一个对象是否是线程安全的,取决于它是否被多个线程访问。要是的对象是线程安全的,需要采用同步机制来协同对对象可变状态的访问。当一个线程访问某个状态变量并且其中有一个或多个线程执行写入操作时,必须采用同步机制来协同这些线程对变量的访问。Java中的主要同步机制是关键字synchronized。
如果当多个线程访问同一个可变的状态变量时,没有使用合适的同步机制,那么程序就会出错误。有三种方式可以修复这个问题
- 不再线程之间共享改状态变量
- 将状态变量修改为不可变的
- 在访问状态变量时使用同步
当然刚才说的三个办法,其实前两个方法都是通过解决不了需求,就去解决提出需求的人的方式去搞定的线程不安全的问题。事实上,我们大部分的工作中都是希望我们通过第三种方案来解决线程不安全的问题。
这里我想额外插一句话,也是我觉得是在学习多线程过程中非常重要的一种编程方式:
首先使代码正确运行,然后再提高代码的速度。
也就是说如果你的代码逻辑运算结果和希望的有误差,你再多的使用多线程去提高速度也是没有意义的。就像是我们上学的时候去考试,考120分钟,结果你十分钟就交卷了,但是卷子上都是错误答案一样,这样做是没有意义的,也是不得分的。
好了,我们言归正传,说说我们本文中的主角synchronized。
synchronized是Java语言提供的一种内置的锁机制。每个Java对象可以用作一个实现同步的锁,线程再进入同步代码块之前会获得锁,并且在推出同步代码的时候释放锁。Java的内置锁相当于一种互斥体,它意味着最多有一个线程能够持有这种锁。而synchronized可以用来保证synchronized代码块中的代码的原子性、对共享变量修改后的可见性、代码块执行的顺序性。
如何保证原子性
synchronized加锁的原理,说白了就是在进入加锁代码块的时候,加一个monitorenter的指令,然后针对锁对象关联的monitor累加计数器,同时表示自己这个线程占有了这个锁。
举个例子:
MyObject lock = new MyObject();
synchronized(lock){
// 业务代码
}
可能很多现成的都需要执行这一段代码,这里的逻辑其实是这这样的是这样的,其实所有的线程都是对lock对象进行尝试加锁。这个时候执行了monitorenter指令,尝试对其进行加锁。执行释放锁的时候,执行monitorexist指令,递减计数器。如果计数器的值为0,就标志当前线程不持有锁,释放锁了。
这里需要深入分析一下,synchronized的加锁底层原理。
每一个对象的实例中,都包含两个内容:
- 对象头
- 实例变量
其中对象头中包含MarkWord和ClassMetaDataAddress两个属性。ClassMetaDataAddress就是一个指针,指向了这个对象对应的类信息的地址。
而MarkWord中就有许多对象中有意思的数据,如:hashCode、monitor、GC数据等等。这里我们需要说的就是monitor,这个东西其实本质上也是一个指针,指向了objectMonitor对象,这个对象中包含以下几个重要的属性:entrylist、count、owner、waitset
其中entrylist是多个线程都希望获取锁的时候,都再这里等待,具体是通过CAS来修改count值的方式来确定谁获取到了锁。
count的默认值为0,所以成功将count修改成为1的线程就是获取到所得线程。由于CAS,这个时候其他线程尝试修改count都会失败,然后触发重试。
加锁成功后的线程,会将owner的值指向自己。
如果获取到锁的线程执行wait指令,会释放锁,然后将自己放入objectMonitor对象的waitset中去,直到其他线程获取到锁,然后执行notifyall,将waitset中的所有线程释放,然后这些线程会重新加入entrylist尝试获取锁。
