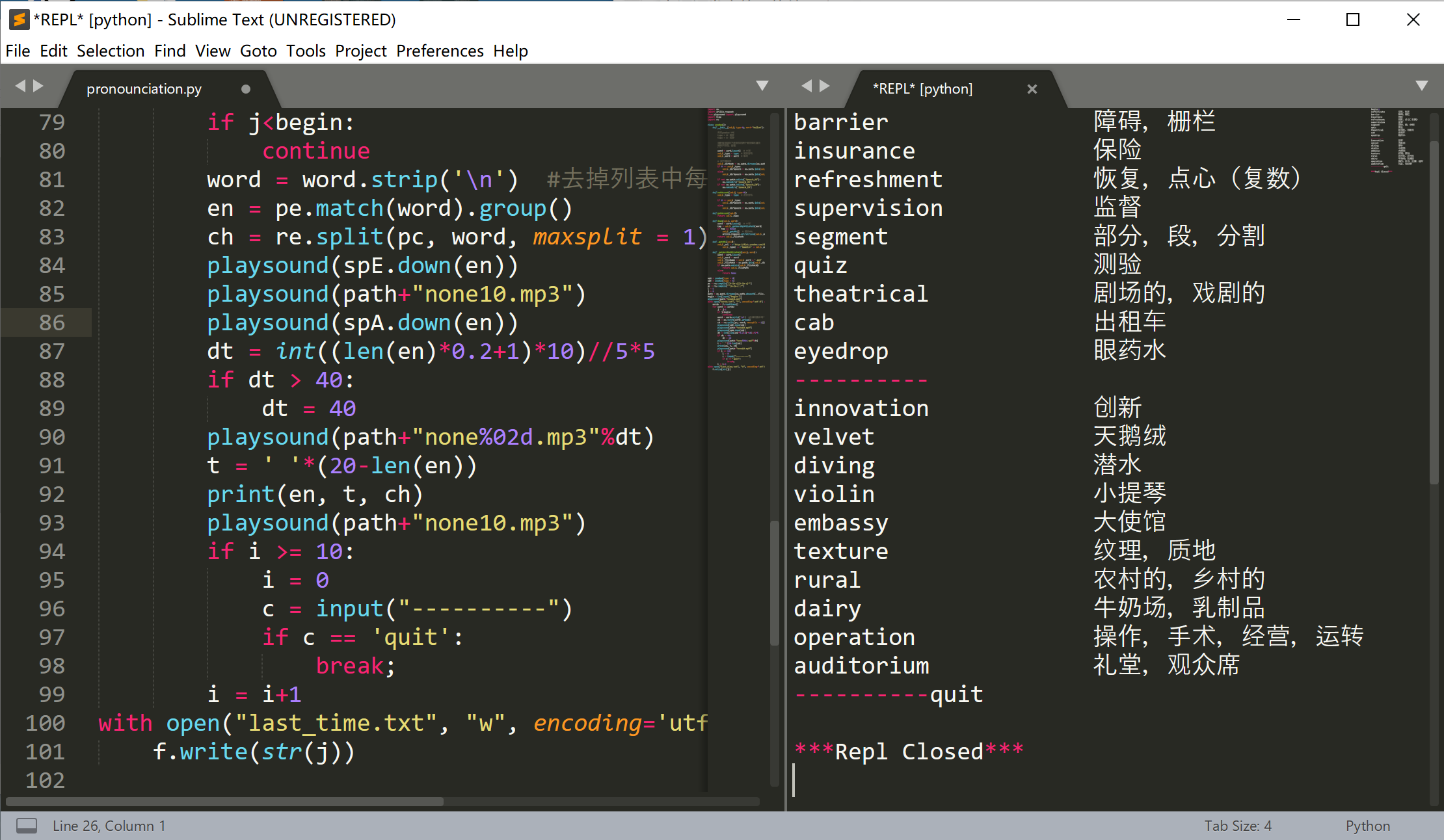
最近背诵雅思听力词汇时资料没有附带音频,为了方便练习,写个程序利用有道API自动获取并播放单词发音播放完后会停顿,方便听写练习,开始时输入起始位置,出现“--------”时直接回车继续练习,输入”quit“退出练习并保存最近播放位置。
import os
import urllib.request
from playsound import playsound
import time
import re
class youdao():
def __init__(self, type=0, word='hellow'):
'''
调用youdao API
type = 0:美音
type = 1:英音
判断当前目录下是否存在两个语音库的目录
如果不存在,创建
'''
word = word.lower() # 小写
self._type = type # 发音方式
self._word = word # 单词
# 文件根目录
self._dirRoot = os.path.dirname(os.path.abspath(__file__))
if 0 == self._type:
self._dirSpeech = os.path.join(self._dirRoot, 'Speech_US') # 美音库
else:
self._dirSpeech = os.path.join(self._dirRoot, 'Speech_EN') # 英音库
if not os.path.exists('Speech_US'):
os.makedirs('Speech_US')
if not os.path.exists('Speech_EN'):
os.makedirs('Speech_EN')
def setAccent(self, type=0):
self._type = type # 发音方式
if 0 == self._type:
self._dirSpeech = os.path.join(self._dirRoot, 'Speech_US') # 美音库
else:
self._dirSpeech = os.path.join(self._dirRoot, 'Speech_EN') # 英音库
def getAccent(self):
return self._type
def down(self, word):
word = word.lower() # 小写
tmp = self._getWordMp3FilePath(word)
if tmp is None:
self._getURL() # 组合URL
urllib.request.urlretrieve(self._url, filename=self._filePath)
return self._filePath
def _getURL(self):
self._url = r'http://dict.youdao.com/dictvoice?type=' + str(
self._type) + r'&audio=' + self._word
def _getWordMp3FilePath(self, word):
word = word.lower()
self._word = word
self._fileName = self._word + '.mp3'
self._filePath = os.path.join(self._dirSpeech, self._fileName)
if os.path.exists(self._filePath):
return self._filePath
else:
return None
spA = youdao(type = 0)
spE = youdao(type = 1)
pe = re.compile('[A-Za-z][A-Za-z]*')
pc = re.compile('^[A-Za-z ]*')
i = 1
j = 0
path = os.path.dirname(os.path.abspath(__file__))+"\none\"
begin = int(input("begin:"))
playsound(path+"none10.mp3")
with open("words.txt", "r", encoding='utf-8') as f:
words = f.readlines()
for word in words:
j = j+1
if j<begin:
continue
word = word.strip('
')
en = pe.match(word).group()
ch = re.split(pc, word, maxsplit = 1)[1]
playsound(spE.down(en))
playsound(path+"none10.mp3")
playsound(spA.down(en))
dt = int((len(en)*0.2+1)*10)//5*5
if dt > 40:
dt = 40
playsound(path+"none%02d.mp3"%dt)
t = ' '*(20-len(en))
print(en, t, ch)
playsound(path+"none10.mp3")
if i >= 10:
i = 0
c = input("----------")
if c == 'quit':
break;
i = i+1
with open("last_time.txt", "w", encoding='utf-8') as f:
f.write(str(j))