最后一个li下的a元素的文本;工作地点在class属性为tab-inner-cont的div元素下的h2元素的文本,当然,这里面的a元素也有文本内容,所以在这里需要将a元素的文本内容排除掉(详细看后面源码)。
三、 项目源码
import requests from pyquery import PyQuery as pq import re import csv from urllib import parse from tqdm import tqdm from requests.exceptions import RequestException def get_one_page(url): """获取一个网页,参数url在主函数构造,防止程序出错还捕捉了RequestException异常""" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/67.0.3396.62 Safari/537.36' } try: response = requests.get(url=url,headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None def parse_one_page(html): """解析一个网页,获取一个页面中所有公司的url链接,并将这些链接储存在列表中,最后返回这个列表""" document = pq(html) url_list = [] a_list = document('.zwmc a:first') for item in a_list.items(): url_list.append(item.attr('href')) if url_list: return url_list def parse_one_company(url_list): """生成器函数,使用pyquery解析库提取我们需要的信息""" pattern = re.compile('(.*?) .*?') for url in url_list: html = get_one_page(url) document = pq(html) company_name = document('.inner-left.fl h2').text() salary = document('.terminalpage-left li:first strong').text() position = document('.terminalpage-left li:eq(7) strong').text() address = document('.tab-inner-cont h2').text() address = re.findall(pattern,address) if not address: address = '地址信息为空' else: address = address[0] yield { 'company_name':company_name, 'salary':salary, 'position':position, 'address':address } def write_with_csv(content): """将数据写入csv文件中,注意如果数据存在中文必须指定编码格式""" with open('data.csv','a',encoding='utf-8') as csvfile: fieldnames = ['company_name','salary','position','address'] writer = csv.DictWriter(csvfile,fieldnames=fieldnames) writer.writerow(content) def main(city,keyword,page): """主函数,动态生成url,调用以上所有函数实现数据抓取,分析及储存功能""" url_params = { 'jl':city, 'kw':keyword, 'p':page } url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + parse.urlencode(url_params) html = get_one_page(url) if html: url_list = parse_one_page(html) items = parse_one_company(url_list) for item in items: write_with_csv(item) if __name__ == '__main__': # tqdm模块用于显示进度 for i in tqdm(range(1,11)): main('广州','房地产销售',i)