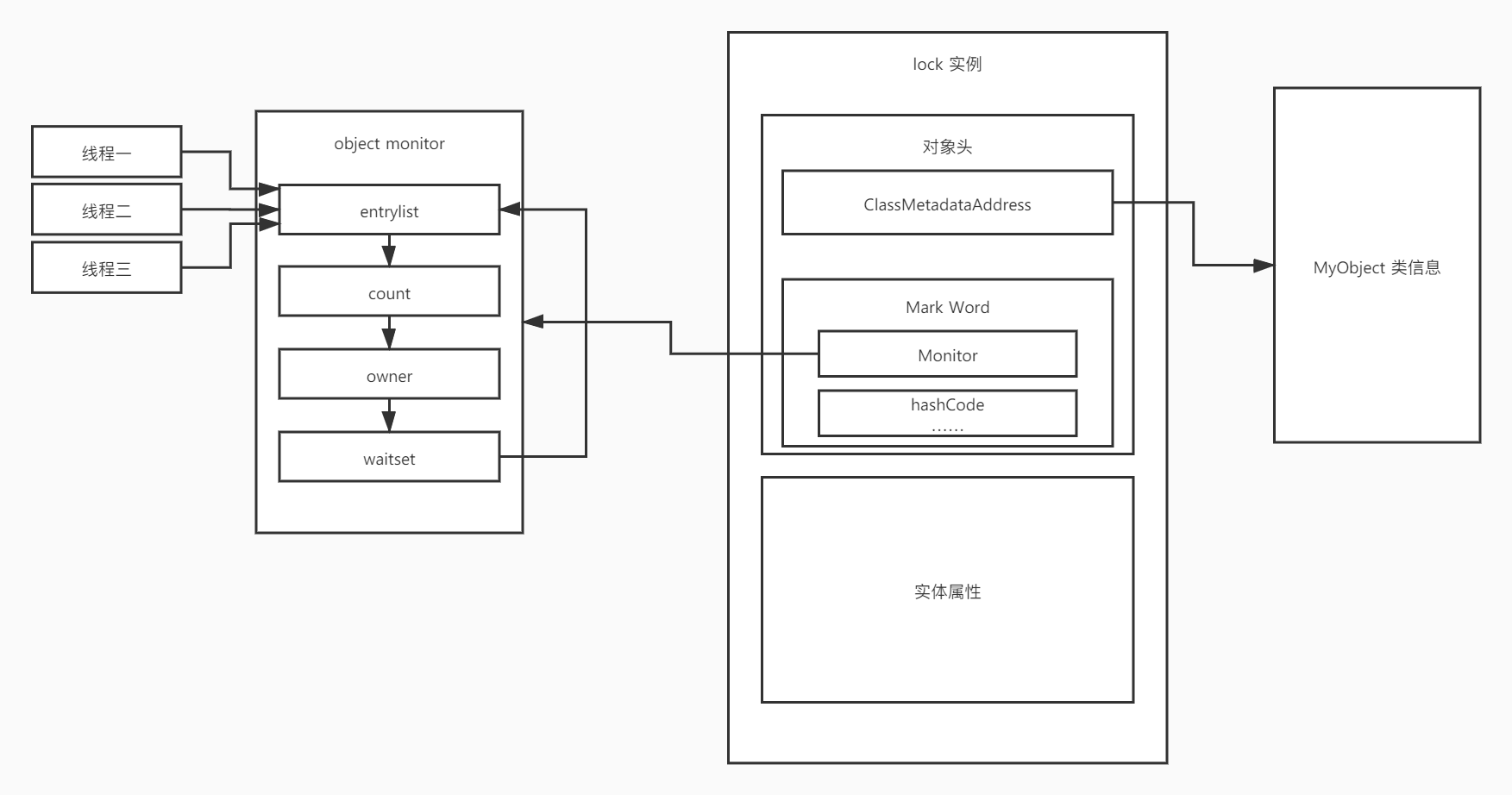
简单梳理一下流程:
- 从lock对象的对象头信息中,查看monitor指针指向的objectmonitor对象。
- 加入objectmonitor对象的entrylist列表
- 尝试修改count计数器,默认是0,这里是CAS机制,如果原始值不是0会继续重试,换句话说,其实哪个线程成功修改了count计数器,就可以说开始持有锁了
- 将owner指针指向自己线程
- 开始执行业务代码
- 如果还需要继续加锁(重入锁),count++
- 如果释放锁,count--
- 如果count == 0了,就算是完全释放锁了。
- 有一个特殊情况,如果线程执行了wait的话,那么它会释放锁,然后将自己放入到waitset中,从而不参与线程的竞争机制了。直到某个线程执行了notifyAll将waitset中的所有线程释放出来,这个时候这些线程会再进入entrylist里面尝试竞争获取锁
如何保证可见性和有序性
synchronized对可见性的保证,本质上还是通过load、store内存屏障实现的。
如果对可见性、有序性问题不了解,可以看一下我之前梳理的多线程知识梳理(1):当我们谈到指令乱序的时候,在谈什么?
这里我们再谈两个指令:
- refresh:从高速缓存、主内存中获取最新的数据
- flush:将修改的数据,不要仅仅存储到写缓存器中,更要冲刷到高速缓存或者主内存中
所谓load内存屏障本质上就是执行refresh指令,store就是执行flush指令。
那synchronized是如何,或者说什么时候使用的load和store内存屏障呢?
答案:再执行monitorenter和monitorexist的时候。具体表现是,在monitorenter加速的时候,在monitorenter之后会执行load指令,使当前cpu核心从高速缓存和主内存中获取数据,以保来保证synchronized代码块中的值是最新的,在执行monitorexit之后,会执行store内存屏障,将代码快中的值的变量刷入高速缓存或者主内存中
那synchronized关键字是如何保证有序性的呢?其实synchronized关键字并不能保证它包裹的代码块中的代码一定是有序执行的。
但是它可以用来保证synchronized关键字修饰的代码块和它前后的代码块是顺序执行的。
例如:
int a = x*y;
synchronized(lock){
// 需要加锁处理的业务逻辑
}
int b = a* y;
像这样的代码,synchronized并不能保证需要加锁处理的业务逻辑(如果有多行),一定是按照代码顺序执行的,但是它一定能保证这段代码是在int a赋值完成之后,int b赋值开始之前执行。
那它的具体原理是如何实现的呢?
synchronized关键字在开始和结束的时候,不仅仅会执行load指令和store指令。还会执行acquire内存屏障和release内存屏障。
- acquire内存屏障,用来保证acquire后的读写操作不会发生在acquire动作之前。
- release内存屏障,用来保证release之前的读写操作不会发生在release动作之后。
所以sychronized关键字代码块具体是这样的:
synchronized(obj){ ----> monitorenter
load 内存屏障 (用来获取最新变量的值)
acquire 内存屏障(保证前面的synchronized前面的代码执行完毕)
// 从这里开始才是我们写的业务代码
release 内存屏障(保证synchronized结束之前,所有的业务代码执行完毕)
} ----> monitorexist
store 内存屏障(保证synchronized关键字修饰的代码块中对共享的变量的值的修改,能够刷入主内存或高速缓存中,保证其他CPU核可以感知到)