prometheus监控(小试牛刀)
环境:全部服务都是基于docker运行
本文略微草率,好文章在这里,特别好如下:
https://www.cnblogs.com/tchua/p/11120228.html
- 整体环境思路:
注意:每一个操作建议结合情况使用,文章里的也会有很多错误,只是给一个思路方便理解
-
prometheus通过node-exporter收集当前主机运行的情况,因为本环境所有都使用的容器,所以对于node-exporter来说我们要将对应的目录进行映射,因为node-exporter是跑在容器里,但是我们要让他监控的是宿主机的各个状态
-
接着,部署grafana,它是从prometheus收集到的现成的数据,做一个合理的前端展示,它有丰富的模板,兼容性也很好
-
继续,我们部署了cadvisor容器服务.CAdvisor是Google开源的一款用于展示和分析容器运行状态的可视化工具。通过在主机上运行CAdvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图表的形式向用户展示。
-
再然后,部署了alertmanager容器服务,使之映射在主机的9093端口;prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向alertmanager发送告警信号,alertmanager收到告警信号之后,发送给相应的接受者(已经在配置文件定义好的)
docker pull prom/prometheus
#拉取prometheus镜像
docker pull prom/node-exporter
#拉取node-exporter镜像
docker pull grafana/grafana
#拉取grafana镜像
cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
#prometheus运行端口
- job_name: 'linux'
static_configs:
- targets: ['172.21.71.50:9100']
#node节点端口
labels:
instance: node
运行容器
$ docker run -d
> --net="host"
> --pid="host"
> -v "/:/host:ro,rslave"
> prom/node-exporter
> --path.rootfs /host
#运行node-exporter,这个比较特殊,在不是特别了解之前,先这样操作着
$ sudo docker run -d
-p 9090:9090
-v /usr/local/prometheus/file/prometheus.yml:/usr/local/prometheus/file/prometheus.yml
prom/prometheus
--config.file=/usr/local/prometheus/file/prometheus.yml --web.enable-lifecycle
#运行prometheus容器
$ git clone https://github.com/grafana/piechart-panel.git
#饼图插件
$ docker run -d --name=grafana -v /usr/local/prometheus/grafana/plugin/:/var/lib/grafana/plugins/ -p 3333:3000 grafana/grafana
#运行grafana,grafana的默认账号密码是admin/admin
- Prometheus监控docker容器运行状态,我们用到cadvisor服务,cadvisor我们这里也采用docker方式直接运行。
下载镜像
$ docker pull google/cadvisor
运行
cadvisor我们需要运行在docker宿主机上(与node_exporter类似),然后通过HTTP方式供Prometheus获取数据
$ docker run
--volume=/:/roos:ro
--volume=/var/run:/var/run:rw
--volume=/sys:/sys:ro
--volume=/var/lib/docker/:/var/lib/docker:ro
--publish=9101:8080
--detach=true
--name=cadvisor
google/cadvisor:latest
#这个cadvisor也是比较特殊,在你不是很熟悉它之前,按照我的操作做下去
注意:这里是把容器8080端口映射到主机9101,cadvisor有web界面地址:http://IP:9101
接入Grafana展示容器监控数据
这里我们去Grafana官网,找别人做好的Dashboard模板,地址:https://grafana.com/dashboards/4170,下载模板json文件然后导入本地Grafana。关于导入Dashbozrd模板参考https://www.cnblogs.com/tchua/p/11115146.html
接下来进行的操作是修改下该模板文件的一个变量,因为它本来是为cadvisor定做的;
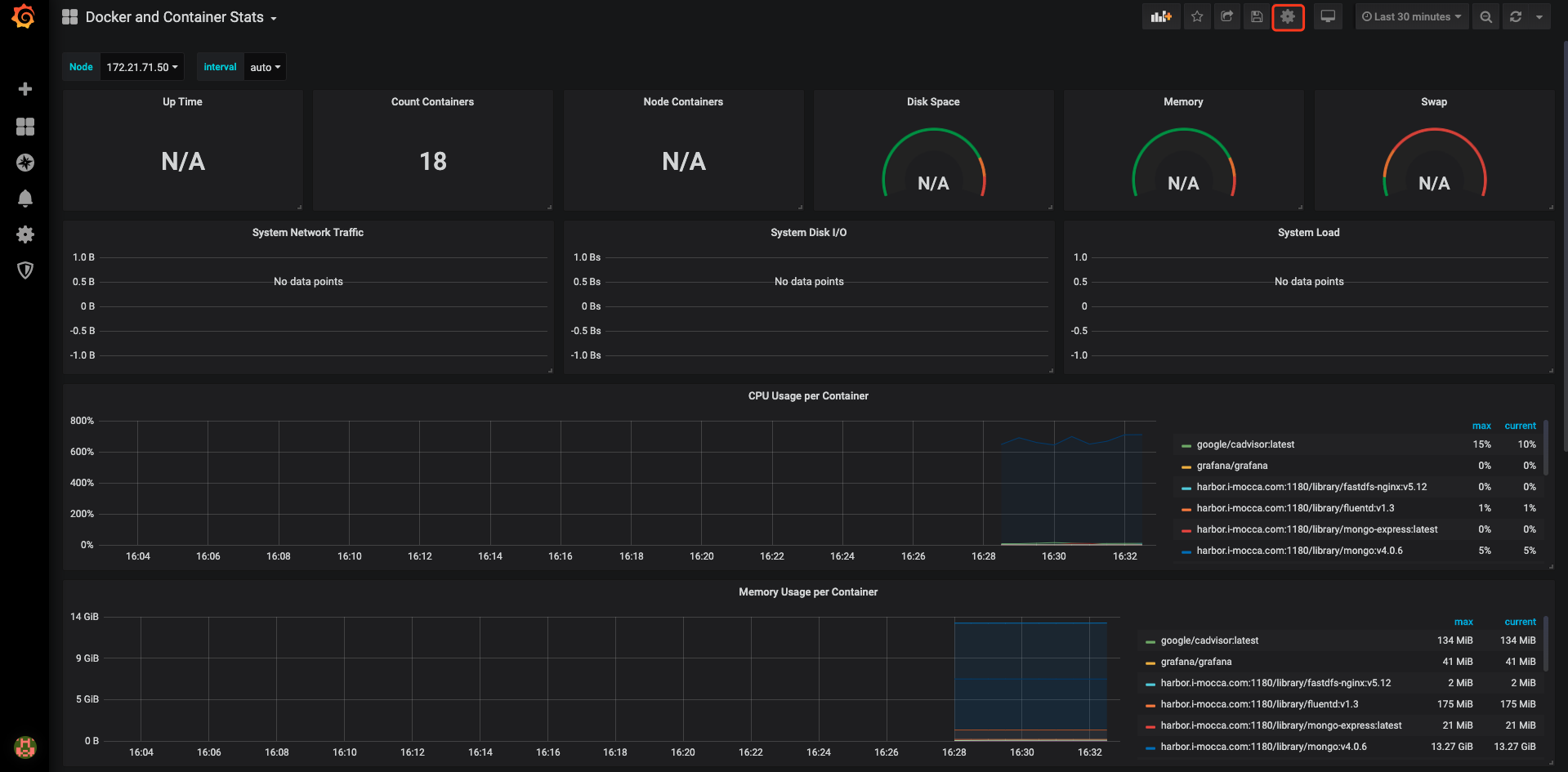
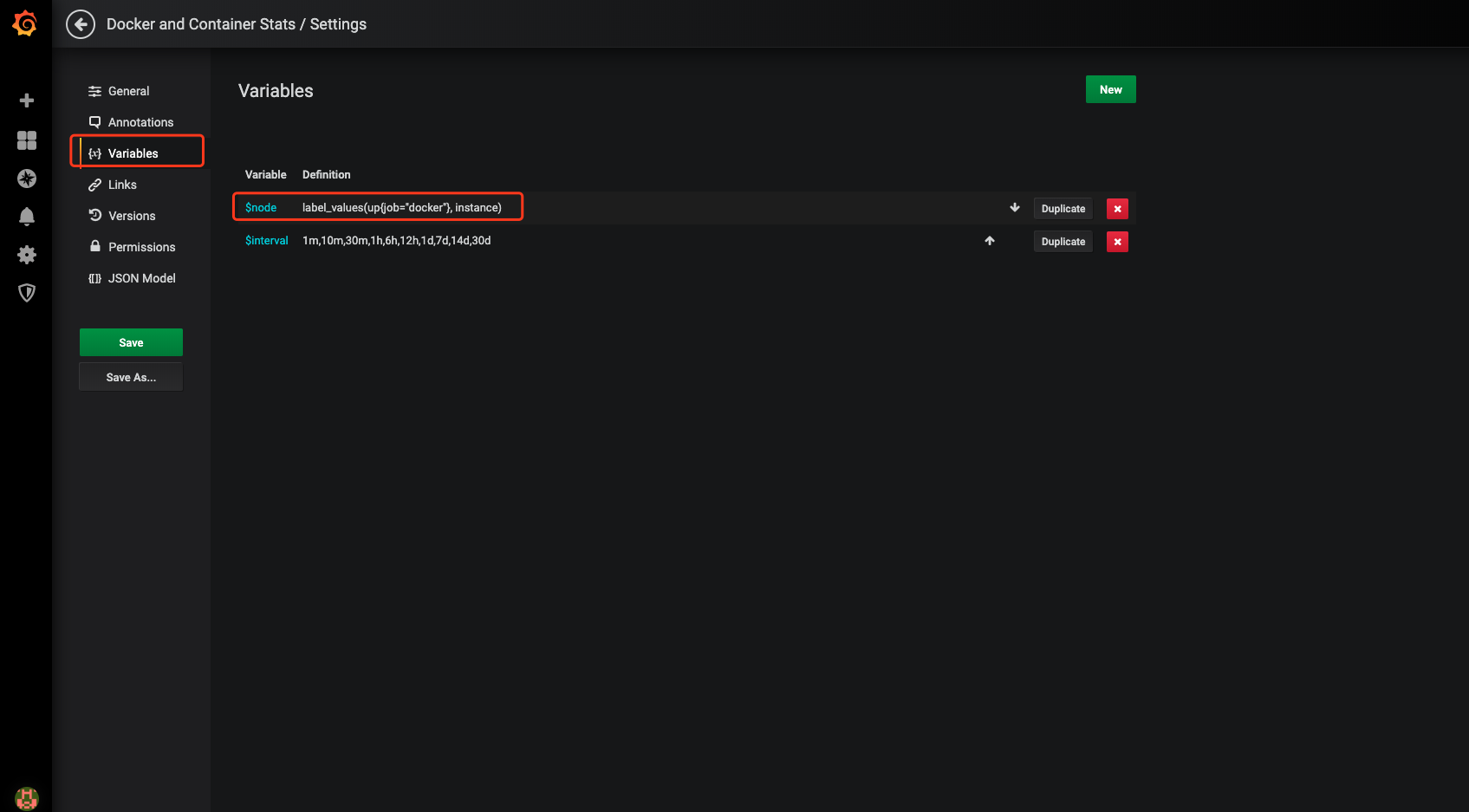
修改成我这个样子即可(在你对它不是很了解之前,按照文档的做下去,再变通)
如果一切顺畅,那么就会出现下图这样
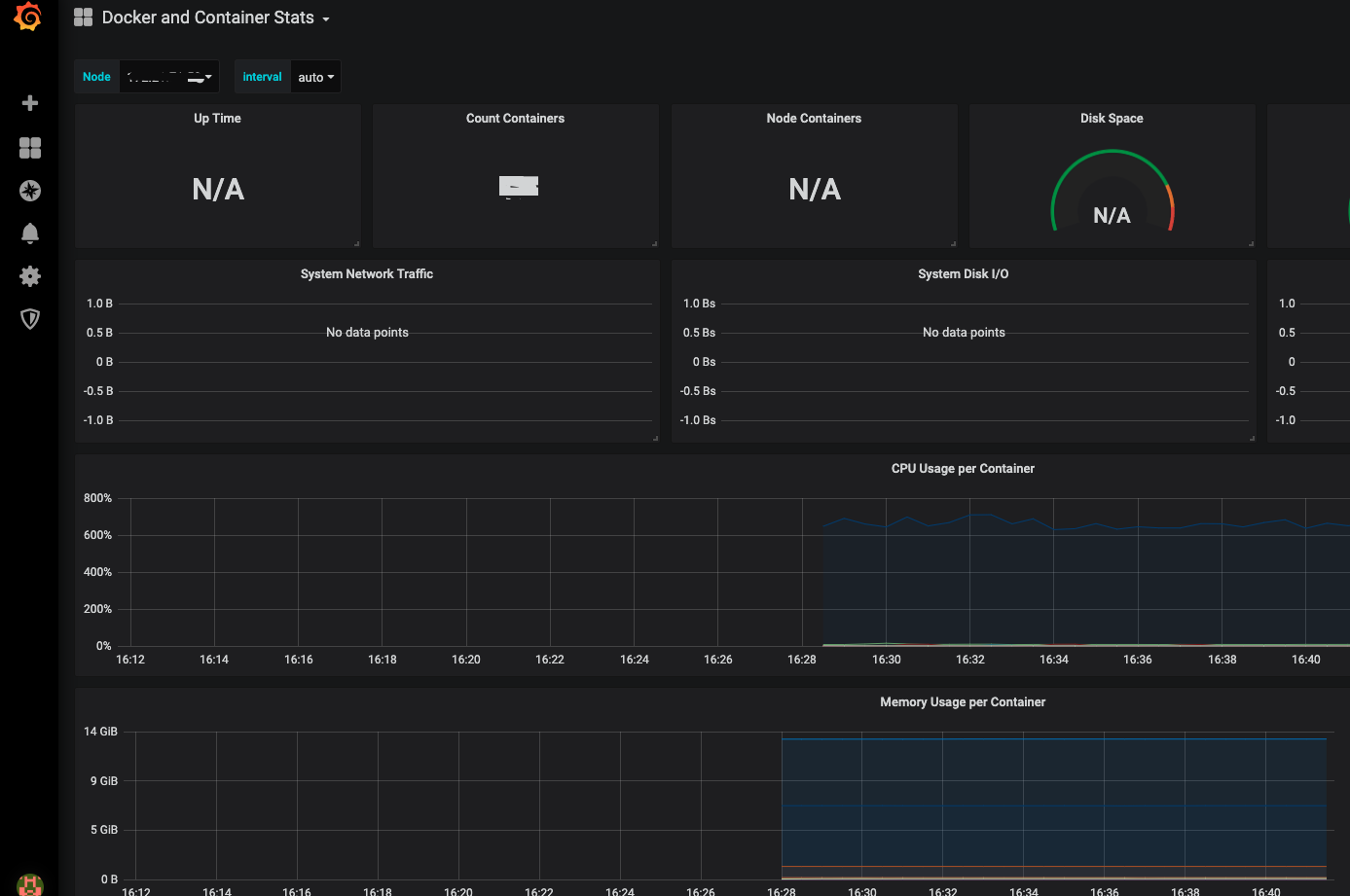
现在这个程度还不行,因为版本的问题,因为该模板不是基于最新版Node_exporter开发,有些值并不适用,我们需要修改对应的值,具体我们也可以通过Prometheus查询界面确定value值。
- 部署alertmanager实现报警功能
$ docker pull prom/alertmanager(linuxtips/alertmanager_alpine)
#拉取alertmanager镜像
$ cat /usr/local/prometheus/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receivers: ying.qiao
receivers:
- name: 'ying.qiao'
webhook_configs:
- url: 'https://hook.bearychat.com/=bwD9B/prometheus/2e31f72d81f31d322db49e85d22e1cee'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
prometheus添加告警规则
$ sudo mkdir /usr/local/prometheus/rules
$ sudo vim /usr/local/prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: InstanceDown ## alert名称
expr: up{job='node'} == 0 ## 报警条件
for: 1m ## 超过1分钟,prometheus会把报警信息发送至alertmanger
labels:
severity: "warning"
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
这里有一个很坑的问题,花括号里的job后面那个node,必须要和在prometheus.yml里定义的job名称严格一致
$ sudo vim /usr/local/prometheus/file/prometheus.yml
rule_files:
- /usr/local/prometheus/rules/node_alerts.yml
#指定对应的规则文件
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.21.71.50:9093 ## alertmanager服务地址
## 添加prometheus对alertmanager服务的监控
#以上配置文件,注意下添加的位置
- job_name: 'alertmanager'
static_configs:
- targets: ['172.21.71.50:9093']
重启prometheus,并启动alertmanager
$ docker rm -f c1473106d0f0
$ docker run -d -p 9090:9090
-v /usr/local/prometheus/file/prometheus.yml:/usr/local/prometheus/file/prometheus.yml
-v "/usr/local/prometheus/file/alertmanager_rules.yml:/usr/local/prometheus/file/alertmanager_rules.yml:ro"
prom/prometheus
--config.file=/usr/local/prometheus/file/prometheus.yml
--web.enable-lifecycle
$ docker run -d -p 9093:9093
-v /usr/local/prometheus/alertmanager/:/usr/local/prometheus/alertmanager/
-v /var/lib/alertmanager:/alertmanager
--name alertmanager prom/alertmanager
--config.file="/usr/local/prometheus/alertmanager/alertmanager.yml"
--storage.path=/alertmanager